
本文介绍了高效进行互联网论文/书籍研究的高级技巧与窍门,并辅以真实案例。
久而久之,我在网上查找参考文献、论文和书籍方面,练就了一身高超的谷歌搜索技巧和专业能力。我将从布尔查询和键盘快捷键等标准技巧讲起,逐步介绍搜索、针对高难度目标调整搜索、突破付费墙、请求「越狱」、扫描书籍、监控主题和托管文档的整个流程。其中一些技巧鲜为人知,例如通过互联网档案馆(IA)查阅书籍。
我试图将我的搜索工作流程记录下来,并就如何发现与托管文档分享一些通用建议,同时提供示范性的案例研究。
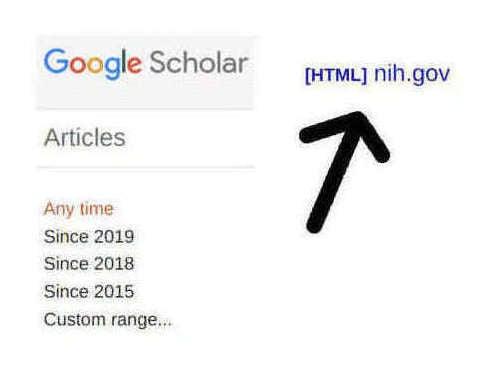
谷歌学术搜索结果截图,图中箭头指向了许多用户都不知道的、非常有用的全文链接。
高超的谷歌搜索技巧是我自小学起就引以为傲的技能。那时,图书管理员让全班同学比赛查年鉴,赢的常常是我。我至今仍清晰地记得,在高中时我恍然大悟的那个瞬间——我余生的很大部分时间,都将与搜索、付费墙和失效链接打交道。互联网是史上最伟大的信息宝库,对有好奇心的人来说,它就是一个取之不尽、用之不竭的聚宝盆。因此,每当看到许多人浅尝辄止地一搜便无功而返,甚至压根不去尝试,我便感到惋惜。对大多数人而言,如果在谷歌或谷歌学术的第一条结果里找不到,那它就等同于不存在。在下文中,我将倾囊相授我最得意的互联网搜索技巧,并勾勒出一幅在线搜索的流程图,以阐释那些精妙的技巧和只可意会的搜索神技。
概括来说,我们首先需要合适的工具来创造搜索的机会:若是完全避免搜索,我们就无法精通搜索。其次,每次搜索都会因搜索引擎和媒介类型的不同而有所差异——它们各有各的脾性、盲区和补救失败搜索的方法。我们常常会碰壁,而每一种壁垒都有相应的破解之道。但是,当我们找到了资料,事情还没完:如果我们不设法确保它永久可寻,那将是愚蠢且短视的。最后,我们或许还会对一些高级主题感兴趣,例如如何预先确保资源在未来需要时依然可用,或是如何发现那些我们可能想要进一步探索的新事物。为了阐明整个工作流程并展示那些只可意会的知识,我收录了许多搜寻「硬骨头」资料的互联网案例研究。
1 论文
1.1 搜索
1.1.1 准备工作
「寻觅,必获。」
——乔尔乔·瓦萨里,《马西亚诺之战》
无需尝试,只管去做。你必须做的第一件事,就是养成一有问题就去搜索的习惯:「谷歌是你的好帮手。」唯一保证会失败的搜索,就是你从未发起的搜索。(要警惕那些微不足道的麻烦!)
- 掌握查询语法
你需要了解基本的布尔运算符及关键的谷歌搜索运算符(完整列表):用双引号进行精确匹配,用连字符表示否定/排除,用site:在特定网站或其特定目录下搜索(例如,foo site:gwern.net/doc/genetics/,或排除特定目录foo site:gwern.net -site:gwern.net/doc/)。你或许也想试试高级搜索页面,来了解它都能实现些什么功能。(谷歌还有更多搜索运算符(Russell 的说明),但它们不见得值得学习,因为其功能过于冷门,而且大部分似乎都有缺陷^[例如,info:运算符就毫无用处。而link:运算符,在我近十年偶尔试用的经历中,返回的我的网站的链接数量,远不及谷歌网站管理员工具里的入站链接数,而且它似乎在某个时间点被彻底禁用了。]。)
- 热键快捷方式(强烈推荐)
启用某种形式的热键搜索功能,使其既能弹出输入框,也能直接搜索剪贴板中复制的内容,从而将使用谷歌(G)、谷歌学术(GS)、维基百科(WP)搜索变成一种条件反射。^[维基百科因其日益狭隘的信源和预印本政策,正变得越来越过时和缺乏代表性,这是其整体删除主义衰败的一部分,因此它并非查找参考文献的好去处。不过,用它来查找关键术语还是不错的。] 你应该能在好奇心萌生的一瞬间,仅凭几次按键就本能地发起搜索。(如果你在用 IRC 聊天时使用此功能,速度快到对方都察觉不到你的停顿,那才算足够快。)
工具示例:AutoHotkey(Windows),Quicksilver(Mac),xclip+Surfraw/StumpWM 的search-engines/XMonad 的Actions.Search/Prompt.Shell(Linux)。DuckDuckGo 提供了 「bangs」 功能,这是一种引擎内的特殊搜索(多数等同于谷歌的site:搜索),其用法类似,也可与输入框、宏或热键结合使用。
我个人就重度使用我编写的 XMonad 热键,它为我提供了窗口管理器级别的快捷方式:在任何程序中,我只需选中一段标题文本,按下Super-shift-y,就能立刻在新的 Firefox 标签页中用谷歌学术搜索选中的内容;如果我想编辑标题(比如加上作者姓氏、年份或关键词),则可以按下Super-y调出输入框,用C-y粘贴内容,编辑后再按回车键启动搜索。可想而知,这在需要大量或连续搜索论文时极为便利。(浏览器本身也有类似快捷键,但我不太喜欢,因为它们只在浏览器窗口内生效,通常需要更多按键或鼠标操作,并且一般不支持热键或直接搜索剪贴板内容:Firefox、Chrome)
- 网页浏览器热键
为了在搜索结果和不同条目间自如跳转,你应该熟练掌控你的标签页浏览器。你需要能够随时定位到地址栏、在标签页间左右切换、关闭标签页、打开新的空白页、恢复刚关闭的页面,以及直接跳转到第n个标签页等等。(在 Windows/Linux 版的 Firefox/Chrome 中,这些操作对应的快捷键分别是:C-l、C-PgUp/C-PgDwn、C-w、C-t/C-T和M-[1–9]。)
1.1.2 执行搜索
当你(大概率是在谷歌学术上)发起搜索后,就需要浏览它的搜索结果了。对于谷歌学术,操作通常很简单,只需点击右上角的 [PDF] 或 [HTML] 链接,这代表了(谷歌学术认为的)全文链接,例如:
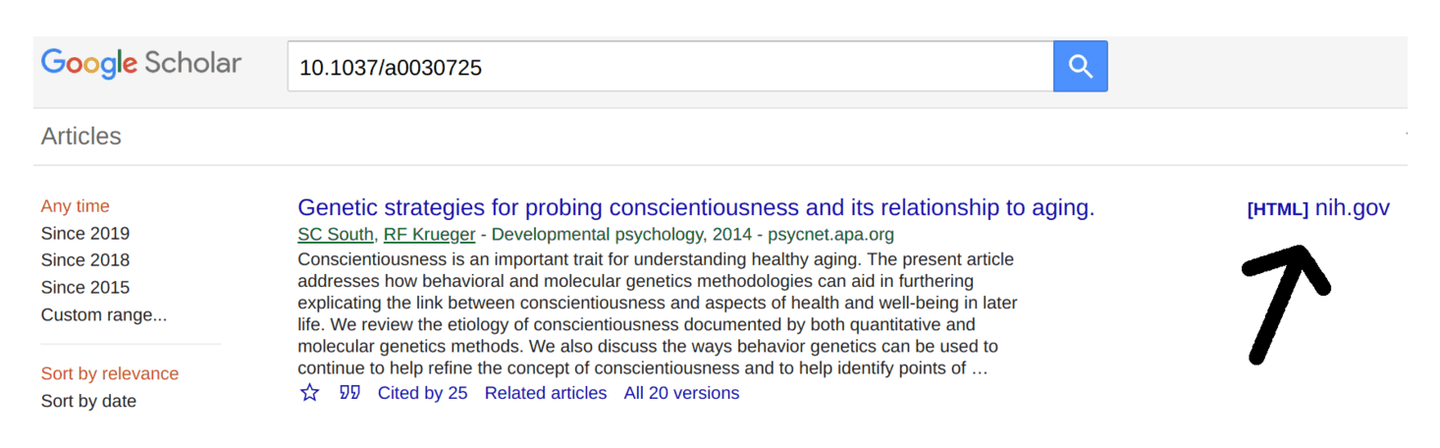
谷歌学术搜索结果示例:请注意 [HTML] 链接,它表明这篇论文有可供全文阅读的 Pubmed 版本(新手常常会忽略这一点)。谷歌学术:如果右上角没有全文链接,那就留意是否存在「软性壁垒」。记住,在谷歌学术中,全文链接并不总是以 [PDF] 的形式出现!请手动检查排名最前的几条结果:它们常常设有「软性壁垒」,即网站会屏蔽网络爬虫,但仍然允许你下载全文(可能需要费一番周折,比如 SSRN 网站)。
另外请注意,谷歌学术还支持其他实用功能,例如为特定搜索词设置提醒、为某篇论文的任何新引用设置提醒,以及反向引文搜索(用于追踪一篇论文的后续研究,寻找重复实验失败的案例或相关批评)。
1.1.2.1 深挖细掘
想找的资料可能不会立刻出现。人生就是如此,十有八九不会一帆风顺。^[我小时候以为,只要拿着一本书的唯一 ID,也就是 ISBN,去找图书馆的参考咨询员,他们就能帮我调来国会图书馆里的任何一本实体书;这听起来合情合理。但我一直没搞懂,那些科普书或报纸文章里引用的所谓「论文」到底该怎么弄到手——一篇论文究竟在哪儿?如果它发表在某本《论文期刊》上,我又该去哪儿找这本期刊?我那时的图书馆只订了几十种杂志,肯定没有《科学》、《自然》这些高大上的刊物。残酷的真相是:哪儿都找不到。论文没有统一的标识符(至今大多数论文仍没有 DOI),也没有中央数据库,更没有谁来负责——只有一个由零散的图书馆和废弃的网站构成的混乱拼凑体。所以,找书通常很容易,而找一篇论文却可能是一场长达数十年的漫漫征途,你可能需要深入到互联网档案馆的犄角旮旯,或者从那些雇佣黑客渗透私人数据库的、来路不明的中文网站上购买。]这时,你就得发挥点创意了:
- 标题搜索:如果论文全文没有出现在第一页,就要开始微调搜索词(这没有一定之规,需要你慢慢培养一种「机械通感」,并不断切换思路,既要像机器一样思考「它会如何分类」,也要像人一样思考「别人会如何描述」):
- 结果数量的黄金法则:搜索时切记,结果不能太多,也不能太少。在谷歌学术中,几百条结果大概是最佳平衡点。如果结果不足一页,说明你的搜索条件太苛刻了。
如果什么都搜不到,试试缩短标题。标题里的错误通常后半部分比前半部分多,而且人们也经常省略后半部分。所以,试着从标题末尾开始删减词语,以扩大搜索范围。想一想你自己在回忆标题时会犯哪些错:你会漏掉标点或副标题,用更熟悉的同义词替换,或者做其他简化。(OCR识别软件又可能会怎么搞砸一个标题呢?)
留意搜索结果的摘要或全文中,有哪些与你的查询词一同出现的专业术语。哪些术语看起来比你的更常用?或者,它们是否暗示你所用术语的常规含义与你的理解稍有偏差?你可能需要更换关键词。
如果删减了几个词后结果又变得铺天盖地,那就试试用否定运算符foo -bar来排除掉无关的大类结果,可以根据需要添加多个。另一个有用的技巧是用OR来加入可能的同义词,并用括号分组,以此在有限范围内扩大搜索。这可以玩得非常复杂,甚至近乎于黑客行为了——我有时会构造出(foo OR baz) AND (qux OR quux) -bar -garply -waldo -fred这样堪比巴洛克风格般繁复的搜索查询,直到触及搜索词长度上限和验证码的拦截。^[多数搜索引擎会把空格默认为AND,但我发现明确写出AND能帮助我确保搜索的正是自己所想的。](真到了那一步,就该考虑换个进攻路线了。) - 微调标题:给标题加上双引号;删掉所有副标题;反过来只用副标题搜索;警惕任何非字母和数字的字符,如果有冒号,把它拆成两个加了引号的短语(比如,不要搜
Foo bar: baz quux或"Foo bar: baz quux",而是搜"Foo bar" "baz quux");调换它们的顺序。
- 微调元数据:
- 添加或删除年份。
- 添加或删除第一作者的姓氏。试试在谷歌学术里只用作者来搜(
author:foo)。
- 删除特殊字符/标点:
Libgen 网站曾长期无法处理冒号,至今仍有很多网站有这个问题(比如 GoodReads);我不知道为什么冒号尤其麻烦,不过连字符、破折号以及各种引号、撇号、句号也同样问题多多。还要注意那些可能被空格隔开的单词——如果你想在 Libgen 上找阿尔帕德·埃洛的划时代著作《国际象棋棋手评级》(The Rating of Chessplayers),你就得搜 "The Rating of Chess Players" 才行!(这也再次说明了,当搜索碰壁时,转而按作者搜索是个好主意。) - 微调拼写:尝试英式/美式英语的别样拼法。虽说这本不该发生,但话说回来,我们本就不该需要手动删除冒号或标点符号。
- 检查是否已结集成书:许多论文并非发表在期刊上,而是收录在论文集里。所以,如果一篇论文神秘失踪,不妨找找看收录它的那本书。
一本书不一定会出现在谷歌学术里,因此其中收录的单篇论文自然也搜不到。同理,虽然 Sci-Hub 在将付费文章链接到 Libgen 里的对应书籍方面做得不错,但也远非万无一失。如果一篇论文发表在任何一种「会议论文集」、「会议」或「丛书」等带有 ISBN 号的出版物里,那么它很可能在常规渠道找不到,但收录它的那本书却唾手可得。当你为一篇论文搜寻得焦头烂额时,却发现收录它的书一直就摆在眼前,那感觉真是无比抓狂。(对于这种情况,我在找到之后环节的建议是,把相关的页码范围裁剪出来,单独上传这份论文,以方便后人查找。) - 利用 URL:如果你有某个网址,可以试试搜索其中的片段,通常是靠后的部分,并去掉日期和域名。
- 按日期搜索:
利用搜索引擎(如谷歌/谷歌学术)的日期范围功能(在「工具」里),设定一个前后 ±4 年的区间进行搜索。因为:元数据可能出错;出版界的惯例可能很奇特(比如,标为「六月」的杂志可能提前或推后好几个月才实际出版);出版商的动作可能极其缓慢。这一招尤其有效:你可以先设定一个日期限制,同时放宽关键词,这样就能在海量结果中筛选出与时间最相关的内容。如果这样还是没找到目标,或许能找到相关的讨论或修正后的引文,因为大多数文献都是在刚发表后被引用最多,随后便渐渐无人问津。
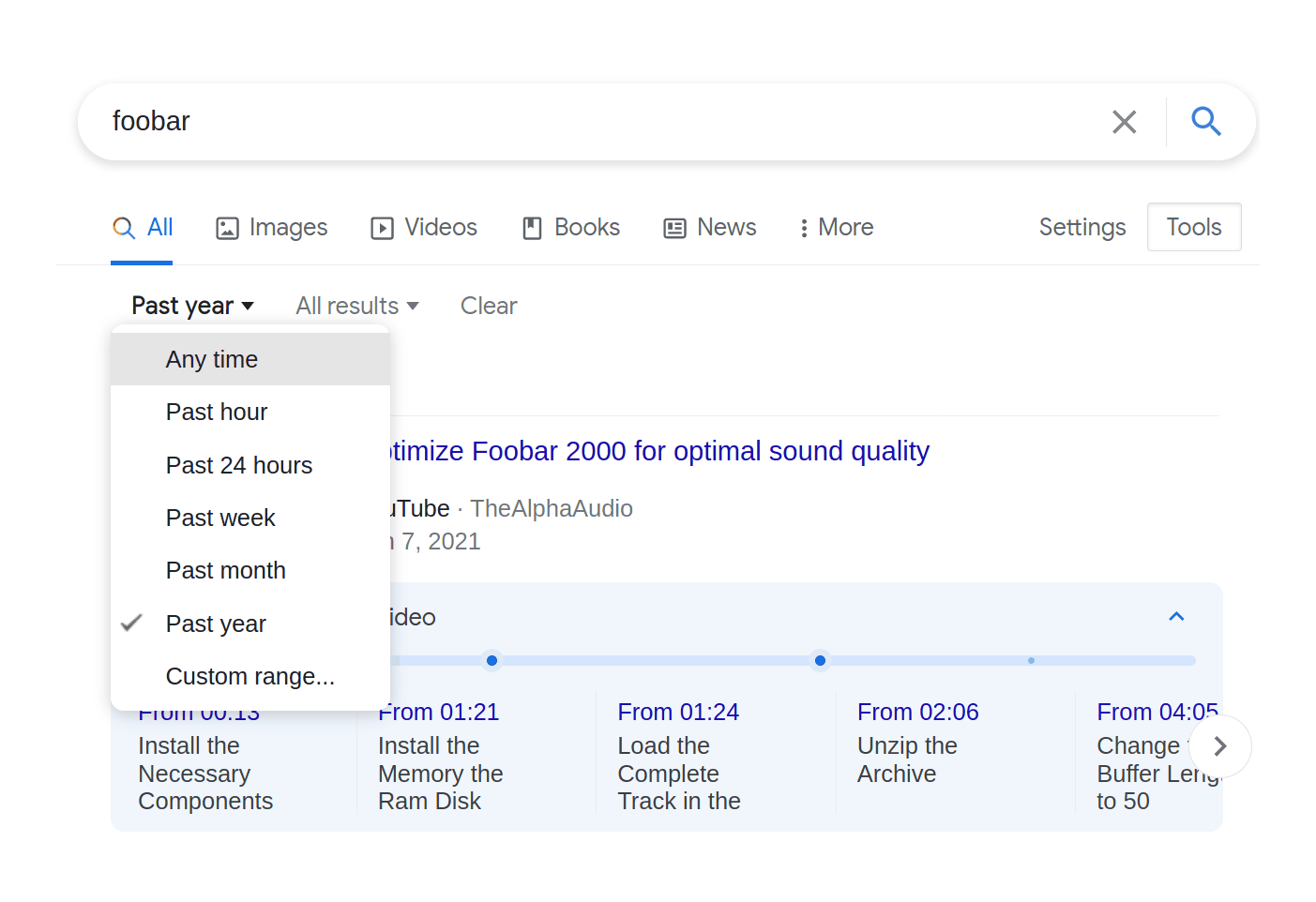
点击最右侧的「工具」,即可在谷歌搜索中使用日期范围和「精确」搜索模式。
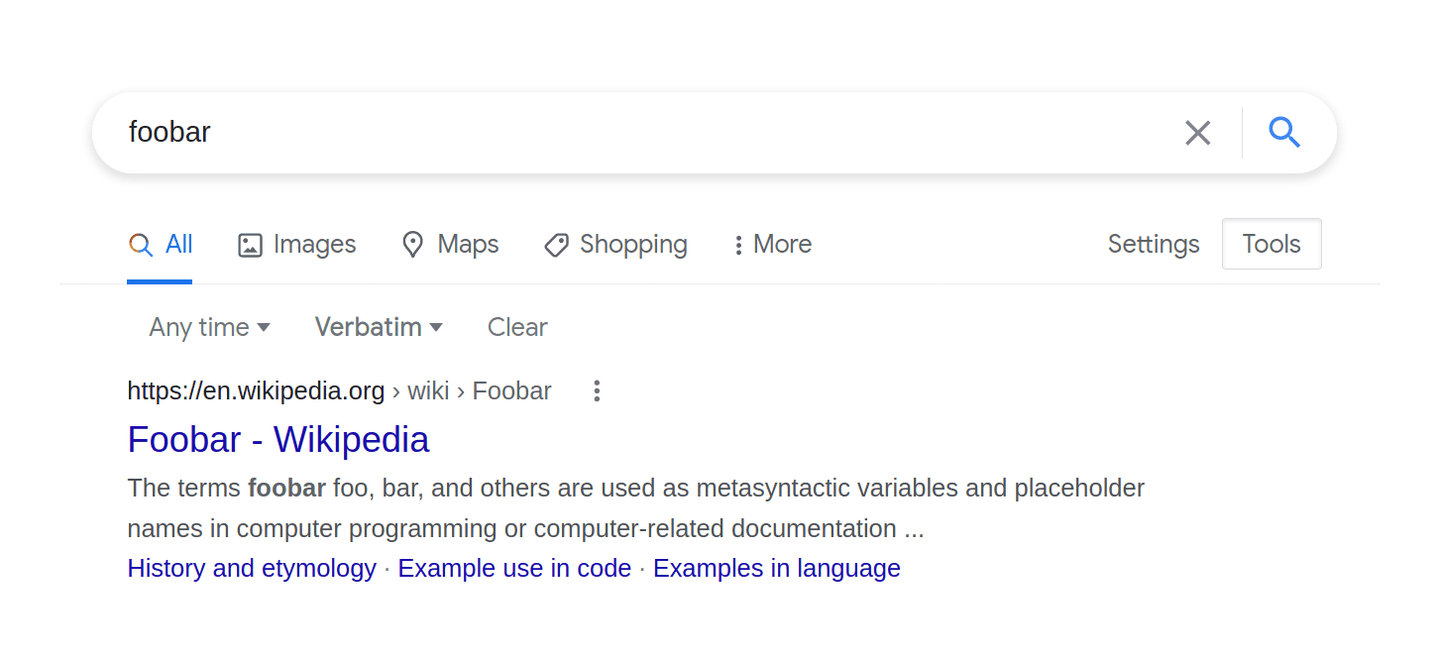
「精确」模式有助于强制进行更严格的字面匹配:若不开启,搜索「foobar」时,结果会固执地显示音乐播放器、招聘比赛等无关内容,而不是这个编程术语本身。
- 如果没有明确的年份,可以根据媒介类型来猜测:大众媒体有严重的「厚今薄古」倾向,只偏爱有时效性的「新闻」式研究;而学术出版物则会回溯更久远一些。参考文献的格式也能提供线索,暗示某项研究或文献的相对年代。通常,只要有作者的姓氏,并合理猜测某项研究是一两年前的,那么在谷歌学术里用「作者+日期范围+关键词」就足以找到这篇论文了。
- 考虑笔误:打字错误很常见。如果设定了具体日期,但在日期范围内却一无所获,那可能是元数据有笔误。即便是最细心的打字员,也难免会偶尔复制上一个条目的元数据,或把同一个字符连打两次,或颠倒两个字符的顺序。而对于数字,又没有拼写检查来帮忙纠错。学者们常常以讹传讹,传播错误的文献信息(这也顺便表明,他们很可能没读过原文,因此对原文的任何总结都应审慎看待)。想一想 QWERTY 键盘上可能出现的按键错位和临近按键误触:比如,年份「1976」实际上可能是 1966、1967、1975、1977 或 1986(但绝不可能是 1876、2976 或 1987)。如果你急匆匆地阅读或打字,你自己会犯哪些错误?哪些 OCR 识别错误最有可能发生,比如把「3」和「8」搞混?
- 添加行话:添加相关论文可能会用到的专业术语。例如,如果你在找一篇关于大学录取统计的文章,那么任何此类分析几乎肯定会用到逻辑回归;并且,即便文中没有明说「逻辑回归」(可能用了某个更精确但你猜不到的术语),也多半会用「赔率」(odds)来表示其影响。
如果你不知道该用什么行话,可能就得先退一步,去找一篇综述、一本教科书或一个维基百科页面,花点时间好好读一读。如果你用的术语从根本上就错了,那神仙也帮不了你。你可以花上几小时翻遍无数网页,但错误的术语永远也搜不出正确的结果。你可能需要通读各种概述性文章,直到最终辨认出你想要的东西,只不过它被冠以一个完全不同(而且通常相当晦涩)的名字。最令人沮-丧的莫过于,你明知某个主题(比如「科文定律」)肯定有大量文献,却因为它的叫法和你预想的完全不同而找不到——许多领域对同一概念或工具都有不同的命名。(偶尔会有人整理出「罗塞塔石碑」式的对照表来帮助跨领域翻译,例如:Baez & Stay 2009、Bertsekas 2018、Metz et al 2018 的表 1。这些资料都极其宝贵。) - 不起眼的网站也可能藏有宝藏:切勿草率地将「文献目录」(bibliographic)类网站视为无用——它们的内容可能比你想象的要多。
虽然像elibrary.ru这种以文献目录为中心的网站(几乎)总是没用,只会提供引文元数据而没有全文,徒增搜索结果的混乱,但我时不时会碰到一些奇特的外国网站(通常是印度或中国的),上面恰好有某本书或某篇论文的扫描件。(例如 Darlington 1954 这篇文献,我花了半个多小时都没找到,直到换了个思路去搜它所在的那卷期刊,在绝望中点进了一个印度的索引/图书馆网站……它居然就在那里。谁能想到呢。)所以,有时你必须逐一检查每条搜索结果,以防万一。 - 搜索互联网档案馆:
互联网档案馆(IA)值得特别一提,因为它是整个互联网的「阁楼」,塞满了从各种渠道扫描和上传的珍奇资料,简直要满溢出来——它不仅存档网页,还扫描大学馆藏,也接受来自民间档案员、黑客、狂热粉丝以及前面提到的那些更为开放的印度/中国图书馆的上传内容。^[IA 还将其馆藏内容的 OCR 文本开放给搜索引擎,这有助于谷歌发现它们——但代价是,你得学会在搜索结果片段中辨认「OCR 体」,这样才能在文本被 OCR 或排版弄得面目全非时,认出它就是你要找的内容。] 它的媒体收藏同样包罗万象——谁能想到这里竟有如此多的老科幻杂志(以及许多其他杂志)、数量近乎无穷的 Grateful Dead(感恩至死)乐队录音、原版114集的《猫和老鼠》,以及成千上万款街机、主机、个人电脑和 Flash 游戏(全都能在浏览器里直接玩)?互联网档案馆本身就是一个名副其实的互联网;当然,问题在于……如何在这里找到你想要的东西。
因此,常有这种情况:一本书明明可以在 IA 上找到,或者一篇论文就藏在某卷期刊的完整扫描件里,但 IA 的链接在搜索结果里排名很低,并且由于糟糕的 OCR,摘要片段也极具误导性。一个好的搜索策略是,去掉标题或引文的引号,然后用site:archive.org锁定该网站,再手动检查最前面的几条结果。(你也可以试试相对较新的「互联网档案馆学术搜索」,它收录的内容似乎比用谷歌站内搜索更全面。)
1.1.2.1.1 疑难杂症
如果基本技巧都毫无见效的迹象,那你就得动真格的了。你手头的标题可能完全是错的,或者文献被索引在另一个作者名下,或者根本没被直接索引,又或者藏在某个数据库的深处。以下是一些寻找文献的迂回战术:
- 追溯引文:查看谷歌学术的「相关文章」或「被引用」列表,可以找到相似的文章,比如某篇论文的后续版本,这些可能很有用。(如果你想确认「这项研究是否被重复过?」或者还在摸索该用什么专业术语来搜索,这些功能也同样值得了解。)
- 反常的搜索结果:留意那些暗示着隐藏文献关系的反常结果。
有没有某篇论文在搜索结果中排名很高,但看起来却风马牛不相及,比如摘要里根本不包含你的关键词?谷歌学术通常会降低那些只有文献目录条目的结果的权重。因此,如果在一个满是全文链接的页面里,一个纯目录条目赫然排在前面,你就该琢磨一下它为何被如此优先对待。谷歌图书(GB)也是同理:一本书可能被禁止显示任何内容片段,但排名却很高;这背后或许有充分的理由——它内部可能就藏着全文,或其他相关内容。
同样,你不能过于相信元数据。系统推断或文献声称的标题可能是错的,某个搜索结果很可能就是你想要的目标,只是它伪装了起来。 - 合集文件:有些论文可以通过搜索其所在的卷或书名来间接找到,特别是会议论文集或选集。许多论文表面上网上找不到,实际上只是被深埋在一个 500 页的 PDF 文件里,而谷歌的摘要片段又具有误导性。
会议论文的文献信息尤其复杂,你可能需要用上处理标题时的那些技巧:删掉部分信息,别死磕数字,要明白不同来源的作者、ISBN、或「标题:副标题」的顺序都可能不一样,等等。
PDF 页面是可链接的
技术小贴士:你可以通过在 URL 末尾加上#page=N来链接到任何 PDF 的第 N 页。(例如,这个链接会直接跳转到 Megatron 论文的第 13 页,那里有文本示例,而不是第一页。) - 按期号检索:另一种方法是查到某本期刊某一期的目录,然后手动一篇篇找。有时论文明明列在期刊的在线目录里,却偏偏在搜索引擎里销声匿迹(简直匪夷所思?!)。在某些极其刁钻的情况下,一篇论文可能已经被数字化并且可以获取,但由于错误被打包进了另一篇论文的文件里,或者仅仅是作为包含该期最后20页零散内容的「大杂烩」文件的一部分。在这种情况下,引文中的页码范围就特别有用了,因为它能显示出重叠的部分。你可以下载那些可疑的、页码重叠的「论文」,看看它们真正包含了什么。
这听起来可能很玄乎,但这类问题我碰到过不止一次。我曾徒劳地寻找 Shepard 1929 这篇文献存在的任何蛛丝马迹,一度半信半疑这是他 1959 年那篇文献的笔误,直到我翻出了原始的期刊扫描件才找到。一个堪称史诗级的例子是 Shockley 1966。我花了一个小时搜寻,除了零星的文献目录信息外一无所获,尽管它明确发表在《科学》这本大名鼎鼎、唾手可得且绝对已被数字化的期刊上——这让我百思不得其解。最后,我查阅了当期的目录,才推断出它被藏在了一组合集摘要里!^[这或许部分解释了为何没人引用那篇论文,而引用它的人显然也根本没读过。尽管它开创了种族混合分析法,这一方法在被后人重新发明后,已成为医学遗传学的主流方法之一。](「摘要」或「会议报告」这类问题的一个症状是:学术数据库声称有论文全文,但当你尝试访问时却神秘地报错。这显然是由于它们内部数据不一致,系统知道完整的期刊扫描件里有这篇文献,却不知道那篇独立的摘要「身在何处」。)还有一些 SMPY 项目的论文,结果是和期刊里相邻的文章被拆分或合并了,我只好手动把它们修复好。 - 硕士/博士论文:抱歉,这个……如果是 2000 年以前的,那基本就没戏了。你很可能找到引文甚至摘要,但想要全文?呵呵。
如果你有大学的代理服务器,或许能从 ProQuest(一个专注于美国学位论文的数据库)上搞到一份。如果 ProQuest 索引了某篇论文但不提供下载,这通常意味着他们有微缩胶卷/胶片的存档,但还没人付钱让它被扫描。你可以无需特殊许可直接注册,然后花大约 $43(2023 年价格)购买 ProQuest 的扫描服务,之后就能得到一个可下载的 PDF。(他们似乎只在接到请求后,才会去扫描那些堆积如山的非数字馆藏,这感觉就像在「赎回」论文。不过,这也意味着一旦你购买了扫描版,它就会进入 ProQuest 的数据库,供其他学术订阅者使用。)
否则,你就需要动用大学完整的馆际互借(ILL)服务了^[大学的馆际互借(ILL)特权,绝对是学生时代最被低估的福利之一,特别是如果你做任何研究或有阅读爱好的话——你几乎可以请求到 WorldCat 上能找到的任何东西,无论是一本极其冷门的古书,还是一篇 1950 年的硕士论文!这么好的服务,你凭什么不经常用它呢?!在我怀念的学生时代里,ILL 绝对名列前茅。]。但即便如此也未必管用(令人惊讶的是,许多大学似乎只对本校师生开放学位论文的访问权限,更麻烦的是,大多数论文都还储存在微缩胶卷上)。 - 反向图片搜索:如果资料里包含图片,用谷歌图片、TinEye 或 Yandex 搜索进行反向搜图,可能会找到重要线索。
Bellingcat 网站上有一篇由 Aric Toller 撰写的优秀指南:《如何使用反向图片搜索进行调查》。(Yandex 的图片搜索似乎利用了人脸识别、文字识别(OCR)等谷歌图片所不具备的功能,而且对版权问题的顾忌也更少。)
利用浏览器的「页面信息」功能绕过图片下载限制
如果你在某个设计糟糕或恶意阻止你下载图片的网页上遇到麻烦,可以试试「查看页面信息」(快捷键C-I)里的「媒体」标签页(示例)。它会列出页面上的所有图片,让你直接下载。 - 人为的阻碍:某个你确定应该存在的页面或主题,在谷歌或互联网档案馆里却搜不到?去检查一下网站的
robots.txt和站点地图。虽然robots.txt的作用已不如从前(因为动态页面用得越来越多,而且很多爬虫也无视它),但它有时仍是关键:某些重要 URL 可能被它排除在搜索结果之外,而过于严格的robots.txt甚至会导致互联网档案馆的存档出现巨大漏洞,并且可能无法修复(但至少你知道问题出在哪了)。
- 耐心:不是每道付费墙都能立刻翻越,论文可能有禁运期,代理服务器也可能不是随时可用。
如果某个东西现在找不到,可能过几个月就有了。用日历设置提醒,定期回来看看禁运的论文是否已开放,或者 Libgen/Sci-Hub 是否已收录,再决定是否需要采取手动请求等进一步措施。 - 针对特定领域的技巧:
- Twitter:Twitter 的内容会被谷歌索引,所以网页搜索可能能找到。但如果你知道任何元数据(如用户名、日期),用 Twitter 自带的搜索功能会更强大(尽管为了推销其价格高到离谱的「数据消防栓」和历史分析服务,Twitter 在很多方面限制了搜索)。使用 Twitter 的「高级搜索」界面,特别是
from:和to:这两个搜索运算符,可以极大地缩小搜索范围。(其他值得注意的运算符还有:list:、-filter:retweets、near:、url:和since:/until:。)
- 美国联邦法院:注册后,可以从 PACER 系统下载美国联邦法院的文档。它是按页收费的(每页 $0.10(2018 年价格)),但每季度消费低于一定额度(目前是 $15(2018 年价格))的用户可以免除费用。所以只要你小心使用,可能根本不用花钱。有一个名为 RECAP 的公共镜像网站,可以免费搜索和下载。如果在 RECAP 里找不到,必须去用 PACER(冷门案件通常如此),请务必安装 Firefox/Chrome 的 RECAP 浏览器插件,它会自动把你从 PACER 下载的所有内容都复制一份到 RECAP。(这非常方便,比如你日后发现当初下载的一份长篇 PDF 应该保留,或者想重新核对案卷时,就不用再花钱了。)
使用 PACER 可能很困难,因为它是一个老旧且高度专业化的系统,默认你是律师,或至少非常熟悉 PACER 和美国联邦法院系统。经验法则是,如果你要查特定案件,最好是搜索当事人的名字和姓氏(即使你知道案件 ID),把所有可能相关的刑事或民事案件都调出来。因为同一个人可能有多个案件,案件可能休眠多年、结案后又以新案号重开等等。找到最活跃或最相关的案件后,查看它的「案卷(docket)」,并勾选显示案件所有文件的选项。你会看到一个长长的文件列表,记录了案件的整个过程。其中大部分是法律流程文件,比如重新安排听证会或更换律师的通知。你要找的是篇幅最长的文件,那些最可能有价值。特别是「起诉书(indictment)」、「刑事诉状(criminal complaint)」^[诉状和起诉书不完全是一回事。起诉书通常细节不多,仅限于列出被告的罪名。而诉状的细节则要丰富得多。但有时两者只会有一个,可能是因为更详细的诉状被封存了(也许正是因为它太详细了)。],以及任何庭审证词的抄本。^[庭审证词可能长达数百页,会瞬间耗尽你的 PACER 季度预算,所以必须小心。特别是,庭审证词的定价系统非常有趣且备受争议,是一种与法庭速记员(他们可能是外包或自由职业者)工作方式相关的价格歧视体系,旨在确保覆盖转录成本:抄本刚出来时可能要价数百美元,目标是向律师、记者等急需者榨取最高价值。但一段时间后,PACER 会把价格降到合理水平。也就是说,第一份「原件」天价,后续的「复印件」就便宜多了。在美国联邦法院系统中,一份刚出炉的「原件」抄本每页花费可达<$7.25(2019 年价格),但第二个订购的人只需支付每页<$1.20(2019 年价格),之后的人则是每页<$0.90(2019 年价格),再过一段时间,价格会降到<$0.60(2019 年价格)(我相信几个月后,PACER 就只会按标准价每页 $0.10(2019 年价格)收费了)。所以,在 PACER 上查庭审记录,耐心能省大钱。] 那些一两页的短文件可能有用,但除非你对庭前谈判之类的具体细节感兴趣,否则价值不大。因此,在 PACER 上随手点击「全部下载」,很可能会白白花光你的季度预算,却得不到任何有用的东西(还可能干扰 RECAP 的上传)。
美国的州或县法院系统则没有这样的统一平台,它们各自为政,系统五花八门(通常还外包给私营公司,收费远高于 PACER),只能具体问题具体分析。(一则趣闻:根据 Nick Bilton 对「丝绸之路」一案的记述,FBI 和其他联邦机构在调查此案时,会故意将案件推向州法院而非联邦法院,以躲避 PACER 系统相对的透明度。然而,这种多系统操作有时也会反噬他们。例如在「丝绸之路 2.0」的 DoctorClu 一案中(详情见暗网市场被捕人员普查),地方警察的卷宗披露了他们使用黑客技术对 Tor 用户进行去匿名化,并牵扯出卡内基梅隆大学的 CERT 中心——这些细节在联邦的 PACER 文件中被姗姗来迟地抹去了。)
- 慈善机构财务:要查找美国慈善机构的财务文件,可以搜索
Form 990 site:charity.com,然后去 GuideStar 核实(例如查看女童子军的财报或《案例研究:阅读「优势」组织的财报》)。对于英国的慈善机构,英格兰和威尔士慈善委员会的网站可能会有帮助。
- 教育研究:任何与教育相关的内容,都可以尝试在 ERIC 网站内进行搜索。它有点像互联网档案馆,常常能找到在常规搜索结果中被埋没的全文资料。
- 惠康图书馆:惠康图书馆(Wellcome Library)收藏了许多在别处根本找不到的古旧期刊和书籍的扫描版。不幸的是,他们的网站搜索引擎优化(SEO)做得极差,PDF 文件又非要隐藏在需要点击同意的用户协议之后,导致它们在谷歌学术等常规渠道里根本不会出现。如果你在谷歌搜索结果中看到惠康图书馆的链接,一定要仔细点进去看看。
- 杂志(相对于学术或行业期刊)很难找。
Libgen/Sci-Hub 并不收录杂志,而是把这块外包给了 MagzDB,但后者的覆盖率很差。另一个替代选择是 pdf-giant。特别是2000年以前的杂志,往往只能去 eBay 上淘旧的二手实体刊。有些杂志比另一些好找——但如果我碰到一篇引用自《新科学家》的文章,我通常直接放弃,因为它从来都不值得我费那个劲。
- 报纸:和学位论文一样,很棘手。除了订阅 LexisNexis,我不知道还有什么通用的解决办法。^[我听说 LexisNexis 的终端有时会在联邦图书馆或法院等地向公众开放,但我自己没试过。] 对于美国报纸,一个有趣的资源是美国国会图书馆「记录美国」项目的「历史悠久的美国报纸」扫描件库。
1.1.2.2 根据引文或描述反向追查
如果你没有标题,只能靠引文或描述来搜索,那么可以尝试像微调标题一样,对搜索内容进行变换:
- 找最特别的句子:先从最简单的搜起——找那些看起来最令人印象深刻或最独特的句子。
- 短引文反而更独特:别搜索太长的段落。一两句话通常就足以构成近乎独一无二的特征,而且这有助于找到引用了不同片段的其他来源,而这些来源可能提供了更规范的引文信息。
- 拆分引文:因为即使是短语也可能独一无二,所以可以从一段长引文中拆出多个片段来搜索,特别是开头和结尾的部分,它们很可能与其他引用了上下文的来源重合。这对于追溯那些杜撰或讹传的名言至关重要,因为这些名言在流传中常常会删掉不够精辟的段落,同时又添油加醋。(一个极端的例子是奥利弗·亥维赛的那句名言。)
- 找古怪的用词:搜索那些异常具体或独特的词语,尤其是数字。三到四个关键词通常就够了。
- 留意转述:在原文中寻找那些看起来与你的目标引文同源的段落,特别是那些没头没脑地出现、又不像作者本人手笔的句子。作者通常不会每次引用都标注来源,往往只在第一次提及时标注,而在编辑过程中,这个「第一次」很可能被移到了文章后面。所有这些再次出现的内容,都值得你加入到搜索中。
- 找「顽强」的引文:你正在玩一场「传话游戏」,所以要找那些听起来独特、在反复传播中不易失真的句子和术语。
记忆就像是神经元之间传了几十年的都市传说。留意你自己记错事情的方式:你会通过简化、四舍五入到最简单的版本、以及添加本应该有的细节来扭曲它。因此,要避免搜索那些能被轻易替换的常用短语,因为人们凭记忆引用时总会改写,这会让你的精确搜索彻底失效。要牢记记忆的不可靠性和文本校勘学的基本原则:人们会用易于记忆的版本,来取代那个更晦涩的、更长的^[奇怪的是,在历史手稿的文本校勘学中,情况正好相反:版本越短,越接近原文。但对于记忆或转述,反而是越长越可信,因为人们在非逐字复述时,倾向于省略细节,将其变异成更上口的版本。],或不常见的原文。 - 微调拼写:当心标点和拼写差异导致你错失目标。
- 循着「劣化」的线索追踪:更长、不那么精辟的版本通常更接近原文,这表明你走对路了。版本越「烂」,线索越好。要追着更差劲的版本去嗅探线索。(作者们总是写不出他们本该写出的名言——正如棒球明星尤吉·贝拉所说:「我说的每句话,不都是我说的。」)
- 搜索书籍:切换到谷歌图书,祈祷有人转述或引用了你想找的内容,并附上了可靠的出处。如果你看不到全文或参考文献,就去 Libgen 上找那本书。
1.1.2.2.1 如何应对付费墙
金银离土,则不复归于土;无理而付诸尘土者,亦可有理而取之。当以丰碑华构饰逝者之骸,而非财货。生者之贸易,不应转于死者。取走无人怨其失落之物,并非不公;此物既无主,便无人因之受损。
——托马斯·布朗爵士 《瓮葬》
要找书或论文,就用 Sci-Hub/Libgen。付费墙通常可以用 Libgen(LG)或 Sci-Hub(SH)绕过:论文可以直接搜索(最好用 DOI^[简单来说,DOI 相当于「论文界的ISBN」;就是你常见到的那种用斜杠分隔的字母数字字符串,格式通常类似 10.000/abc.1234。(与 ISBN 不同,DOI 的标准非常宽松,唯一的硬性要求似乎就是必须包含一个 /,所以几乎任何字符串都能当 DOI,甚至包括 10.1890/0012-9658(2001)082[1655:SVITDB]2.0.CO;2 这种堪称可恨的真·DOI。)许多论文没有 DOI,或 DOI 是后来补发的,但只要有,它就是查询任何数据库最可靠的钥匙。],但用不加引号的「标题+作者」也常常可行),一个更简单的方法或许是在付费墙页面的 URL 前面加上 sci-hub.st/(或你喜欢的任何 SH 镜像地址)^[我建议用前缀法(如 https://sci-hub.st/https://journal.com),而不是后缀法(如 https://journal.com.sci-hub.st/)。因为前者打起来稍快,但更重要的是,Sci-Hub 的 SSL 证书没配好(我猜是缺少通配符证书),导致后缀法在很多浏览器里会因 HTTPS 错误而失效!而前缀法总能正常工作。]。偶尔 Sci-Hub 会没有某篇论文,或持续报 HTTP 或代理错误,但直接在 Libgen 里搜 DOI 却能找到。最后,Z-Library 镜像站上还有一个 LibGen/Sci-Hub 全文搜索引擎,是谷歌图书的一个不错替代品(尽管 OCR 质量不佳)。
利用大学网络。如果以上方法都不行,而你又没有大学的代理服务器或校友权限,可以考虑亲自去一趟大学图书馆。许多大学图书馆允许基于 IP 地址访问其数据库,并且馆内通常有开放的 WiFi 或可供公众登录的电脑。去之前最好列一张清单,把要找的东西都记下来。
公共图书馆也行。公共图书馆通常会订阅商业报纸或杂志数据库。虽然去一趟不方便,但你至少可以先在其网站上查查它们都订阅了些什么。公共和学校图书馆还有一个获取常见学术资源(如《牛津英语词典》或《纽约时报》、《纽约客》的档案)的妙招:由于它们的用户群体通常不那么懂技术且流动性大,有些图书馆会直接把用户名/密码列表挂在网站上(有时是以 PDF 形式)。他们本不该这么做,但他们就是这么做了。用谷歌搜索「public library New Yorker username password」之类的短语,就能找到一些例子。悄悄地用它下一两篇文章,无伤大雅。(这招用在别的东西的密码上就没那么灵了。)
如果还不行,那就得进入一个更隐秘的文件共享生态圈了:booksc/bookfi/bookzz、像 Bibliotik 这样的私密 BT 站、带有 XDCC 机器人的 IRC 频道(如 #bookz / #ebooks)、像 eMule 这样的老牌 P2P 网络、私密的 DC++ 中心……
特定网站注意事项:
- PubMed:大多数有 PMC ID 的论文都可以通过中国的扫描服务 Eureka Mag 购买;扫描件 $30(2020 年价格),电子版 $20(2020 年价格)。
- Elsevier/
sciencedirect.com:小菜一碟,总能通过 SH/LG 搞定。
注意,许多 Elsevier 旗下期刊的官网无法与 SH 的代理兼容,但它们在sciencedirect.com上的版本却可以,或者论文本身就已收录在 LG 中。如果你在付费墙页面看到sciencedirect.com的链接,而 SH 在期刊官网上失效了,就试试这个链接。 - PsycNET:最烂的网站之一。用 URL 的方法对它从来无效,用标题/DOI 也很少成功。用我大学图书馆的代理,加载的页面会「过期」并重定向,同时还把浏览器的后退按钮给废了(简直了!!!),组合搜索基本没用(常常连文献条目都搜不出来),只有在 EBSCOhost 数据库里用 DOI 或手动搜标题才有一丝希望能找到全文。(EBSCOhost 本身也是个脆弱的搜索引擎,没有 DOI 就很难可靠地查询。)
总之,想尽一切办法在 PsycNET 以外的任何地方找那篇论文! - ProQuest/JSTOR:这两个并非标准的学术出版商,但它们接入或镜像了数量惊人的出版物。
我曾多次在走投无路时,惊讶地发现一份副本就静静地躺在 ProQuest/JSTOR 里,只是搜索引擎对它们的索引做得太差了。 - 期刊独立网站:有时一本期刊会有自己的官网(例如《细胞》或《佛罗里达税务评论》),但背后仍然由 Elsevier 或 HeinOnline 这样的巨头运营。(你通常能从网站设计中看出端倪,比如页脚信息、URL 结构、指向出版商官网的链接等。)
在这种情况下,试图在期刊官网上折腾通常是浪费时间:它不会认可大学的 IP 白名单,SH/LG 也不知道怎么处理它。你应该做的,是去找它在出版商平台上的那个版本。
1.2 求助
人肉搜索。最后的杀手锏:如果以上所有方法都失败了,网上还有几个地方可以求助(不过,如果你已经穷尽了前面所有途径,这些地方通常也无能为力):
- /r/scholar(Reddit 上的学术求助板块)
#icanhazpdf(Twitter 上的求文献标签)- 维基百科资源请求
- LW 帮助台
最后,你还可以随时尝试联系作者本人。这招对我遇到的那些最硬的骨头只偶尔管用,因为它们通常是年代久远的文献,作者要么已经去世,要么无法联系。要知道,任何自 1990 年以来发表论文的作者,其作品通常都已在某个地方被数字化了。但无论如何,这总归值得一试。
1.3 找到之后
在你找到全文副本后,应该为它找一个可靠的长期链接或存储位置,并让它更容易被后人找到。记住那句老话——如果谷歌/谷歌学术里搜不到,它就等于不存在!
- 切勿链接到不可靠的来源:
- LG/SH:永远要抱着它们明天就可能关站的心态来使用。(我叔叔刚给 Library.nu 充了终身会员,网站就挂了,他对此深有体会!)在法律的围剿和各种幕后风波下,谁也无法保证它们能撑多久,也无法保证它们的数据得到了妥善的镜像备份或能在别处恢复。
拿不准的时候,就自己备份一份。 硬盘空间一天比一天便宜。下载你需要的任何东西,自己保留一份副本,最理想的情况是,再把它公开发布出来。
- NBER:绝不要依赖
papers.nber.org/tmp/或psycnet.apa.org这类网址,它们都是临时性的。(SSRN 网站的链接虽然可靠,但现在下载越来越麻烦,也不是理想选择。)
- Scribd:永远别链接到 Scribd——这是个流氓网站,想方设法阻挠下载,而且上面的东西通常在别处早就能找到。(事实上,如果你发现什么有用的东西只在 Scribd 上有,那么把它复制到别处就是为全人类做贡献了。)
- RG:避免链接到 ResearchGate(新东家接手后信誉堪忧,PDF 经常被删除,而且似乎很多是作者自己删的)或
Academia.edu(它们的链接都是一次性的,很快就会失效)。
- 高影响力期刊:链接到 http://Nature.com 或《细胞》官网时要格外小心。如果一篇论文没有明确标为「开放获取」,那么即使它现在能看,也可能在几个月后就消失!^[学术出版商喜欢玩一种「设计陷阱」:在「开放获取」标识的位置放一个标着「全文访问」之类字样的小图标,他们知道,除非你对他们网站的设计了如指掌并仔细检查,否则很容易上当。另一个陷阱是「阅后即焚」式的临时开放:特别是美国心理学会(APA)、美国国家经济研究局(NBER)和《细胞》杂志,它们最喜欢在媒体报道某篇论文时暂时取消付费墙,然后在某个不确定的时间点,悄无声息地撤销访问,让你之前保存的链接全部失效。] 同样,也要警惕
wiley.com、tandfonline.com、jstor.org、springer.com、springerlink.com和mendeley.com,它们也常耍类似的鬼把戏。
~/:小心链接到大学网站上的学术个人主页目录(标志通常是 Unix 风格的.edu/~user/,或是像.edu/cs/course112/readings/foo.pdf这种一看就很临时的目录);这类链接的半衰期极短。
?token=:警惕任何拖着一长串垃圾参数的 PDF 网址,比如?casa_token、?cookie或?X这类查询字符串(以及托管在 S3/AWS 上的文件)。这类链接对别人可能有效也可能无效,但可以肯定的是,它们很快就会失效。(Academia.edu、Nature 和 Elsevier 在这方面是惯犯中的惯犯。)
- PDF 编辑:如果是扫描件,你或许应该花点时间编辑一下:裁剪掉多余的白边,进行二值化处理(对于质量差的灰度或彩色扫描,这一步能极大压缩文件体积并提升可读性),然后进行文本识别(OCR)。
我个人使用 gscan2pdf,但也有其他不错的替代工具值得一试。 - 检查并完善元数据。
给论文/书籍添加元数据是个好习惯,因为它能让文件在谷歌/谷歌学术里被搜到(如果它不上网,它真的存在吗?),而且将来如果你决定使用 Zotero 这类文献管理软件,也会大有裨益。许多学术出版商和 Libgen 在元数据方面做得一塌糊涂,甚至连标题/作者/DOI/年份都懒得加。
使用 ExifTool 可以轻松地为 PDF 添加元数据:exiftool -All可以显示所有元数据,然后用相似的字段名就可以单独设置。
对于那些藏在整卷期刊或其他合集文件里的论文,你应该把相关的页码范围提取出来,创建一个独立的、对应的文件。(提取 PDF 页面,我用pdftk,例如:pdftk old-book.pdf cat 180-196 output new-paper.pdf。许多出版商会在第一页插入一页广告。用pdftk INPUT.pdf cat 2-end output OUTPUT.pdf就能轻松删掉它,但注意 pdftk 可能会清除所有元数据,所以这一步要在添加元数据之前做。要移除伪加密或「有密码」的 PDF,用pdftk INPUT.pdf input_pw output OUTPUT.pdf;真正的加密 PDF 更棘手,但通常也能被市面上的密码破解工具搞定。)要把 JPG/PNG 图片转成 PDF,如果页数少于 64 页,可以用 ImageMagick(convert *.png foo.pdf),如果页数太多,可能需要先逐个转换再合并(例如for f in *.png; do convert "$f" "${f%.png}.pdf"; done && pdftk *.pdf cat output foo.pdf,或者用pdfunite *.pdf foo.pdf合并)。
我通常会至少设置标题/作者/DOI/年份/主题,然后把其他相关主题和文献信息都塞进「关键词」字段。设置元数据的示例:
exiftool -Author="Frank P. Ramsey" -Date=1930 -Title="On a Problem of Formal Logic" -DOI="10.1112/plms/s2-30.1.264" \
-Subject="mathematics" -Keywords="Ramsey theory, Ramsey's theorem, combinatorics, mathematical logic, decidability, \
first-order logic, Bernays-Schönfinkel-Ramsey class of first-order logic, _Proceedings of the London Mathematical \
Society_, Volume s2-30, Issue 1, 1930-01-01, pg264–286" 1930-ramsey.pdf- 「增强版 PDF」优于「普通 PDF」。
如果网站提供两个版本的 PDF,那个标为「PDF」的(如果两者真有区别的话)可能是为打印准备的,会缺少超链接等功能。 - 公开发布:如果可能,发布一个公开的副本。特别是如果它非常难找,哪怕内容对你没什么用,也应该发布出来。救人即是救己。
- 在维基/社交媒体上分享链接:想获得额外加分的话,可以把链接分享到维基百科、Reddit 或 Twitter 的相关页面。这不仅能让更多人知道这份资料的存在,还能极大地提升它在搜索引擎中的曝光度。
- 链接到特定页面:如前所述,通过在 URL 后加上
#page=N,你可以直接链接到特定页面,方便读者。但我建议,如果你的目标是分享一整篇藏在书里的文章,不要这么做,因为这样它的搜索引擎优化(SEO)依然很差,很难被找到。更好的做法是把相关的页码范围裁剪成一篇独立的文章,比如再次使用pdftk:pdftk 1900-BOOK.pdf cat 123-456 output 1900-PAPER.pdf。
1.4 进阶技巧
除了(强烈推荐的)使用热键和布尔运算符进行搜索外,研究者还有一些非常有用的工具。虽然上手有门槛,但长期来看回报丰厚:
archiver-bot:自动为你存档浏览过的网页和/或任意网站上的链接,以防链接失效;这在检测和恢复失效的 PDF 链接时尤其有用。
- 订阅提醒,例如 PubMed 和谷歌学术的搜索提醒:为特定的搜索查询或某篇论文的新引用设置邮件提醒。(谷歌快讯则不像看上去那么有用。)
- PubMed 的提醒设置非常直观:在搜索栏下方点击「创建提醒」即可。(鉴于 PubMed 的索引量巨大,我建议你仔细设定搜索条件,使其尽可能精确,否则你的邮箱会被海量提醒淹没。)
- 要为谷歌学术的任意搜索创建提醒,只需在搜索结果页的侧边栏点击「创建快讯」。要跟踪某篇关键论文的引用,则必须:1. 在谷歌学术中搜到该论文;2. 点击「被引用 X 次」;3. 然后再点击新页面侧边栏的「创建快讯」。
- GCSE:谷歌自定义搜索引擎(Google Custom Search Engines)是一种限定在指定网站或域名白名单内的专业化搜索工具(例如,我自己建的这个专搜维基百科动漫/漫画相关内容的 CSE)。
你可以把 GCSE 看作是一个威力加强版的「已存搜索」。如果你发现自己经常在不同的搜索中反复输入几十个相同的域名,或者不停地用-site:排除某些网站,又或者用大量的否定词来过滤常见的错误结果,那么,是时候建立一个 GCSE 来一劳永逸地解决这些问题了。 - 笔记摘录:使用印象笔记(Evernote)/微软 OneNote 这类笔记服务定期摘录和保存资料,实际上就等于在为你自己创建一个个性化的搜索引擎。
这对于找回你读过的旧资料至关重要,特别是当你想不起确切的引文或参考文献,而相关关键词又极其宽泛的时候。在成千上万条笔记摘录中搜索「自闭症」是一回事,而在整个互联网的汪洋大海中搜索这个词,则完全是另一回事!(你还可以随时整理或编辑笔记,把你可能用来回溯的关键词加进去。)我自己就重度使用印象笔记的摘录功能,这是我找回参考文献的法宝。 - 网站抓取:有时,拥有整个网站的本地副本会很有用,这既能让你进行更灵活的搜索,也能确保你将来可能需要的任何资料都已在手。(例如:「暗网市场档案(2013-2015)」)。
值得了解的实用工具:wget、cURL、HTTrack;Firefox 浏览器插件:NoScript、uBlock Origin、Live HTTP Headers、Bypass Paywalls、Cookie 导出工具。
退而求其次,如果不想完整下载,也可以预先用linkchecker这类工具爬取网站,汇编出所有内链和外链的列表,然后交由其他存档程序处理(实例参见《URL 存档》)。在极少数情况下,像nmap这样的安全工具也能派上用场,用于更深入地探查一个神秘的服务器:它运行着什么网络服务,上面还可能有什么(有时会发现古老的匿名 FTP 服务器之类的有趣东西),网站是否更换过 IP 或服务器等等。
2 网页
如果你能善用 archiver-bot 这类预 archiving 工具,修复自己网站上的链接失效问题会容易得多,但这解决不了外部引用失效的问题。 搜寻丢失的网页,其方法与搜寻论文有相似之处:
- 直接搜索标题:如果知道网页标题,就直接搜标题。
在自己的网页链接中同时包含标题和 URL 是一个好习惯,这能为日后的搜寻提供方便,因为 URL 本身可能是一串天书般的乱码,而且预 archiving 也可能失败。HTML 的链接标签支持alt和title两个参数。如果不想直接显示标题(比如在流畅的超文写作中),也可以在 Markdown 文档里这样干净地嵌入标题:[链接的内联描述](URL "网页标题")。 - 清理 URL:检查 URL 是否有异常,或拖着一长串垃圾参数,例如
?rss=1或?utm_source=feedburner...之类的?或者它是不是一个变体域名,比如mobile.foo.com、m.foo.com或foo.com/amp/?这些链接被找到或存档的可能性,都远低于它们的标准链接。
- 站内搜索:用
site:将谷歌搜索范围限定在原始域名或相关域名内。
- 限定时间搜索:将谷歌搜索的时间范围限定在原始的日期或年份。
这招可以有效收束那些过于宽泛的搜索。除了使用时间范围工具,你还可以用高级搜索语法(目前还管用):通过双点号来指定数字范围,例如foo 2020..2023(这个技巧不只对年份有效)。如果结果还是太多,可以随时把范围缩小到某一年。 - 切换搜索引擎:试试别的搜索引擎。不同引擎的语料库各有差异,而且有时当你需要精确匹配时,谷歌会「聪明反被聪明误」。DuckDuckGo(特别是它的 「bang」 命令)、必应(Bing)和 Yandex 都是不错的替代选择。
- 检查网络档案:如果在「明网」(clearnet)上遍寻无果,就试试互联网档案馆(IA)或元存档搜索引擎 Memento:
IA 是处理失效链接时的默认后备方案。如果 IA 没能「开箱即用」般地解决问题,里面可能还存有其他版本: - 误导性的重定向:IA 是否「贴心」地把你跳转到了一个时间点晚得多的错误页面?手动取消这个重定向,检查该精确 URL 最早的存档版本。页面加载后是否立刻报错或跳转了?用 NoScript 禁用 JS 后再刷新试试。
- 域内归档检索:通过搜索
URL/*,IA 可以列出某个域名下所有被存档过的 URL。这份列表可能会揭示出其他替代性的、更新或更旧的 URL。你还可以按文件类型或关键词对结果进行过滤。
例如,你可以列出某个域名下的所有 URL,如果列表太长且充满了垃圾链接,就可以用「筛选结果」的搜索框来定位,比如在 WordPress 博客的存档里搜「uploads/」。^[为进一步说明此功能:假设你要找 Alex St. John 那篇妙趣横生的回忆录《审判日续…》,这篇写于2013年的文章讲述了微软举办那场疯狂的1996年《毁灭战士》锦标赛的幕后故事,但你手头没有链接。你可以访问https://web.archive.org/web/*/http://www.alexstjohn.com/*来搜索整个域名,然后用「judgment」筛选。或者,如果你至少还记得是2013年的事,就可以把范围缩小到https://web.archive.org/web/*/http://www.alexstjohn.com/WP/2013/*,然后再筛选或手动查找。]
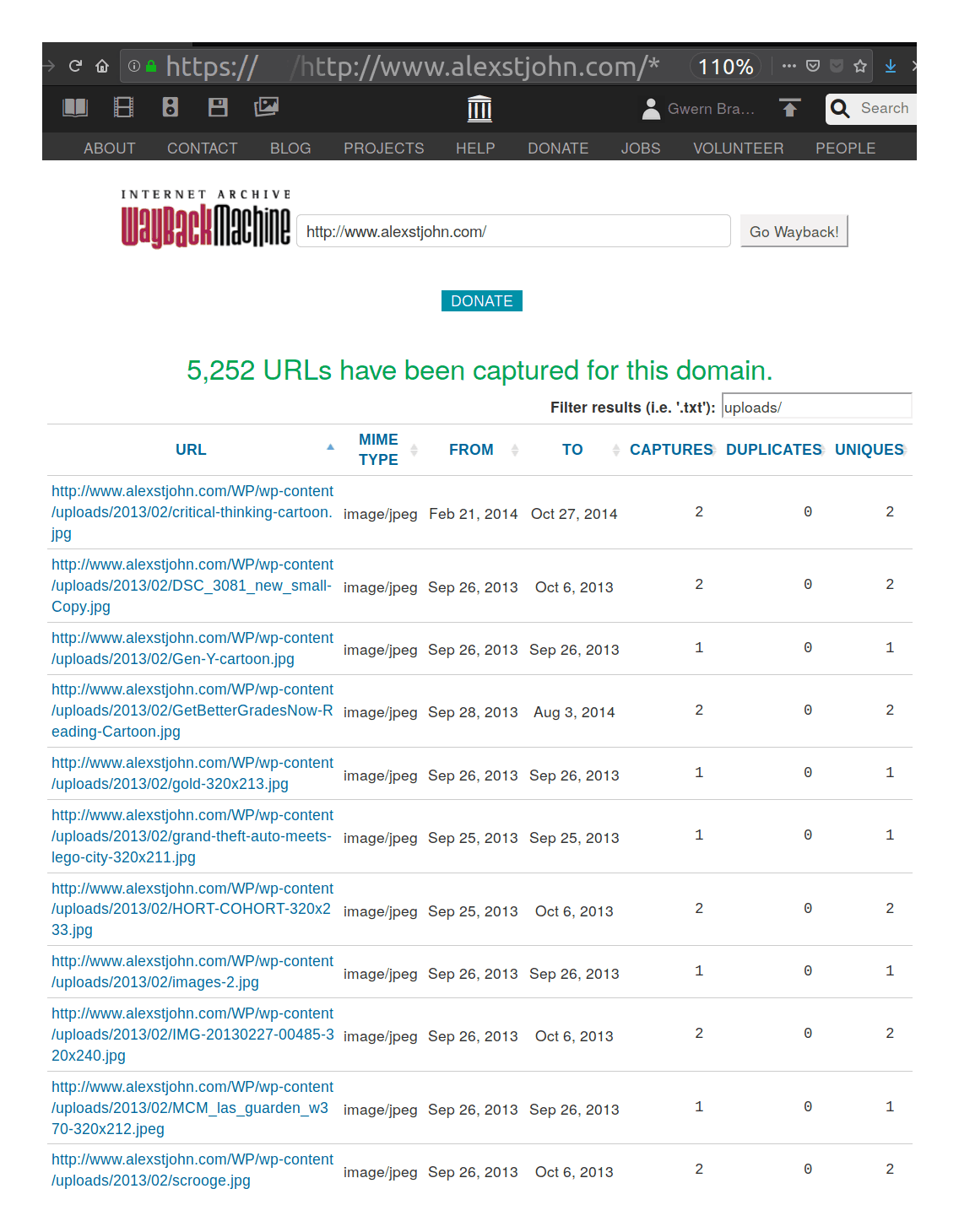
互联网档案馆一个常被忽视的功能截图:显示特定域名的所有可用/已存档的URL,并筛选出匹配如 *uploads/* 字符串的子集。wayback_machine_downloader(别和那个提供文件上传命令行界面的internetarchive Python 包搞混了)是个 Ruby 工具,能让你从 IA 下载整个域名的存档。当你无法通过 URL/* 找到线索时,可以用它把网站下到本地,再用正则表达式进行全文搜索(通常一个好的 grep 查询就够了)。(另一个可行的替代方案是 websitedownloader.io。)示例:
gem install --user-install wayback_machine_downloader
~/.gem/ruby/2.7.0/bin/wayback_machine_downloader wayback_machine_downloader --all-timestamps 'https://blog.okcupid.com'- 域名是否变了?例如,从
www.foo.com变成了foo.com或www.foo.org?在 IA 看来,这都是完全不同的网站。
- URL 本身是否提供了线索?只要留心观察并思考每个目录和参数的含义,你就能从 URL 中读出很多信息。
- 这是不是一个 Blogspot 博客?Blogspot 烂出了风格:它为每个国家都生成一个域名版本。一个
foo.blogspot.com的博客,可能同时存在于foo.blogspot.de、foo.blogspot.au、foo.blogspot.hk、foo.blogspot.jp……^[如果有 Blogspot 的员工在读这篇文章,看在老天的份上,快停下这种疯狂行径吧!]
- 网站是否提供过 RSS 订阅源?
一个鲜为人知的事实是:谷歌阅读器(Google Reader, GR; 2005年10月-2013年7月)曾存储了它抓取过的所有 RSS 内容。如果一个网站的 RSS 源被设置为输出全文,那么它的 RSS 历史就相当于整个网站的镜像。而且 GR 从不删除旧内容,所以曾几何时,从它那里恢复网页乃至整个网站都是可行的。可悲的是,GR 后来关闭了。但在它关闭前,档案团队(Archive Team) 下载了 GR 的大部分历史 RSS 数据,而这些档案现在就托管在 IA 上。唯一的问题是,它们被储存在巨大的 WARC 文件里。这种格式虽然有其存档上的优点,但对用户极其不友好。原始的 GR mega-WARC 文件处理起来非常麻烦,我把具体操作示例放到了附录里。
archive.today:一个类似 IA 的镜像站。(有时能绕过付费墙,或者存有其他服务没有的快照。但我强烈建议,只把它当做一个抓取快照的临时中转站,而不要指望它能长久,因为它没有任何长期运营的计划。)
- 任何本地存档,比如用我那个
archiver-bot制作的。
- ~~谷歌缓存(GC):自 2024-09-24 起已失效。~~
3 书籍
3.1 数字版
电子书比论文更稀少,也更难获取,不过自本世纪初以来,情况已大为改观。要在网上搜寻书籍,可以遵循以下方法:
- 找书更直接:书籍搜索通常比论文搜索更快捷、更简单,对搜索词的构造技巧要求也更低。这或许是因为电子书在网上更稀少,文件体积更大,标题也更简单,从而降低了搜索引擎的处理难度。
要找书,请用谷歌,而不是谷歌学术:
切记:别在谷歌学术里找书
书籍的全文通常不会出现在谷歌学术里(原因不明)。找书时,你得用普通谷歌搜索。
为了反复确认,你可以试试filetype:pdf搜索,然后再去 Libgen(LG)上查一遍。通常,如果「主标题+作者」都搜不到,那它基本就不在网上。(少数情况下,作者顺序或主副标题颠倒了,你微调一下搜索词或许能找到,但这种情况不常见。) - 互联网档案馆(IA):IA 收藏了大量扫描版书籍,但它们往往不会轻易出现在搜索结果里(可能是搜索引擎优化差?)。
- 如果搜索结果中出现了 IA 的链接,一定要点进去看看。里面的 OCR 文本可能会提供线索,告诉你去哪里能找到它。如果一无所获,可以试试在谷歌里进行 IA 站内搜索(注意,不要用 IA 自带的搜索引擎),例如:
书名 site:archive.org。
- DRM 破解之道:如果书确实在 IA 上,但有 DRM(数字版权管理)保护,只能「借阅」,你可以把它「越狱」。
先把书借出来,借满最长的 14 天。将 PDF(而非 EPUB)格式的书下载到 Adobe Digital Elements v4.0 或更早的版本(这个旧版软件可以在 Linux 的 Wine 环境下运行),然后用安装了 De-DRM 插件的 Calibre 导入。这样,一本无 DRM 的 PDF 就会出现在 Calibre 的书库里。(让 De-DRM 插件跑起来可能有点折腾,尤其是在 Linux 下。我当年就不得不手动修改了插件 Python 文件里的一些路径,才能让它在 Wine 里正常工作。而且,这个方法似乎对最新的谷歌 Play 电子书(约2021年后)也失效了。)之后,你就可以给这个 PDF 添加元数据,然后上传到 Libgen^[上传并不像你想的那么难。这里有一个网页上传界面(用户名/密码: "genesis"/"upload")。上传大文件可能会失败,所以我通常用 FTP 服务器:curl -T "$FILE" ftp://anonymous@ftp.libgen.is/upload/。]。(Libgen 上的书籍版本通常比 IA 的扫描版质量好,但如果 LG 上没有,那 IA 的也聊胜于无。)
- 谷歌 Play:其 PDF DRM 与 IA 相同,可以用同样的方法破解。
- HathiTrust:这里也托管了大量书籍扫描件,可以从中寻找线索,或者直接「越狱」。
HathiTrust 禁止整本书下载,但用一个简单的循环脚本逐页下载再拼接起来并不难,例如:
for i in {1..151}
do if [[ ! -s "$i.pdf" ]]; then
wget "https://babel.hathitrust.org/cgi/imgsrv/download/pdf?id=mdp.39015050609067;orient=0;size=100;seq=$i;attachment=0" \
-O "$i.pdf"
sleep 20s
fi
done
pdftk *.pdf cat output 1957-super-scientificcareersandvocationaldevelopmenttheory.pdf
exiftool -Title="Scientific Careers and Vocational Development Theory: A review, a critique and some recommendations" \
-Date=1957 -Author="Donald E. Super, Paul B. Bachrach" -Subject="psychology" \
-Keywords="Bureau Of Publications (Teachers College Columbia University), LCCCN: 57-12336, National Science Foundation, public domain, \
https://babel.hathitrust.org/cgi/pt?id=mdp.39015050609067;view=1up;seq=1 https://psycnet.apa.org/record/1959-04098-000" \
1957-super-scientificcareersandvocationaldevelopmenttheory.pdf- 惠康图书馆(Wellcome Library)是另一个类似的例子。在寻找《关于智力与遗传关系的调查》(劳伦斯,1931)时,我一度一筹莫展,直到我抱着一线希望,点开了搜索结果末尾的一个「惠康数字图书馆」链接——万一它就像那些偶尔能碰到的中国或印度图书馆网站一样,有全文呢?结果,它还真有。好消息?是的,但有个问题:它不提供任何下载整本书的途径!它提供了 OCR 文本、元数据和单页图片的下载,而且都是 CC-BY-NC-SA 许可(没有法律问题),但……就是没有整本书。(更奇葩的是,OCR 文本还被毫无必要地打包成了 zip 压缩文件,这就是为什么谷歌把这个页面排得那么低,而且不显示任何有价值的文本摘要——因为它为了节省几 KB 而把内容藏进了一个不透明的压缩包,彻底毁掉了 SEO。)检查了一下最高分辨率图片的下载链接,发现它们遵循一套坑爹的命名规则:
https://dlcs.io/iiif-img/wellcome/1/5c27d7de-6d55-473c-b3b2-6c74ac7a04c6/full/2212,/0/default.jpghttps://dlcs.io/iiif-img/wellcome/1/d514271c-b290-4ae8-bed7-fd30fb14d59e/full/2212,/0/default.jpg- 等等
- 图片链接不是按 1-90 这样的序号排列,而是每个都用一个独一无二的哈希值或 ID。幸运的是,一个叫 「manifest」 的元数据文件里提供了所有这些哈希/ID(虽然没有高质量的下载链接)。用几个简单的
sed和tr命令处理一下这个文件,就能把所有 ID 提取出来,然后喂给另一个wget循环脚本去下载。
grep -F '@id' manifest\?manifest\=https\:%2F%2Fwellcomelibrary.org%2Fiiif%2Fb18032217%2Fmanifest | \
sed -e 's/.*imageanno\/\(.*\)/\1/' | grep -E -v '^ .*' | tr -d ',' | tr -d '"' # "
# bf23642e-e89b-43a0-8736-f5c6c77c03c3
# 334faf27-3ee1-4a63-92d9-b40d55ab72ad
# 5c27d7de-6d55-473c-b3b2-6c74ac7a04c6
# d514271c-b290-4ae8-bed7-fd30fb14d59e
# f85ef645-ec96-4d5a-be4e-0a781f87b5e2
# a2e1af25-5576-4101-abee-96bd7c237a4d
# 6580e767-0d03-40a1-ab8b-e6a37abe849c
# ca178578-81c9-4829-b912-97c957b668a3
# 2bd8959d-5540-4f36-82d9-49658f67cff6
# ...etc
I=1
for HASH in $HASHES; do
wget "https://dlcs.io/iiif-img/wellcome/1/$HASH/full/2212,/0/default.jpg" -O $I.jpg
I=$((I+1))
done- 之后,这 59MB 的 JPG 图片就可以按常规流程用
gscan2pdf清理(删除空白页、旋转表格、裁剪封面、将其余页面二值化),用ocrmypdf压缩并进行 OCR,最后用exiftool设置元数据,生成一个仅有 1.8MB、可读、可下载且对搜索引擎极其友好的 PDF。 - 别忘了,「模拟漏洞」(Analog Hole)这招对论文和书籍同样适用:
如果你能找到一份资料在线阅读,但因为网站使用了 JS、复杂的 Cookie 验证或其他技术,无法直接下载,你总可以利用「模拟漏洞」——把书全屏,调到最高分辨率,然后一页一页地截图。之后再进行裁剪、OCR 等处理。这方法虽然笨,但管用。而且只要你的截图分辨率足够高,质量损失会相对较小。(这招对扫描版的书比对原生数字版的书效果更好。)
3.2 实体书
获取实体书,价格不菲,但切实可行。与论文和学位论文相比,书籍就像一把双刃剑。一方面,书籍更常出现网上找不到的情况,必须在线下购买,但好在二手书几乎总能在线下轻松买到(而且往往总花费不到 $10(2019 年价格))。另一方面,论文和学位论文虽然常能在网上找到,可一旦找不到,那通常就是真的就彻底找不到了,让你束手无策(除非你有大学的馆际互借部门做后盾,或者愿意亲自跑到那少数几家甚至唯一一家存有纸质或缩微胶卷副本的大学)。
从二手书商处购买:
- 卖家选择:
- 二手书搜索引擎:谷歌图书和 find-more-books.com 是寻找卖家的绝佳起点。如果打算从 AbeBooks、亚马逊或巴诺书店这类平台市场购买,不妨先搜一下卖家本身,看看他们是否有自己的独立网站,那里可能便宜得多,而且可能还有不同版本的库存。
- 不推荐:eBay 和亚马逊通常不是好选择,因为运费和最低消费门槛高,而且亚马逊上的卖家似乎把买家当冤大头。不过,它们有时可以用来查查页数、ISBN 或书名变体等元数据。
- 推荐:AbeBooks、Thrift Books、Better World Books、巴诺书店(B&N)、Discover Books。
注意:在 AbeBooks 上,购买国际卖家的书可能很划算(尤其是行为遗传学或心理学类书籍),但要小心信用卡支付问题——许多借记卡/信用卡在处理国际订单时会失败并触发欺诈警报,而且该网站不接受 PayPal。
- 价格提醒:如果一本书暂时没货或太贵,可以设置价格提醒。AbeBooks 支持为保存的搜索设置邮件提醒;亚马逊则可以通过 CamelCamelCamel 来监控(记住,你要设置的是第三方二手类别的价格提醒,因为新书不仅更贵、货源更少,而且也没必要买)。
扫描数字化:
- 破坏性 vs. 非破坏性:这是书籍扫描的核心困境。用美工刀或断头台式切刀破坏性地拆掉书脊,效果要好得多,也省时得多^[虽然平板扫描有时也是破坏性的——我就曾在把书压平扫描时,把书脊给压裂了。]。因为这样就可以用馈纸式扫描仪,速度至少快 5 倍,扫描质量也更高(因为纸张平整、边缘清晰、对齐也更准),但代价当然是毁掉这本书。
- 工具:
- 切割:如果一年只拆几本书,一把 X-acto 美工刀就够了(避免用三角形刀片,要用那种为大切割设计的弧形刀片)。
如果每个月都要拆一本以上,那就该升级到断头台式切纸机了(一种更专业的摇臂式切纸机,通过双关节系统来压紧并均匀切割)。
断头台式切纸机可以轻松切下 200 页厚的一叠纸而不移位。所以对于更厚的书,我会两者并用:先用美工刀沿着书脊把书分成几块 200 页厚的小册子,再用切纸机处理。
- 扫描:到了一定阶段,把扫描工作外包给像 1DollarScan 这样的服务可能更划算。就我用过的黑白扫描而言,1DS 的质量尚可,但要小心他们零敲碎打的收费项目,比如 OCR 或「设置 PDF 标题」。这些你自己用
gscan2pdf/exiftool/ocrmypdf分分钟就能搞定,而且能省下大笔钱,因为他们竟然是按 100 页为单位来收费的。你可以把书直接寄给 1DS,省去物流的麻烦。
- 后期处理:扫描后,进行裁剪、二值化、OCR 并添加元数据。
- 添加元数据:原则与论文相同。虽然还可以添加书签等更复杂的元数据,但我还没尝试过。
- 文件格式:用 PDF,别用 DjVu。
尽管 PDF 在许多方面是更差的格式,但我现在推荐使用它,并且已停止在新扫描件中使用 DjVu^[我的变通方法是:先从 gscan2pdf 导出为 DjVu 以避开某个 bug,然后用ddjvu -format=pdf把 DjVu 转成 PDF;这会清除所有 OCR,所以我再用ocrmypdf添加 OCR,用exiftool添加元数据。],也把我以前的 DjVu 文件都转成了 PDF。 - 上传:通常上传到 Libgen,有时也上传到我自己的网站 http://Gwern.net。如果没有自己的网站,可以用 Dropbox、Mega、MediaFire 或 Google Drive 这类网盘做备份。我通常会上传三份副本,包括 Libgen。我每年会轮换一次网盘账户,避免在单个账户里放太多文件。我不鼓励依赖互联网档案馆的链接。
切勿使用 Google Docs/Scribd 等「文档网站」进行长期托管
像 Google Docs (GD) 这类「文档」网站,应严格避免作为主要托管平台。GD 的内容不会出现在谷歌/谷歌学术的搜索结果中,这会让一份文档永无出头之日。而 Scribd 则通过不断变换的设计陷阱,对用户极不友好。这类网站上的内容无法被搜索、抓取、可靠下载、摘录,无法在多种设备上使用,也无法存档^[Google Docs 是个例外:在 URL 末尾加上/mobilebasic(截至 2023-01-04 有效)可以得到一个简化的 HTML 视图,这个视图是可以被存档的。例如,《抱枕爱好综合指南》这篇只在 Google Docs 上有的文章,其.../mobilebasic版本的 URL 就能被互联网档案馆抓取。],更不能指望它能长久。(例如,Google Docs 就曾因不明原因,将许多公开文档擅自设为「私密」,破坏了公共链接,甚至当我联系作者时,连他们自己都对此感到惊讶。)
这类网站或许对协作或问卷调查有用,但应被严格视为临时的工作文件,并尽快转移到别处,以干净的静态 HTML/PDF/XLSX 格式托管。 - 托管风险:托管论文很简单,但托管书籍有风险。
书籍可能很危险。在决定是否托管一本书时,我的经验法则是:只托管 2000 年以前出版、没有 Kindle 版或其他商业开发迹象、实际上已成为「孤儿作品」的书。
截至 2019 年 10 月 23 日,在 9 年间托管了 4090 个文件后(粗略估算,假设线性增长,约等于 670 万「文档-天」的托管量),我总共收到了 4 份删除通知:一本行为遗传学教科书(2013 年版)、《精神病态手册》(2005 年版)、一篇近期的元分析论文(Roberts et al 2016),以及剑桥大学出版社(CUP)针对 27 个文件的 DMCA 删除通知。托管那两本书,是我自己打破了经验法则(我的错)。除去这两本书,就只剩那篇论文了,我认为那纯属偶然。所以,只要避免托管较新的书籍,风险应该是极小的。
4 案例研究
5 另见
略
6 外部链接
略
7 附录
略
Thoughts Memo 汉化组译制
感谢主要译者 gemini-2.5-pro、校对 Jarrett Ye
原文:Internet Search Tips · Gwern.net
作者:Gwern Branwen
互联网归档,命令行界面(CLI),谷歌,教程
2018-12-11~2023-08-08 · 已完稿 · 确定性: 确定 · 重要性: 4