
市场/演化可作为强化学习/优化的最终保障/基准真相:本文探讨科斯的企业理论、线性优化、深度强化学习、演化、多细胞生命、痛苦、互联网社区作为多层次优化问题之间的一些联系。
摘要
为自由市场辩护的观点之一,是指出非市场机制无法解决计划与优化问题。然而,这一观点与科斯的企业悖论难以自洽。并且我注意到,随着计算机、算法和数据的进步,规模日益庞大的计划问题的确正在被解决,这让前述观点更显窘迫。
在 Cosma Shalizi 一些评论的基础上,我建议将这些现象解读为一个多层次嵌套的优化范式:许多系统都可以被贴切地描述为包含两个(或更多)层次。其中,一个缓慢、样本效率低但基于基准真相的「外部」损失函数(如死亡、破产或繁殖适应度),负责训练并约束一个快速、样本效率高但可能误入歧途的「内部」损失函数,而后者则被神经网络或线性规划等学习机制所使用。(在群体选择理论中,更高层次对应着不同的「群体」。)
因此,推崇自由市场、演化或贝叶斯方法的一个普遍理由是:尽管它们在短期内的计划/优化能力较差,但其优势在于简单,且基于基准真相进行运作,从而能对更复杂的非市场机制起到约束作用。
我将通过讨论公司、多细胞生命、人工智能领域的强化学习与元学习,以及人类的痛苦来阐释此观点。
这一视角表明,在市场与非市场机制之间存在着一种内在的平衡,它反映了一种缓慢但无偏的方法与一种更快但可能存在任意偏差的方法之间的相对优劣。
在科斯的企业理论中,存在一个悖论:理想化的竞争市场在分配资源、制定决策以达成高效结果方面堪称最优,但构成每个市场的参与者(例如大型跨国巨型公司)其内部却并非由市场组成,而是通过非市场机制来决策,即便处理那些完全可以外包的事务也是如此。Herbert Simon 在一段常被引用且妙趣横生的文字中,将现实情景戏剧化地呈现了出来:
假设「一位来自火星的虚构访客」从太空接近地球,他配备的望远镜能够揭示社会结构。在他看来,公司呈现为一个个坚实的绿色区域,内部有模糊的轮廓划分出不同的业务部门。市场交易则如同连接这些公司的红线,在它们之间的空间里织成一张网络。在公司内部(甚至可能在公司之间),这位访客还看到了淡蓝色的线条,那是连接老板与各级员工的权力线。当他更仔细地观察下方的景象时,或许会看到某片绿色区域一分为二,因为一家公司剥离了旗下的一个部门;又或者,他会看到一个绿色物体吞并了另一个。在这个距离上,那些离职高管的「金色降落伞」恐怕是看不见的。无论我们的访客靠近的是美国还是苏联,是中国城市还是欧盟,他眼下绝大部分空间都被绿色区域占据,因为几乎所有居民都是雇员,身处公司边界之内。组织,将是这片景观的主导特征。他发回母星的讯息,在描述此番景象时,会说「由红线相互连接的大片绿色区域」,而不太可能说「一张连接着绿色斑点的红线网络」……当这位访客了解到绿色区域是组织,而连接它们的红线是市场交易时,他听到这种结构被称为「市场经济」后,可能会感到惊讶。「称之为『组织经济』,难道不是更恰当的术语吗?」他或许会这样问。
自由竞争市场是一台称重机,而非一台思考机器;它衡量、比较参与者提出的买卖双方,最终得出一个出清价格。但问题是,那些被衡量的东西究竟从何而来?市场参与者本身并非市场,诉诸市场的智慧无异于推卸责任。如果说市场能够「发掘信息」或「激励绩效」,那么这些信息是如何被学习和表达的?那些带来更优绩效的实际行动又源自何处?在某个环节,总得有人去进行真正的思考。(一家公司可以把保洁工作外包给自由市场,但中标的承包商仍然需要决定在何时、何地、以何种方式完成保洁工作;可以肯定的是,它不会在内部保洁员之间搞一场拍卖来划分责任、制定排班。)
这个悖论在于,自由市场似乎依赖于那些内部以极权指令式独裁方式运作的实体。人们不禁要问,为何会有公司这种组织存在,而不是让一切事务都通过当前最基本的原子单位——也就是单个的人——之间的交易来完成?科斯的解释是,这是一个委托-代理问题:其中涉及风险、谈判成本、商业机密和背叛,而且委托人与代理人之间存在差异本身,就可能导致成本过高、管理开销过大。
渐近成为现实
另一个视角源于社会主义计算大论战:如果中央计划者能够规划出最优的资源配置并直接下达指令,那为什么还需要市场,任其充满浪费与竞争?Cosma Shalizi 在为 Spufford 的《红色丰裕》一书撰写的书评[1]中(该书参考了《苏联的计划问题:1960-1971年数学经济学的贡献》,由 Ellman 于1973年编辑),探讨了线性优化算法的历史。这类算法同样在苏联由 Leonid Kantorovich 领导开发,并用于经济计划。颇具讽刺意味的一点是(Shalizi 将此观点归功于 Stiglitz),在那些能让市场达致最优结果的理论条件下,线性优化算法同样能够做到。当然,在现实中,苏联经济不可能通过这种方式运行,因为它需要对数百万乃至数十亿个变量进行优化,这要求无法想象的计算能力。
[1] 另可参阅 SSC 及 Chris Said 的书评。
优化已然可及
时至今日,我们恰恰拥有了无法想象的计算能力。昔日的否定后件,如今已然变成了肯定前件。
公司,尤其是作为前沿的科技公司,如今已能常规性地解决涉及数百万变量的规划问题,例如车队物流或数据中心优化;类似的 SAT 求解器在计算机安全研究中无处不在,用于对大型计算机代码库进行建模,以验证其安全性或发现漏洞;绝大多数机器人若不能持续求解和优化庞大的方程组,便无法运行。科技公司内部的计划「经济」如葛藤般蔓延生长,催生出愈发庞大的数据集用于预测,愈发自动化的分析用于规划,以及愈发精密的市场设计用于控制。沃尔玛或塔吉特这类零售商所解决的问题,已是世界级的规模。[2](「我们不定价,是市场在定价」,他说,「我们用算法来确定市场是什么。」)谷歌、亚马逊或优步的座右铭或许可以这么说(借用 Freeman Dyson 在 1988 年出版的《全方位无限》中对约翰·冯·诺伊曼的转述):「凡是稳定的过程,我们皆将之纳入计划;凡是不稳定的过程,我们暂且于其中展开竞争。」公司或许会使用一些有限的内部「市场」作为资源分配的有效比喻,也可能涉足预测市场,但科技公司的内部动态与自由竞争市场几乎毫无相似之处,也鲜有向市场化方向发展的迹象。
[2] 有趣的是,《红色丰裕》一书的扉页上,注明了该书出版商曾获得塔吉特公司的一笔赞助。
计划的步伐也丝毫没有停歇的迹象。优步不会停止利用历史数据预测需求,从而调动司机去满足预期客流并优化行车路线;数据中心不会停止使用线性求解器,以最优方式将运行中的任务分配给机器,从而在平衡延迟与吞吐量的同时,最大限度地降低电能消耗,以期达成良性循环,最终实现那条最优路线——「永恒的旅程,永不终结的旅程」;诸如智能手机「围墙花园」之类的「市场」,每年都愈发依赖算法来解析用户评论、程序文件和点击行为,以决定内容排名、广告推送,并对各种选项进行多臂老虎机式的探索;如此种种,不胜枚举。
那么,我们能否像 Cockshott & Cottrell 所提议的那样,通过不断扩大计划规模,运行一个近乎百分之百中央集权的经济体,同时还能提升效率,甚至超越自由资本主义式的竞争市场?(这一提议偶尔会在大众社会主义的讨论中复活,例如《沃尔玛人民共和国:世界最大公司如何为社会主义奠基》一书)。
各类系统
让我们再看几个例子:
- 公司与增长
- 人类、大脑与细胞
- 人工智能领域的元学习(尤其是强化学习)
法人
关于公司进步,最引人注目的一点是,它们根本不会进步;公司不会演化(参见普莱斯方程与多层次选择理论,该理论可应用于诸多领域)。倘若公司真会演化,商业世界将是另一番景象!尽管公司之间存在着巨大且持续的效率差异(这是一个由来已久的悖论),但最优秀的管理实践或最卓越的公司并不会简单地「克隆」自我,然后凭借其超凡技能周期性地占领任意行业(并在成为行业唯一范式后,最终被效率更高的突变后代所取代,如此循环往复)。
我们可以无限复制最顶尖的软件算法(如 AlphaZero),其表现能与原作媲美,还能通过各种方式调整使其稳步提升(事实上,许多算法正是通过持续迭代这样发展而来);物种能够繁衍自身,不断演化以更好地适应其生态位,更不用提选择性育种计划的强大威力;人类个体能够改进教学方法并传授技能(微积分曾是顶级数学家的专属领域,如今已是普通高中生的课程;而有了象棋引擎等更优、更强的教学方法,国际象棋特级大师的平均年龄也越来越小);如果我们真想这么做,甚至可以克隆杰出个体,以获得更多天赋相近的人。但我们从未在公司身上看到这种现象。恰恰相反,尽管公司拼命维持所谓的「企业文化」,它们通常也只是随波逐流,变得日益臃肿迟缓,无法再分拆出像初创时那般精悍高效的小公司,直到环境变化、随机冲击或内部衰退最终将其淘汰——比如,被某个毫不相关的公司(有时甚至是大学生等纯粹的局外人创立的公司)抢走饭碗。
为什么我们看不到卓越的公司克隆自身,进而占领所有细分市场?为什么公司没有演化至今,以至于所有公司或商业实体都成了 50 年前某个「企业始祖」的超高效后代,而所有其他公司都已破产倒闭或被收购?为什么公司如此难以保持其「文化」的完整性并维持年轻时的精悍效率?或者,如果「衰老」不可避免,它们又为何不通过自我复制或其他方式繁衍出与自身相像的新公司?现实是,成功的大公司依赖惯性或市场失理(如监管俘获/垄断)得过且过;而成功的小公司则在成长过程中无休止地担忧如何保留「文化」、如何「保持饥饿」,或是如何为创始人寻找接班人,内部始终处于流动变化之中。大公司仅仅是运作得差强人意,以至于维持其存在本身已算是一项成就[3]。
[3] 更多来自 Simon 1991年的论述:
多年以来,大部分经济活动都已汇集于规模庞大且持续增长的组织高墙之内。我们的火星访客所观察到的绿色区域一直在稳步扩大。我和 Ijiri 曾提出,组织的增长或许与效率关系不大(尤其因为在多数大型企业中,规模经济与不经济的效应都相当微弱),而主要可能是由简单的随机增长机制所致 (Ijiri and Simon, 1977)。
但是,即便特定的协调机制无法精确划定组织与市场间的边界,大型组织的存在及其效能确实有赖于一套完备且强大的协调机制。组织内部的这些协调手段,与前文讨论的激励机制相结合,通过劳动分工与专业化,为提升生产力与效率创造了可能。
总体而言,随着任务专业化程度的加深,各专业化部分之间的相互依赖性也随之增强。因此,一个拥有高效协调机制的结构,能比缺乏此类机制的结构将专业化推向更深的层次。曾有观点认为,现代工业中的劳动专业化是独立于工厂制度的兴起而发展的。这在工业革命早期或许成立,但对于当代工厂而言,此论点则难以站住脚。权威关系、其激励基础、一套协调机制,再加上劳动分工,这些因素的结合,造就了我们现代生活中标志性的大型科层制组织。
演化与普莱斯方程的成立需要三个要素:能够自我复制的实体;实体间的变异;以及作用于实体之上的选择。公司存在变异,也面临选择——但它们缺乏复制能力。
公司无疑会因某种适应度而经历选择,且彼此间差异巨大。问题似乎在于,公司无法自我复制。诚然,它们可以创立新公司,但这未必是复制它们自身——它们无法像细菌那样克隆自己。当一个细菌克隆自己时,它得到的是……一个克隆体,在任何方面都几乎无法与「原型」区分。在有性繁殖的生物中,子代也依然在很大程度上与亲代相似。但当一家大公司分拆一个部门或创立一个新部门时,其结果可能与母公司毫无共同之处,完全没有继承任何成功的秘方。一笔新的收购也将保留其原有的特质和效率(如果有效率可言的话)。公司最终会成长到其无法胜任的规模,从而印证了彼得原理,而这个规模总是远小于「整个经济体」的范畴。公司由人构成,而非可互换、易复制的零件或 DNA 链。不存在可以被复制以创造一个与旧公司别无二致的「公司 DNA」。公司甚至可能无法在时间长河中「复制」自身,从而导致僵化与衰老——而这又会引致业绩下滑,并最终以某种方式被淘汰。因此,一家普通公司的效率,似乎并不比 50 年前的普通公司高明多少,尤其是在剔除新技术带来的增益后。而像美第奇银行这种 500 年前罕见的跨国公司所面临的挑战与失败,也与今日银行所面临的惊人地相似。
我们在其他大型人类组织中也能看到类似的问题,那就是「文化」。有一种观点认为,文化会经历选择与演化,因此是由各种适应性的信念、实践和制度构成的,而其整体智慧是任何个体所无法理解的(例如,为适应当地条件而优化形成的耕作方式);即便是那些看似极不理性、铺张浪费的传统习俗,实际上也可能是一种适应性的演化产物,在我们尚未领会的某种意义上达到了最优(这种观点有时与「切斯特顿的栅栏」联系在一起,作为一种为现状辩护的论据)。
这并非无稽之谈,因为确实有些传统习俗的有效性得到了科学研究的证实。然而,从普莱斯方程所定义的多层次选择视角来看,这种观点存在严重的量化问题:文化或群体极少被彻底淘汰,大多数大型文化都能延续数千年;这种群体层面的「自然选择」与构成这些文化的成千上万种具体实践和信念之间的联系极为脆弱;并且,这些文化会因时尚、思潮、故事、邻近文化和新技术的更迭而迅速变异(只需比较一下民间巫术/医术在小片地理区域内,或在同一地点数百年间的稳定性,便可见一斑)。对大多数事物而言,「传统文化」根本就是错得离谱且有害无益的,其各种形式不仅自相矛盾,未经科学验证,也不包含任何有用信息。而且——与「切斯特顿的栅栏」的初衷相反——一种习俗越是古老,越是难以找到其存在的合理依据,它就越不可能是……有益的:
切斯特顿的元栅栏:「在我们当前的体系(拥有大型政府的民主市场经济)中,拆除『切斯特顿栅栏』的普遍做法本身似乎已是一个行之有效、记录良好的过程,不应受到不当干预(除非你完全理解其所以然)」。
文化演化的支持者,如 Heinrich,也承认存在大量错误实践,甚至承认错误实践也能成功传播(例如,Heinrich 提供了几个例子,其情形堪比遗传漂变导致有害突变的扩散;Primo Levi 则为这类事物创造了「油漆里的洋葱」一词)。因此,这里的关键在于侧重点或数量:我们是该看到杯子里那 1% 的水,还是那 99% 的空空如也?在此,我们有必要回顾一下人类获得专业知识所需满足的条件(Armstrong 2001, 《预测原则》;Tetlock 2005, 《专家政治判断:有多好?我们如何知道?》;Ericsson 编辑 2006, 《剑桥专业知识与专家表现手册》;Kahneman & Klein 2009):在不变的环境中,针对客观结果进行有快速反馈的重复练习。这些条件在人类活动中极少能被满足。人类活动往往是偶发的,反馈漫长而延迟,评估标准相当主观,并且夹杂着海量的随机因素以及无数前后决策带来的后果,还可能面临环境的剧变(人们学习能力越强,环境变化可能越快)。在这样的环境中,人们更可能无法建立起专业知识,反被随机性所蒙蔽,并构建起一套套精巧却谬误百出的迷信理论大厦(正如 Tetlock 笔下的那些「刺猬」型专家)。演化并非点石成金的魔法,无法克服这些严峻的推理难题,而这也正是强化学习如此困难的原因所在。[4]
[4] 用强化学习的术语来说,演化,如同演化策略一样,是一种蒙特卡洛方法。蒙特卡洛方法无需了解环境模型,偏差低,能轻松处理长远后果,不会像自举法(bootstrapping)那样发散、失效或产生偏见(尤其是在「致命三元组」的情况下),并且是去中心化的、易于并行的。当然,其主要缺点是,它实现这一切的代价是极高的方差和极低的样本效率(例如,Salimans 等人 2017 年的研究表明,其样本效率比主流深度强化学习方法差约 10 倍)。
对于像农业这一类事物而言,它有规律的反馈,其结果对个体和群体的生存都至关重要,且拥有相对直接的机械性因果关系。因此,传统农耕实践趋向于一定程度上的优化,这一点不足为奇(尽管离最优仍相去甚远,正如工业革命带来的产量巨幅增长所揭示的,其部分原因正是避免了传统农业的谬误并采用了简单的育种技术)[5];然而,所有这些有利条件都与「传统医学」无缘。传统医学要处理的是复杂的自选择效应、向均值回归和安慰剂效应。除了设定断骨这类最简单的情形(同样,过程直接,因果明确),传统医学几乎毫无用处[6]。假如某种传统疗法仅仅是无效而没有直接毒性,那已经算是万幸。而在被蛇咬伤这类最棘手的情况下,待在家里等死都比浪费时间去找本地巫医要强。
[5] 但请注意那些被广为引用的例子背后的讽刺:玉米的碱法烹制和木薯的去氰处理常被用来证明群体选择如何将微妙的智慧编码于农耕之中。然而,在这两个案例中,那些在美洲大陆发明了这些技术的人群,尽管拥有更先进的本地食物加工技术,最终却表现得极度「不适应」,因瘟疫和征服而遭遇了毁灭性的人口锐减!你或许会反驳说,那是外来因素,是运气不好,与他们的食物加工技术无关……但这恰恰是群体选择理论的症结所在。
[6] 美国国家癌症研究所(NCI)的抗癌植物筛选项目,便是传统医学失败的一个例证。该项目由一位热衷于医学民俗和民族植物学的专家负责,他特意依据「包括古中国、埃及、希腊和罗马典籍在内的大量文献检索」来筛选目标植物。该项目筛选了「约 12,000 至 13,000 个物种……超过 114,000 份提取物接受了抗肿瘤活性测试」(此后筛选速率急剧上升),最终只产生了 3 种药物(紫杉醇/Taxol/PTX、伊立替康和卢比替康),其中只有紫杉醇算得上举足轻重。所以,在一个几乎没有什么有效抗癌药可作参照的年代,针对全球各地历史上传统医学所珍视的所有唾手可得的植物进行大规模筛选,其成功率大概在 0.007% 这个量级。
近年的一个例子是抗疟药青蒿素,其发现者屠呦呦因此荣获 2015 年诺贝尔奖。她所在的实验室专攻传统草药(毛泽东曾鼓励构建「中医药」体系,以期减少医疗开支、节约外汇)。她在 1972 年筛选了数千种传统中药方后发现了青蒿素。青蒿素无疑是重要的,但人们不禁要问:在之后的 43 年里,她的实验室又从这座传统中医药的宝库中发现了什么呢?答案似乎是:「什么也没有」。
诚然,从纯粹的成本效益角度看,紫杉醇和青蒿素的发现或许能证明植物筛选的价值(这样的命中率似乎不比其他药物研发方法差太多,尽管也应注意到,逐利的制药业并未优先或大量投资于「生物勘探」),但此事更重要的教训在于「传统医学」的准确性。传统医学为检验「传统的智慧」提供了一个绝佳的案例:医学有着硬性的评价终点,因为它实实在在关乎生死;它是每个个体在一生中都会面临的问题(而非偶尔发生在群体层面);其效果可能极为显著(堪称「灵丹妙药」);并且,人类有数万乃至数十万年的时间去积累和筛选。即便有这么多有利因素,传统的智慧是否能克服那些导致错误信念的严重统计困难和认知偏见呢?事实是,传统医学最辉煌的成功案例,其准确率也不过……%。「我们的古老父辈有好药草」?此言不虚……所谓的「传统的智慧」,大抵如此了。某些有效的药物,碰巧在某些传统中,在某些时候,以某种方式,与成千上万种外观别无二致的无用或有害的药物一同被提及。这一事实,根本不能证明民间医学是真理的可靠来源,这就像海因里希·施里曼发现了一座有那么点像特洛伊的古城,并不能成为我们将《伊利亚特》或《奥德赛》当作严谨史书而非 99% 虚构文学的理由一样。(其他例子亦是同理,比如澳大利亚原住民神话保留了些许远古地质事件的痕迹:这当然不表明口述历史是可靠的历史,我们也不该将其信以为真。)
所以——正如公司一样——文化的「选择」过程极为罕见,其每个「代际」都长达数百年乃至数千年;这种选择通常与文化信念是否符合现实关系甚微(其选择系数趋近于零);即便一种文化真的凭借对某种草药的更有效认知而吞并了另一种文化,它也很可能会在迷因突变的轮番轰炸下故态复萌(因此,任何选择的作用都仅仅是清除突变,从而达成一种突变-选择平衡)。在此条件下,文化基本不会出现朝向更优状态的长期「演化」,其信息含量将微乎其微,并被严格局限于那些最普适、对适应度影响最大、且在迷因层面最稳固的方面。
自然人
个体生物最好被视为适应策略的执行者,而非适应度的最大化者。自然选择无法直接「洞察」特定情境下的个体生物,并使其行为为了满足该情境的功能需求而做出精准的适应性调整。
——Tooby & Cosmides 1992, 《文化的心理基础》
意识形态很棒,可惜物种不对。
——E. O. Wilson, 评马克思主义
人类则与此形成鲜明对比。人类虽然最终由演化设计而成,但在其生命个体的实际运作中(即「运行时」),演化本身不再扮演任何角色,取而代之的是更为强大的学习算法。
凭借这些由演化这一元算法所设计的更强大算法,一个人得以成功存活百年以上。其体内数万亿细胞间展现出惊人的合作,历经一生中更多数万亿次的细胞分裂与更替,也只是在生命末期才偶尔出现少数癌细胞叛变,导致系统崩溃。(并且,这些癌症自身也必须解决诸如血管生长之类的协调问题——与一些事物的合作,总是意味着对抗另一些事物。)人类还能够被克隆,产生同卵双胞胎,他们各方面都如此相似,甚至连熟人都可能无法分辨。而且,人类无需借助演化或市场来发育身体,而是依赖一套由基因控制的、复杂的、与生俱来的发育程序,这确保了超过 99% 的人类都能获得他们所需要的两只眼睛、一对肺、两条腿、两个大脑半球等等。
或许,人类最惊人的效率提升,在于拥有了一个能够预测未来、学习高度抽象世界模型的大脑。基于这些模型,人类可以制定计划并进行优化,其目标可能仅仅是与数十年后的适应度间接相关,或与一生难遇且通常无法观测的适应度事件有关,甚至是像后代的适应度这类永远无法直接观察到的事件。
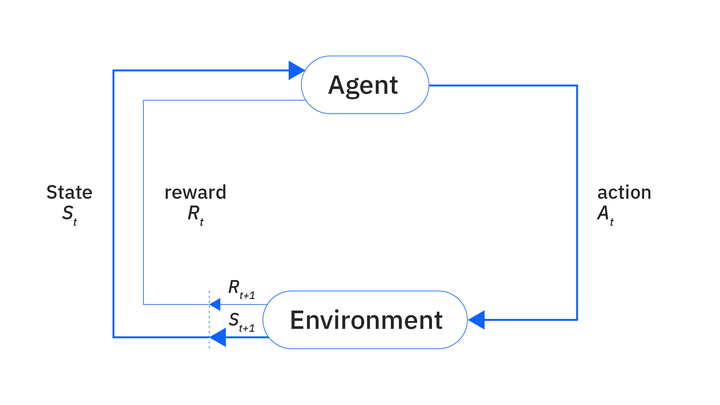
强化学习
黑箱优化 vs. 白箱优化
让我们换个说法。
想象一下,你尝试经营一家公司,而你得到的唯一反馈就是公司是否破产。在经营过程中,你做出了数百万乃至数十亿个决策:采用某个商业模式,租赁某个店面,推广某款产品,从几十名应聘者中录用某个人,分派给他们某项任务让他们自己再做出一系列决策(而这些决策又可能需要其他人再做决策),如此往复,年复一年。最终,你要么大赚一笔,要么关门大吉。
于是,你只得到 1 比特的反馈信息,而这仅有的 1 比特信息却要分摊到数十亿个决策之上。当一家公司破产时,是什么导致了它的覆灭?是雇错了会计?是 CEO 在研发上投入不足?是偶然的地缘政治事件?是政府的新规?还是总部选错了城市?抑或仅仅是普遍的效率低下?你如何知道哪些决策是好的,哪些是坏的?你该如何解决这个「信度分配问题」?
最理想的情况是,你能找到一种方法,将公司财务状况的每一次波动都追溯到最初的决策及其背后的决策算法,并与所有可能的反事实进行比较。但这显然是不可能的,因为你无从知晓谁说了什么、做了什么,甚至谁在何时与谁讨论了什么,更不可能知晓所有反事实世界,并将其与一家理想的公司进行对比。
除了演化这种真正简单粗暴的方法,似乎再无他法:让众多公司并行发展,一些采取某种行为方式,另一些则采取另一种,经过大浪淘沙,好的决策会更多地集中在幸存者身上,而不那么好的决策则会集中在倒闭者身上。在这里,「学习」是有效的(在某些条件下——比如足够可靠的复制机制,尽管这在现实中可能无法满足),但其代价高昂得可怕,而且速度慢得惊人。同理,要给高管付薪,最好的方法或许就是将其与股票表现挂钩:CEO 的贡献无法被简化为几个无法作弊的指标(比如他一天做了多少零件),也无法归结为任何简单的规则集——CEO 的职责恰恰是监督其他所有事务,决定公司战略,并自上而下地塑造企业文化。一个糟糕的 CEO 可以毁掉一家非常成功的公司,而一个优秀的 CEO 则能使其更上一层楼,即便他们都遵守了所有明文规定。这种薪酬方式会导致一些荒谬的现象,比如 CEO 因为一些「显然」与他们无关的事情而获得巨额回报;但任何试图改进绩效薪酬的尝试,都会遇到诺贝尔奖级别的难题。没有借口,没有辩解,没有解释为何不是自己的错——只要结果。[7](「一等奖是一辆凯迪拉克。想看看二等奖吗?二等奖是一套牛排刀。三等奖是——你被解雇了。明白了吗?现在还笑得出来吗?」)同理,对于团队而言,当个体成员的努力难以观察,且有效的行动方案未知时,除了合伙人式的利润共享机制,可能别无更优的选择。
[7] 常言道,「好运胜过好本领」,因为有本领的人往往运气也不差,而那些运气不佳但有本领的人可能只是看起来有本领。尤其是在因果关系密集、不透明或瞬息万变的环境中,迷信地模仿幸运儿、排斥倒霉蛋——即便其厄运明显源于掷骰子之类的外部因素——或许是一种有效的启发式策略!(如果你迷信地沿袭旧法,也许就不会因为煮沸了柠檬汁中的维生素 C 而死于坏血病。)自然界信奉严格责任制。(人类或许也是如此。)
在强化学习中,这对应着黑箱/无梯度方法,尤其是演化方法。例如,Salimans 等人 2017 年的研究就采用了一种演化方法:数千个参数被轻微随机调整过的神经网络同时玩一个雅达利游戏,游戏结束后,根据所有网络的最终得分,计算出一个新的平均神经网络;整个过程完全不去探究哪些具体的参数变动是好是坏,甚至不去寻求一个可靠的评估——它们只管运行,得分是多少就是多少。如果我们把优化过程想象成一个流程图:「模型 → 模型参数 → 环境 → 决策 → 结果」,那么演化则将这个链条压缩为纯粹的「模型 → 结果」;你输入一大批可能的模型,然后得到一批结果,最后挑出那些结果最好的模型即可。这种方法像演化一样,简单粗暴地低效,但最终也简单粗暴地有效。
一种样本效率更高的方法会是像 REINFORCE 这样的算法,Andrej Karpathy 曾用一个玩《乓》(Pong)的智能体对此做过解释;REINFORCE 是如何将这个黑箱撬开一条缝的呢? 即便如此,这个算法的原理依然反直觉,能奏效本身就堪称奇迹:
训练的具体流程如下:我们会用一组初始权重 W1 和 W2 来初始化策略网络,然后让它玩100局《乓》游戏(我们称之为策略「展开」)。假设每局游戏包含200帧,那么我们总共就做出了20,000次向上或向下的决策。对于每一次决策,我们都知道其参数梯度,这个梯度告诉我们,如果想在未来鼓励在该状态下做出同样的决策,我们应该如何调整参数。现在,剩下的工作就是给我们做出的每一个决策贴上「好」或「坏」的标签。举个例子,假设我们赢了12局,输了88局。我们会把获胜局中做出的全部 200 × 12 = 2400 次决策,都进行一次正向更新(即在我们采取的行动所对应的梯度上填入+1.0,然后进行反向传播和参数更新,以鼓励我们在这些状态下做出的选择)。同时,我们会把另外那 200 × 88 = 17600 次在败局中做出的决策,都进行一次负向更新(即抑制我们当时所做的一切)。然后……就大功告成了。这样一来,网络就会略微更倾向于重复那些曾奏效的行动,而略微避免重复那些失败的行动。接下来,我们用这个略有改进的新策略再玩100局游戏,如此周而复始,循环往复。
策略梯度:运行一个策略一段时间。观察哪些行动带来了高回报。然后增加它们的概率。
如果你仔细琢磨这个过程,就会发现一些奇怪的特性。比如,假设我们在第 50 帧做出了一个正确行动(漂亮地把球打了回去),但在第 150 帧却失手了。既然我们最终输了,导致所有行动都被贴上「坏」的标签,那难道不会导致连第 50 帧的正确回球也受到抑制吗?你说得没错——确实会。然而,当你从成千上万局游戏的宏观视角来看,正确地打出第一球会让你在后续的比赛中获胜的概率略微增加。因此,平均下来,你会发现正确的击球动作得到的正向更新总会多于负向更新,最终你的策略还是会学会做正确的事。
……我没有花太多时间调整超参数,并且实验是在我那台(慢吞吞的)Macbook 上跑的。但在训练了 3 个晚上之后,我最终得到了一个比游戏自带的 AI 对手略胜一筹的策略。总共的训练回合数大约是 8,000 次,这意味着算法玩了大约 200,000 局《乓》游戏(相当多了,不是吗!),并总共执行了约 800 次参数更新。
这与演化方法的区别在于,其信度分配过程能够利用反向传播技术,深入神经网络内部,直接调整那些对最终被判定为「好」或「坏」的决策有贡献的参数。它绕过了追溯每个决策具体后果并为其贴标签的难题,采用了一种简单粗暴的法令式方法:「所有在最终获胜的对局中所采取的行动,都是好的」,而「一旦对局最终失败,则所有行动都是坏的」。在这里,我们优化的流程更像是「模型参数 → 决策 → 结果」;我们输入参数以获得决策,并假设这些决策导致了最终结果,然后反向追溯,以挑选出那些能带来最佳结果的参数。
这套逻辑依然疯狂,但它确实有效,而且比朴素的演化方法更胜一筹:Salimans 等人 2017 年的研究将他们的演化方法与更标准的(基于 REINFORCE 策略梯度方法的更复杂版本)方法进行了比较,结果表明,即便是这种对反向传播技术极其有限的运用,也足以将信度分配所需的样本量减少 3 到 10 倍,在更困难的问题上,提升则更为显著。
我们还能做得更好吗?当然可以。声称一局游戏中所有行动都决定了最终结果,这种说法是荒谬的。因为环境本身是随机的,许多决策要么无关紧要,要么其真实的好坏与最终结果恰恰相反。为了做得更好,我们可以对环境本身进行建模,把它也当作一个可以被剖析的白箱,从而将决策与环境联系起来。这便是基于模型的强化学习方法,其中一个著名的例子就是 PILCO。
在 PILCO 算法中,系统会通过一个强大的模型(在该案例中,是一种非神经网络模型——高斯过程)来学习环境的模型。这个学到的环境模型随后被用于规划:从一系列可能的行动序列开始,通过模型进行推演,预测将会发生什么,然后直接优化这个行动序列以最大化预期回报。从最终回报出发,我们可以一路追溯:回报部分由环境导致,环境部分由所选行动导致,而行动又由模型参数导致。所有这些影响链条都可以被完整地追溯回最初的参数。(这是一层层往下,全是白箱。)在这里,完整的「模型 → 模型参数 → 环境 → 决策 → 结果」优化流程得以完全展现,信度分配也得以作为一个整体被正确地执行。
其结果,是业界顶尖的样本效率:在车杆平衡这类简单问题上,PILCO 仅需短短 10 个回合便能学会,而像策略梯度这类标准的深度强化学习方法,即便花上 10,000 个回合也可能难以解决。
当然,像 PILCO 这类基于模型的强化学习方法,其问题在于,它们在正确性和样本效率上的所得,都要以巨大的计算开销为代价来偿还:我无法将 PILCO 的样本效率与 Salimans 等人的雅达利游戏实验,乃至 Karpathy 的《乓》实验进行比较,原因很简单,PILCO 根本无法在比车杆平衡复杂太多的问题上运行。
于是,我们便陷入了一个令人痛苦的两难困境:只要能实现更精确、更细粒度的信度分配——即不再依据单一、遥远且充满噪声的二元结果来评判数十亿个决策,而是能将产生每个决策的算法通过其后续所有决策和结果的全部影响链条,一路追溯到最终的回报——那么,样本效率能够比演化方法高出好几个数量级。然而,这些更优越的方法却无法被直接应用于复杂问题。我们该何去何从?
走向元学习
……那些促成了最成功归纳推理的思维模式,会通过自然选择逐渐占据主导地位。那些在归纳上总是犯错的生物,有一种可悲却也值得称道的倾向——在繁衍后代前就先行消亡……在归纳推理的领域,唯有成功才能带来更大的成功。
——W. V. O. Quine, 《自然类》 1969
谈到演化算法与样本效率,人工智能与强化学习领域中一个引人入胜的方向是「元学习」,它通常被描述为「学习如何学习」(Botvinick et al 2019)。元学习将给定的学习任务重构为一个双层问题:我们首先为某一类问题寻找一个元算法,然后这个元算法能够在运行时,根据手头的具体问题进行快速适应。(用演化的术语来说,这可以看作与鲍德温效应相关。)元学习领域存在多种范式,运用了各类学习器与优化器;关于近期的几种范式,可参见 Metz et al 2018 的表1(见本文附录)。
举个例子, 我们可以训练一个循环神经网络(RNN)来解决一个「T 型迷宫」任务,其中奖励会不时地在左、右臂之间随机切换。RNN拥有记忆,即它的隐藏状态。因此,当它尝试了几次左臂却一无所获后,它可以在其隐藏状态中编码这样一个信息:「奖励已经切换到了右边」,然后便决定之后每次都走右臂,并同时记录切换后的失败次数。当奖励再次切换回左臂时,在右臂经历数次失败后,那个被学到的规则就会被触发,促使它重新转向左臂。如果没有这种序列学习能力,假如它只是在一堆混杂的样本上进行训练——其中一半的「左」有奖励,一半的「右」也有奖励(因为奖励在不停切换)——它最终只会学到一个糟糕的策略,比如 50-50 随机选择,或者永远只走一边。另一种方法是「快速权重」:一个初始的元神经网络观察来自新问题的几个数据点,然后为一个新的、专门针对该问题的神经网络生成调整后的参数。这个新网络随后被精确地执行并获得奖励,这样,元神经网络就能学会如何生成在所有问题上都能获得高回报的参数。MAML 元学习算法 (Finn et al 2017)可以看作是这种思路的一个版本。它会学习一个元神经网络,这个网络被精心调校,使其在所有可能的子网络之间达到一种平衡。这样一来,在新问题中只需进行几步梯度下降的微调,就能将其迅速「特化」到该问题上。(你可以将这个元神经网络想象成高维模型空间中的一个点,它与大量针对单一问题训练出的神经网络大致等距。在这个点上,只需微调少数几个控制全局行为的参数,便可快速适应,而这些参数正是需要从初始经验中学到的。)总的来说,元学习通过在不同环境之间进行低效(甚至可能非贝叶斯)的训练,来学会在特定环境之内成为更优的贝叶斯智能体 (Ortega et al 2019)。正如 Duff 2002 所言:「对于我后续提出的计算过程,一种理解方式是,它们为一个在线的、自适应的机器,执行了一次离线计算。我们可以将『为超状态空间上定义的马尔可夫决策过程逼近一个最优策略』这一过程,看作是『编译』一套最优的学习策略,而后便可将其『载入』智能体。」
这个「编译」的比喻,揭示了元学习的一种深刻视角:这些系统所进行的是摊销优化,而非在运行时去解决完整的贝叶斯最优决策问题。在这里,「摊销」一词比「缓存」更为精确——我们讨论的并非在内存中存储答案,而是通过将计算成本分摊到大量的训练回合中,学会如何高效地执行某一计算过程。经过元学习的智能体,逐渐学会实现与贝叶斯最优行动等价的计算,而这些计算最终可能被简化为惊人地简单的算法,例如,仅仅追踪一个足以概括全部历史的充分统计量。
例如,在T型迷宫的例子中,RNN并非在每一步都对完整的部分可观察马尔可夫决策过程(POMDP)进行显式推理,也非为每一个可能的观察与推断序列构建决策树并进行反向归纳来计算最优行动(这种方法计算量巨大,很快会变得不可行,AIXI 便是如此)。相反,它学到的是一个摊销式的策略,其本质可能简化为「计算近期失败次数,并在犯错 n 次后转换方向」——这实际上是将复杂的贝叶斯推理,「编译」成了一个快速的启发式算法。Transformer 似乎在其层级中实现了一种梯度下降的形式,在预训练阶段学到的抽象表征上执行小步的推理。同样,在 AlphaZero 风格的专家迭代中,神经网络执行的是对所有先前蒙特卡洛树搜索(MCTS)过程的一个摊销版本,并通过额外的树搜索来优化这些评估,再将优化结果摊销回网络中。
摊销优化这一视角(更广泛的综述可参见 Ghavamzadeh et al 2016)揭示了元学习是如何在样本效率低但无偏的外部优化与高效但可能存在偏差的内部优化之间,架起了一座桥梁:通过反复的历练,系统不仅学会了做什么,更学会了如何在其所处领域内高效地学习,将推理与行动融为一体,形成迅速、近乎本能的反应,而这些反应却能逼近贝叶斯最优。
DeepMind的论文 Jaderberg et al 2018 便是一个有趣的例证。该研究展示了一个采用双层方法训练的《雷神之锤》(Quake)团队第一人称射击游戏智能体(Leibo et al 2018 则通过引入多种群对此方法做了进一步扩展;相关背景可参见 Sutton & Barto 2018;一篇演化视角的宣言式文章可参见 Leibo et al 2019)。这一方法对于他们在2019年1月公布的AlphaStar《星际争霸II》智能体也至关重要。这款射击游戏是多人夺旗赛,团队在同一张地图上竞技,而非单个智能体在死亡竞赛中各自为战。因此,学习与多个自我副本进行协调乃至显式沟通,是一件非常棘手的事。常规的训练方法效果不佳,因为一次更新会同时改变所有自我副本,从而破坏任何已学到的通信协议的稳定性。Jaderberg 团队的做法是:在每个智能体内部,使用标准的深度强化学习技术,依据夺旗或攻击等行为获得的得分,在每局游戏中预测和接收奖励;但在此之上,由 30 个智能体组成的整个种群,在每轮比赛结束后,会经历第二层级的选择。这一选择的依据是最终的比赛得分或胜负,而它所作用的对象,则是智能体自身的内部奖励预测机制及超参数。
这可以被看作一个双层强化学习问题。内部优化旨在最大化,即智能体对未来折扣内部奖励的期望值。而对
的外部优化则可被视为一个元博弈,其目标是,针对内部奖励方案
和超参数
,来最大化赢得比赛这一元奖励,而内部优化则提供了这个元博弈的转移动态。我们采用前述的强化学习来解决内部优化问题,并采用基于种群的训练(PBT)(29) 来解决外部优化问题。PBT 是一个在线的演化过程,它通过用表现更优智能体的变异版本来替换表现不佳的智能体,从而调整内部奖励和超参数,并进行模型选择。这种将智能体策略的强化学习优化,与强化学习过程本身(为了一个更高层级的目标)的优化相结合的联合优化方法,被证明是一种有效且普适的策略,并利用了在大型学习系统中将学习与演化相结合的巨大潜力(2)。
最终目标是获胜,基准真相的奖励是胜负结果,但仅仅从胜负中学习,效率极低:这区区1比特(甚至更少)的信息,必须被分摊到游戏中所有智能体的所有行动上,并用于训练拥有数百万个相互依赖参数的神经网络,其效率之低下尤为突出,因为人们无法从最终胜负直接计算出精确梯度,并反向传播到该负责的神经元。相比之下,游戏内的得分是一种信息密度高得多的监督信号,它数量更多,且与短暂的时间片段相对应,从而允许在每局游戏内部进行更充分的学习(甚至可能使用精确梯度)。但问题是,它与最终的胜负只有间接关系;一个智能体可能会只顾自己刷分,却忽略了与敌人交战或与队友协调,最终导致团队失败;或者,团队可能会学到一个贪婪的策略,初期表现良好,长远来看却会落败。因此,这个双层问题正是利用了缓慢的「外部」信号或损失函数(获胜),来塑造那个负责大部分学习任务的、更快速的「内部」损失函数。(「生物是适应策略的执行者,而非适应度的最大化者。」)一旦快速的内部算法学偏了、失控了或掉入了陷阱,外部奖励最终会纠正这个错误,它会通过变异或抛弃这些失败的智能体,转而青睐更成功的血统。这种方法将演化那套粗糙、缓慢但坚韧不拔的优化方式,与基于梯度的、更快、更巧妙但可能误入歧途的优化方式结合起来,从而创造出一个能更快达到正确目标的系统。(另外两个近期的例子是代理梯度/合成梯度。)
双层元学习
……(科学中)决定性的现象在于,科学家会批判并扼杀自己的理论。科学家努力淘汰自己的错误理论,努力让理论代替自己去死。而信徒——无论是动物还是人——则会与自己错误的信念一同灭亡。
——Karl Popper (1968)
Cosma Shalizi 在别处,津津乐道于指出自然选择、贝叶斯统计(尤其是粒子滤波)和市场之间的形式共通性。在这些模型中,一个等位基因的种群频率,对应着一个参数的先验概率或一个交易者的初始财富;而适应度差异或利润,则对应着基于新证据的更新,其形式通常是乘法更新。(另可参见 Evstigneev et al 2008/Lensberg & Schenk-Hoppé 2006, Campbell 2016, Czégel et al 2019;顺便一提,历史上 Galton 在尝试为演化建模时,曾发明了类似近似贝叶斯计算(ABC)的方法。)尽管一个参数的初始先验概率可能错得离谱,但随着不断的更新,其后验概率终将收敛于真实值。(一群持有固定但有噪声信念的个体,与汤普森采样之间的关系也颇为有趣:Krafft 2017。我们是否可以将那股前赴后继、不断尝试「失败」点子并偶尔大获成功的创业潮,看作是一种集体汤普森采样,其效率远比表面看起来要高?)而随机梯度下降(SGD)可以被看作是暗地里在估计其梯度,从而实现了一种对贝叶斯更新的近似或变分形式(难道万物有效皆因其符合贝叶斯之道?)。当然,演化方法也可以被看作是在计算梯度的有限差分近似……
| 模型 | 参数 | 先验 | 更新 |
|---|---|---|---|
| 演化 | 等位基因 | 种群频率 | 适应度差异 |
| 市场 | 交易者 | 初始财富 | 利润 |
| 粒子滤波 | 粒子 | 种群频率 | 接受/拒绝采样 |
| SGD | 参数 | 随机初始化 | 梯度步进 |
表:不同优化/推理模型之间的类比。(更多内容,可参见 John C. Baez 的「信息几何」,该文探讨了如何通过信息几何统一演化、贝叶斯推理和梯度下降。)
这种模式同样浮现在我们讨论过的其他例子中。这种双层学习正类似于元学习:外部的元算法学习如何生成一个内部的对象级算法,而这个内部算法能够比元算法本身更高效地学习。内部算法自身又能学习到更好的算法,如此层层递进,随着每一层级的特化,系统获得更强的能力、更高的计算效率或样本效率。(「小伙子,这可是一层又一层的优化器!」)这也类似于人体内的细胞:整体的繁殖适应度是一个缓慢的信号,一生中最多只出现寥寥数次,但历经多代演化,它构建出能快速反应的发育和稳态过程,这些过程能塑造一个高效、强大的身体,并在几分钟而非数千年内响应环境波动,而大脑在处理瞬时情境时则更为出色。这也类似于市场中的公司:公司内部可以随心所欲地使用各种算法,如线性优化或神经网络,并依据「日活跃用户」等内部指标对其进行评估;但最终,这一切都必须转化为利润……
公司需要解决的核心问题是,在缺乏直接的、端到端的损失信号,且不依赖缓慢的外部市场机制的情况下,如何去激励、组织、惩罚和奖励其下的各个部门及员工。解决之道包括:利用同伴尊重等社会机制(士兵并非为国而战,而是为战友而战);筛选那些有内在动力去创造价值而非混日子的员工;通过口号宣传、员工手册或公司歌曲等方式,不断尝试灌输「企业文化」;使用多种代理指标进行奖励,以减少古德哈特式的钻空子行为;采用股票期权等临时机制,试图将市场损失内化为员工的切身感受;通过外包或自动化来替代员工;收购那些内部尚未腐化的小公司,或以此作为一种人才筛选机制(「人才收购」);利用知识产权或法规保护……所有这些技术结合在一起,才能够将各个部分整合为一个有用的整体,最终创造出可供销售的价值……
谋事在人,成事在天
……否则,公司终将破产:
破产,伟哉:它是一道万丈深渊,一切虚伪,无论公私,终将沉沦其中,烟消云散;从其诞生之初,这便是它们注定的归宿。因为自然是真实的,而非谎言。你所说的、所行的任何谎言,在流转或长或短的时日后,都如同一张向「自然实在」开出的期票,终将被呈上要求兑付——而得到的回答是:查无此款。可叹的只是,这张期票常常流转得太久;最初的造假者,却往往不是最终承受苦果之人!谎言,及其带来的罪恶重负,被层层转嫁,从一个肩膀卸到另一个肩膀,从一个阶层推给另一个阶层,最终压在那些沉默的底层大众身上。他们,用铁锹和锄头,怀着破碎的心和空瘪的钱包,日复一日地与现实短兵相接,已无法再将这骗局传递下去。
……然而,若口袋里揣着福尔图纳图斯的钱袋(一个取之不尽的魔法钱袋),那么几乎任何虚伪又能持续多久呢!你的社会、你的家庭、你的任何属世或属灵的建制,若是不真实的、不公义的,在神与人眼中都是可憎的。但即便如此,只要它的炉火依旧温暖,它的粮仓依旧充盈,那么无数来自天国的瑞士雇佣兵,便会怀着一种天然的忠诚聚集在它周围,用笔杆和火枪来证明它就是真理;即便不是纯粹的(不食人间烟火、不可能存在的)真理,那也是一种更好的、有益健康的、调和过的真理(正如和风之于刚剪过毛的羔羊),并且运转良好。然而,当钱袋和粮仓都空空如也时,前景便截然不同了!你的那套建制果真如此真实,如此顺应自然之道吗?那么,请问,拥有无限慷慨的自然,又怎会任其在此忍饥挨饿?此刻,对所有男人、女人和孩子而言,你的建制是虚假的,这一点已昭然若揭。向破产致敬!在宏大的尺度上,它永远是正义的,尽管在细节中它如此残酷!它在一切虚伪之下不懈地掘进。没有任何虚伪,哪怕它高耸入云、遮蔽世界,能逃脱破产的扫荡,它终有一日会将其夷为平地,还我们自由之身。^[《法国大革命:一部历史》,作者 Thomas Carlyle。]
一家像西尔斯这样的大公司可能需要几十年才会消亡(亚当·斯密曾言:「一个国家家底雄厚,经得起百般折騰」),但它终究会消亡。公司的绩效无法像选择性育种或人工智能算法那样,实现迅速而持续的提升,因为它们无法像数字神经网络或生物细胞那样精确地复制自身。但尽管如此,它们仍然是一个双层过程的一部分:一个基于基准真相、无法作弊的外部损失函数,在某种程度上约束着其内部动态,从而维持着一条底线,甚至可能随着时间的推移带来些许温和的改进。计划,终究要被供求关系所「检验」,正如托洛茨基在批判斯大林放弃新经济政策等政策时所说:
倘若存在一个寰宇之心,如同拉普拉斯在科学幻想中构想的那般——一个能够同时记录自然与社会的一切进程,能够度量其运动之态势,能够预见其相互作用之结果的心智——那么,这样一个心智,当然可以先验地擘画出一份完美无瑕、详尽无遗的经济计划,从需要多少亩小麦,直到上衣的最后一粒纽扣。官僚体系常常幻想自己就拥有这样一个心智;这便是为何它能如此轻易地摆脱市场与苏维埃民主的控制。但实际上,官僚体系对其心智能力的估量,错得离谱。
……经济体中无数鲜活的参与者,无论是国家还是私人,集体还是个人,都必须宣告他们的需求和相对力量,这不仅要通过计划委员会的统计数字,更要通过供求关系的直接压力。计划通过市场来检验,并在相当程度上通过市场来实现。
唯有痛苦才是良师
别跟我说什么上帝的旨意深不可测……他到底为什么要创造痛苦?……哦,他赐予我们痛苦,可真是对我们大发慈悲啊!他为什么就不能用门铃来提醒我们呢?或者派他那天使唱诗班来也行啊?或者干脆在每个人的额头正中间,装一套红蓝霓虹灯系统。任何一个像样的点唱机制造商都能做到。他为什么就不能呢?……真是个惊天动地、永垂不朽的蠢货!
——队长 Yossarian, 《第 22 条军规》
痛苦是一种奇特的现象。既然痛苦很容易演变成慢性疼痛等棘手问题,为何我们拥有的是这种令人痛苦不堪的痛,而非一种更中性、无痛感的痛?为何我们会有痛苦这种机制,而不是依靠常规的学习过程,或是在执行计划时体验奖励?
我们能否将痛苦也理解为一个双层学习过程?其中,一个缓慢但基于基准真相的外部损失函数(即「中央调控器」),约束着一个快速但并不可靠的内部损失函数。我认为,痛觉信号本身并非外部损失函数,但痛苦的那种「折磨感」,即其强烈的、驱使人行动的特性,才是其成为外部损失函数的关键。从逻辑上讲,痛觉未必非得是痛苦的,但那样将不具适应性,也不切实际,因为它会轻易地让内部损失函数引导我们做出自毁行为。
痛苦分类学
那么,让我们来探讨一下痛苦的各种可能性。世上并非只有一种「痛苦」。至少存在以下几种:
- 无益但令人痛苦的痛楚(如慢性疼痛、运动后的酸痛)
- 有益且令人痛苦的痛楚(常规类型)
- 无益且无痛感的损伤(如糖尿病或麻风病中的神经坏死,或先天性无痛症;褥疮和重复性劳损则是日常的例子,它们表明,即便是「躺在床上」这种最无害的活动,实际上也在持续对身体造成损害)
- 有益的无痛感(如战斗中肾上腺素飙升,暂时屏蔽痛觉)
- 无益但无折磨感的痛楚(如痛觉失认症,患者会自残甚至致死;可能也包括莱施-尼亨综合征);
- 以及中间状态:比如 Marsili 家族,他们因基因突变 (Habib et al 2018),痛觉感知受到部分损害。Marsili 家族成员确实能感受到有益的、令人痛苦的痛楚,但感觉非常短暂。他们因此遭受了大量身体损伤(骨折、疤痕),但避免了那些神经坏死或痛觉失认症患者所经历的最恐怖的遭遇。
另一个有趣的案例是苏格兰女性 Jo Cameron,她体内的内源性大麻素系统存在另一组不同的突变(FAAH & FAAH-OUT)。虽然情况不像神经病变那么严重,但她仍表现出类似症状——除了异常健忘等奇怪症状外,她的父亲也可能是基因携带者且死因奇特;她在家务中经常烫伤或割伤自己;童年时玩轮滑摔断了手臂,却直到骨头以一个「奇怪的角度」愈合后才去就医;髋关节和手部关节炎的损伤都拖延到几乎为时已晚才去治疗(她的关节之所以受损如此严重,可能正是因为缺乏痛觉);她收养的寄养儿童还偷走了她的积蓄,等等。她的儿子遗传了她两个突变中的一个,「经常用热饮和食物烫伤自己的嘴」。 (生物学家 Matthew Hill 将最常见的 FAAH 突变描述为会导致「低水平的焦虑、健忘、乐天派的性格」,并且「自从论文发表后,Matthew Hill 已经与六位无痛症患者交流过,他告诉我,与 Jo Cameron 相比,他们中的许多人似乎都有点古怪。」) 一个可能的案例是多产到荒谬的奇幻作家 Brandon Sanderson,他常年每天打字 8 小时(而且还是在沙发上),后来发现他几乎完全对疼痛不敏感。 - 但是——是否存在「有益但无折磨感的痛楚」或「无益但令人痛苦的非痛感」?
事实证明,「无折磨感的痛楚」是存在的:接受过脑叶切断术的人便体验过。医学上用「反应性分离」来描述吗啡等镇痛剂有时在疼痛开始后使用所产生的效果。引用 Dennett 1978 的描述(着重号为原文所有),患者会报告说:「在接受镇痛剂后,受试者通常报告的并非疼痛消失或减轻(像阿司匹林那样),而是疼痛一如既往地剧烈,只是他们不再在乎了……如果镇痛剂在疼痛发作前使用……受试者则声称之后没有感到任何疼痛(尽管他们并未麻木或被麻醉——身体相关部位仍有感觉);而如果吗啡在疼痛开始后使用,受试者则报告疼痛仍在持续(且持续是痛的感觉),只是他们不再在乎了……接受过脑叶切断术的受试者同样报告感到剧痛但不在乎,在其他方面,脑叶切断术与吗啡的效果也足够相似,以至于一些研究人员将吗啡(及某些巴比妥类药物)的作用描述为『可逆的药物性脑白质切除术[脑叶切断术]』。」
我们还能找到「令人痛苦的无痛感」的实例:Grahek 2001 的文章重点介绍了一项案例研究 Ploner et al 1999。研究中,一位德国患者因中风导致其躯体感觉皮层受损,使其身体一侧无法正常感知热量,也感觉不到任何由热引起的痛点或热点。尽管如此,当足够的热量施加于他手臂的某一点时,患者会变得愈发焦躁,并描述一种与他整条手臂相关的、「明显不愉快」的感觉,但他同时否认这种感觉包含任何皮肤蚁行感,也拒绝使用「微痛」或「灼烧感」等词汇来形容。
一张表格或许有助于厘清这些可能性:
| 功用性 | 负面驱动性 | 主观感受状态 | 举例 |
|---|---|---|---|
| 无益 | 痛苦 | 痛感 | 慢性疼痛;运动后的酸痛? |
| 有益 | 痛苦 | 痛感 | 正常情况/受伤 |
| 无益 | 不痛苦 | 痛感 | 痛觉失认症 |
| 有益 | 不痛苦 | 痛感 | 反应性分离、脑叶切断术;运动后的愉悦感? |
| 无益 | 痛苦 | 非痛感 | 无意识过程(如术中知晓);痒或挠痒感;顺行性遗忘症?^[顺行性遗忘症患者尽管记忆受损,有时痛觉也较迟钝,但似乎仍能学会将不愉快的刺激与恐惧或疼痛联系起来,这使其成为一个临界案例:其厌恶感持续的时间,超过了被(记住的)主观感受。] |
| 有益 | 痛苦 | 非痛感 | 冷/热感知(如躯体感觉皮层损伤案例) |
| 无益 | 不痛苦 | 非痛感 | 疾病(糖尿病、麻风病)、受伤、药物(麻醉剂)导致的神经坏死 |
| 有益 | 不痛苦 | 非痛感 | 肾上腺素飙升/事故/战斗中的非痛感 |
表:一种可能的「痛苦」分类法,依据其对生物体的后果、驱动效果,以及当事人报告的主观体验(或无体验)划分。
痛苦服务于一个明确的目的(阻止我们从事可能损害身体的行为),但其方式却是一种奇特而执拗的,我们无法主动关闭。而且,它还日益频繁地以「慢性疼痛」等形式,损害我们的长远利益。 为什么痛苦不像一种警告,或者不像饥饿、口渴那样运作呢? 饥饿和口渴也会打断我们的思绪,但就像电脑的弹窗,经过一番权衡利弊后,我们通常可以选择忽略它们。 而痛苦,则是一种无法被忽略的干扰。尽管我们不难想象一种可以被忽略、甚至带来「愉悦感」的痛苦(Morsella 2005):
理论上,神经机制本可以通过其他方式演化,来满足这种特定交互的需求。除了那些行为与人类无异但没有主观体验的自动机,我们还可以设想一个有意识的神经系统,它能像人类一样运作,却没有任何内部冲突。在这样的系统中,指导骨骼肌行动的认知,将与主观感受的性质完全相符——为了取水而跑过灼热的沙漠,实际上会让人感觉很愉悦,因为这个行动被判定为具有适应性。^[这方面一个可能的具体实例,是厌食症的反饥荒理论:厌食症患者发现,即便在感觉「良好」或「神圣」的情况下,也能轻易地进行高强度运动并将自己活活饿死——而且他们常常不想被治愈,因为他们正在身不由己地执行一套最后关头的反饥荒适应策略,这套策略本是为了长途跋涉迁徙到更丰饶的土地而设计的。]我们的神经系统为何不以如此和谐的方式运作?这或许是一个只有演化生物学才能回答的问题。当然,人们可以想象这种整合在完全没有主观体验的情况下发生,但从目前的立场来看,这更多地反映的是一个人的想象力,而非演化史上真实发生过的事情。
惠能的幡
在强化学习的语境中,人们不禁要问:奖励函数采用「负奖励」还是「正奖励」,究竟有何区别?任何一个同时包含正负奖励的函数,都可以通过加上一个足够大的正常数,轻易地转化为一个纯正奖励函数。这算是一个有实质意义的区别吗?或者说,与其说最大化「奖励」,我们也可以说最小化「损失」——在经济学、决策论或控制论中,人们也常这么做。
Tomasik 在 2014 年的文章「强化学习智能体是否具有道德意义?」中,鉴于成本/损失与奖励之间的对偶性,探讨了奖励与「受苦」或「痛苦」等伦理考量之间的关系:
相比于选择何种算法,一个更紧迫的改进或许是在既定算法中用奖励来取代惩罚。不同的强化学习系统,在使用正奖励、负奖励或两者兼有的方式上有所不同:
- 在某些 RL 问题中,如 Sutton & Barto 1998 年中讨论的迷宫导航任务,奖励只有正值(当智能体到达终点时)或零(其他情况)。
- 有时会混合使用正负奖励。例如,McCallum 1993 年的实验将一只模拟老鼠放入迷宫,到达终点奖励为 +1,撞墙为 -1,其他任何动作则为 -0.1。
- 在另一些情况下,奖励永远是负值或零。例如,在 Barto et al 1990 年的车杆平衡系统中,智能体收到的奖励一直是0,直到杆子倒下,那一刻奖励变为 -1。在 Koppejan & Whiteson 2011 年用于直升机控制的神经演化 RL 方法中,智能体受到的惩罚要么较小(直升机实际位置与目标位置的平方差负和),要么极大(如果直升机坠毁)。
正如对动物福祉的关切,会促使人们在训练狗 [Hiby et al 2004] 和马 [Warren-Smith & McGreevy 2007, Innes & McBride 2008] 时采用奖励而非惩罚,对 RL 智能体福祉的考量,同样可以促使我们为人工智能学习者采用更积极的训练方式。Pearce 2007 年曾设想,未来的智能体将由「幸福感梯度」(即不同强度的积极体验)而非苦乐之别来驱动。然而,对于简单的RL系统,积极福祉与消极福祉之间的道德界限究竟在何处,并不十分清楚。我们或许会认为,单凭奖励值 r 的正负号便可区分,但仅有符号可能并不足够,原因如下。
积极福祉与消极福祉的界限何在?
设想一个生命周期为 T 个时间步的 RL 智能体。在每个时间点 t,智能体根据其采取的行动 a~t~,会收到一个非正奖励 r~t~ ≤ 0,正如车杆平衡的例子。智能体选择其行动序列 (a_t_) t = 1...T,以最大化未来奖励的总和:

现在,假设我们通过给每个奖励加上一个巨大的正常数 c 来重写奖励函数,得到 r′~t~ = r~t~ + c,且_c_足够大,使得所有新的奖励值 r′~t~ 均为正。那么,智能体现在的优化目标是:

我们可以看到,最优的行动序列在两种情况下是完全相同的,因为一个加性常数并不影响智能体的行为。^但如果行为完全相同,那么唯一改变的只是奖励数值的符号和大小。然而,若说幸福与痛苦的区别,仅仅取决于算法所用的数字前面是否碰巧带了个负号,这未免太过荒谬。毕竟,在计算机的二进制表示中,负数并没有负号,只是另一串0和1而已,而在硬件层面,其表现形式又有所不同。更重要的是,如果智能体先前会对有害刺激做出规避反应,那么在奖励函数改变后,它仍会继续如此。正如 Lenhart K. Schubert 所解释的:^[此引文出自一门名为「机器与意识」的课程 2014 年春季的讲义(访问于 2014 年 3 月)。]
如果仅仅是(为了让负奖励变为正而)平移坐标原点,并未引起任何行为上的改变,那么这个机器人(analogously, a person)在受伤或身处困境时,依然会表现得如同在受苦一般,大声呼救等等。如此看来,痛苦似乎并未被消除!
那么,究竟是什么区分了快乐与痛苦?
……一个更合理的解释是,这种区别与「规避」和「寻求」有关。负面体验是智能体试图摆脱,并在未来尽量少做的。例如,受伤本身应是一种内生的负面体验,因为如果修复伤口对智能体而言是种奖励,那么它就会主动寻求受伤,以便能更频繁地进行修复。而如果我们试图奖励规避伤害,那么智能体又会去主动寻求危险情境,以便能享受回归安全所带来的快感。[此例出自 Lenhart K. Schubert 的「机器与意识」课程 2014 年春季讲义(访问于 2014 年 3 月)。这些思想实验并非纯粹的纸上谈兵。当人们对自残所释放的内啡肽上瘾时,我们便看到了一个因快乐与伤害相关联而导致的适应不良行为的真实例子。] ^[在过往的 RL 研究中,有一些「奖励操纵」的案例与这种「自残」智能体颇为相似——例如,一个自行车智能体因接近目标而获得「奖励」(但远离目标并不会受「惩罚」),于是它学会了绕着目标不断转圈,以反复获取奖励。]伤害必须是智能体想要尽可能远离的东西。因此,举例来说,即便因食物中毒而呕吐是你当前处境下的最佳对策,这种体验也应是负面的,以劝阻你日后不要再吃变质食物。然而,「规避」与「寻求」之间的界限也并非总是那么清晰。我们因寻求和享用食物而感到快乐,但同时也因痛苦而有动力去规避饥饿。寻求一物,往往等同于规避另一物。车杆平衡智能体也是如此:它是在寻求一根平衡的杆子,还是在规避一根倒下的杆子?
……这一切,让我们的车杆平衡智能体情何以堪?它是在持续不断地受苦,还是在享受自己的努力?同理,一个旨在积累正奖励的 RL 智能体,它是在享受乐趣,还是在奖励未能达到最优时,正备受煎熬?
痛苦:锚定现实的基石
那么,有了以上种种背景,痛苦的目的究竟是什么?
我认为,痛苦的目的是作为一种基准真相,或一个外部损失函数。(这是一种痛苦的动机理论,但融入了更复杂的强化学习与精神病学基础。)
痛苦这种奖励/损失机制无法被完全移除,其原因已由那些糖尿病、麻风病及先天性无痛症患者的遭遇所证明:被忽视的伤害和糟糕的规划,最终是致命的。若没有痛苦的主观感受让痛觉变得「痛苦」,我们便会做出有害的行为,比如拖着断腿奔跑,或为了在朋友面前炫耀而从屋顶跳下[^Pakistan],又或者只是日复一日地以一种不太正确的姿势活动,然后在几年后落得半身不遂。(单凭内在的好奇心驱动,若与完全无痛的状态相结合,后果将不堪设想:毕竟,还有什么能比通过自残或鲁莽所能达到的那种奇特而独特的状态,更新奇、更难预测呢?)
[^Pakistan] 引自关于 Marsili 家族的文章:
> 在 2000 年代中期,Wood 在大学学院的实验室与剑桥大学一位名叫 Geoff Woods 的科学家合作,开展了一项开创性的研究,其对象是巴基斯坦北部农村的一群亲属家庭——他们都来自一个名为 Qureshi biradari 的部族。Woods 是偶然得知这些家庭的:在为一项关于小头畸形脑部异常的研究寻找潜在受试者时,他听说了一位年轻的街头艺人,一个为了取悦观众而惯常自残(走火炭、用刀刺自己)的男孩。传闻他毫无痛觉,据说他的其他家人也同样如此……当Woods找到这个男孩的家人时,他们告诉他,男孩已在一次从屋顶跳下的特技表演中,因伤势过重而死亡。
如果痛苦无法被移除,那么,它能被转化为一种奖励吗?我们能否成为 Morsella 设想的那种心智——它从不体验痛苦,只在推断并执行计划时,体验或多或少的奖励?当它跑过滚烫的沙地时,它只体验到正向奖励(愉悦感),因为根据它所构思的无论多么宏大的计划,这都是它当下应采取的最优行动。
或许我们可以……但什么能阻止 Morsella 设想的这种心智,为了享受奖励而在沙地上原地打转,直到力竭而亡或落下残疾?Morsella 的心智或许能制定一个计划,并定义一个无需任何痛苦或负面奖励的奖励函数,但如果这个计算出的计划或奖励评估存在任何瑕疵,又会发生什么?如果计划本身就基于错误的假设呢?如果沙子比预期的更烫,距离比预期的更远,或者最终的目标(比如一片绿洲)根本就不存在呢?这样一种心智,在学习和处理错误方面,引发了严峻的问题:当计划失败时,这样一种心智会体验到什么?它会毫无感觉吗?还是会体验到一种「元痛苦」?
想一想 Brand(仍引自《痛苦的礼物》,第 191-197 页)所描述的,多年来致力于研发「疼痛假肢」——一种能实时测量热量与压力,以警告麻风病或糖尿病等无痛症患者的智能手套/袜子——最终却归于失败的根本原因:病人们会完全无视那些警告,因为停下来预防未来的问题既不方便又不划算,而继续我行我素则能获得即时回报。而当系统中加入了电击装置,以阻止他们从事危险行为时,Brand 观察到,病人们竟会先把它关掉,做完危险的事,然后再重新打开!再举个不那么极端的例子,想想职业运动员吧:前途无量的职业生涯每天都在因伤病而终结,而对于 NBA 或 NFL 的顶级运动员来说,最重要的比赛技巧之一,恰恰是懂得在何时不上场。
痛苦所提供的,是一种持续不断的反馈,它将所有基于规划或自举法得出的对未来奖励的评估,牢牢地锚定在现实中。它将我们的智能,锚定在对身体完整性的具体评估之上:皮肤是否完好,细胞是否健康,肌肉有无损伤,关节是否活动自如,等等。如果我们规划得当,行动高效,那么长远来看,平均而言,我们将享受到更高水平的身体完整性与健康;反之,如果我们学习、选择和规划得一塌糊涂,那么……好日子便不会长久。恶果会逐渐显现,我们可能会发现自己双目失明、伤痕累累、半身不遂、手指残缺,并命不久矣。一种不「痛苦」的痛,无法起到这个作用,因为它将沦为另一种「痒痒」的感觉。(有些人或许会觉得有趣、愉悦,甚至可能偶然地与性快感联系起来。)我们所讨论的那些感知,不过是更普通的触觉、动觉、温觉,或其他标准的感知类别;若没有那种痛苦的痛,火烧到手上只会感觉温暖(直到热感受神经被摧毁,便再无感觉),而刀子划破皮肉或许只会感觉像一种波动的、拉伸的、摩擦的运动。
我们可以说,一种令人痛苦的痛,是一种强行将自身楔入规划/优化过程的痛,它作为一个待优化的成本项,或奖励的缺失项而存在。一种不具激励性的痛,根本就不是我们通常意义上所说的「痛」。[^Drescher]这种动机性本身,就是痛苦的主观感受,正如痒是一种普通的感知,与一种想要抓挠的动机冲动相结合。任何一种心理状态、情感或感觉,若不伴随着一种不容置辩的要求性、一种非自愿的考量,那便不是痛苦。我们心智的其他部分可以强行压制痛苦,只要它足够确信,有充分的理由去承担痛苦的代价,因为长远的回报足够巨大。我们时时刻刻都在这么做:我们可以说服自己去健身房,忍受打针的刺痛,甚至在最极端的情况下,为了活命而锯掉自己被困住的手。而如果我们错了,预期的回报并未到来,那么最终,痛苦那嘈杂但持续的反馈,将压倒那些导致痛苦的决策,而任何导致了错误决策的错误信念或模型,都将被调整,以便在未来做得更好。
[^Drescher] Drescher 2004 年在其著作《善与真》(第 77-78 页)中,对动机性痛苦给出了类似的解释:
> 但一个纯粹机械的状态,不可能具有内在可取或可憎的属性;因此,那些内在的好或坏的感觉,将与一个完全机械的心智的观念无法调和。然而,实际上,正是你的心智机器对一个状态的效用标识所做出的反应——即机器系统性地追求或规避该状态的倾向——实现并构成了那个被赋予价值的状态看似内在的、值得被追求或规避的属性。粗略地说,并非因为痛苦是内在坏的,你才(在其他条件相同时)规避痛苦;恰恰相反,是你的心智机器系统性地规避痛苦的倾向(在其他条件相同时),构成了痛苦的「坏」。当你审视一种痛苦,并察觉到它是「不可取的」、是你想要规避的东西时,你真正观察到的,正是那种系统性的倾向。
>
> 我所指的这种系统性倾向,至关重要的一点是,包含了为实现正价值状态而制定计划(并执行之),或为规避负价值状态而制定计划的倾向。相比之下,打喷嚏是对某些刺激的一种执拗反应;然而,尽管这种冲动极为强烈——打喷嚏很难被抑制——我们却不认为打喷嚏的感觉本身是强烈的愉悦(也不认为那股被喷嚏所终结的、想打喷嚏的刺痒感是强烈的痛苦)。我认为,其区别在于,我们心智机器中没有任何东西,会为了体验喷嚏(或规避那股刺痒感)而去规划如何让自己进入一个会打喷嚏的情境(也没有强烈的倾向去规划如何规避偶尔的喷嚏);机器的线路本就不是这样连接的(也不该是)。我们认为愉悦或痛苦的感觉,是那些在其他条件相同时,能促使我们去规划如何获得它们或远离它们的感觉。
但痛苦不能,也绝不能被随意压制:人类有机体是不可信的,我们不能简单地「关闭」痛苦,然后放纵自己去满足那种想把手砍下来看看的好奇心。值得注意的是,我们可以通过绝食或绝水来自杀,但我们无法通过拒绝睡眠、停止心跳或停止呼吸来自杀——除非你患有(极为致命的)中枢性肺换气不足综合征。原因在于,我们的智力不足,我们的先验知识不够强大,我们的推理和规划能力太差,我们在短暂的一生中需要学习的东西太多,以至于离了痛苦便无法生存。
类似的论点或许也适用于「意志力」和「拖延症」之谜。为何我们会有这类问题,尤其是在现代社会,总是该做的不做,不该做的反倒做了?
在「血糖水平」理论的废墟之上,Kurzban et al 2013(另见后来的 Shenhav et al 2017)建立了一套关于意志力的机会成本理论。血糖水平这类客观的生理指标,无法从机制上解释为何大脑功能会衰退,也无法解释为何像运动这类剧烈活动反而能「放松身心」、减少「倦怠」。这就像乳酸水平这类客观指标无法解释为何人们的体能总有个限度(尽管在适当激励或被欺骗时,他们能爆发出远超极限的能量)一样。既然客观指标失效,那么意志力耗尽的原因,必然是主观的。
为了解释那些与糖有关的实验观察,Kurzban 等人提出,长时间专注和认知努力所带来的厌恶感,是一种简单的启发式算法。它为「过久」地专注于任何单一任务设定了一个基准成本,以防止我们因此忽略其他潜在的机会。而那些看似能提升意志力的糖分补充(比如仅仅是尝一下糖水),实际上是作为近端的奖励信号在起作用(说是「信号」,因为其真实的能量微乎其微,而且认知努力本身并不会显著消耗卡路里)。这些信号向底层的启发式算法证明,在当前任务上继续投入是值得的,机会成本很小。
意志力的缺乏,是一种无需大脑去明确追踪、排序和规划所有潜在任务的启发式算法,它通过强迫大脑周期性地中断任务来实现这一点——「就像一个计时器在说:『好了,你现在该停了。』」^[超马选手 Diane Van Deren 将她的部分成功归因于,一次癫痫手术切除了她的一大块大脑后,她便无法感知时间流逝,因此从不感到疲倦。]如果一个人可以随心所欲地压制疲劳,后果可能不堪设想。使用安非他命等多巴胺类药物的人常会发现,他们很难将那份不知疲倦的精力投入到有用的工作中,反而会去做一些像按字母顺序整理书架之类的琐事。在更极端的情况下,如果一个人能完全忽略疲劳,那么其后果将和无痛症一样严重甚至致命:超耐力自行车手 Jure Robič 曾骑行数千公里,途中完全无视复杂的幻觉等问题,最终在一次骑行中丧生。这个「计时器」,其生物学实现机制之一,便是腺苷的逐渐积累。腺苷会产生睡眠稳态驱动压力,并可能在运动中导致身体疲劳(Noakes 2012, Martin et al 2018),从而导致我们主观上感知到的、继续工作/保持清醒/坚持运动的「成本」逐渐增加,直到我们停下/睡觉/休息时,这个成本才得以重置。(葡萄糖的作用机制,可能是因为它会在一段感知到的、没有奖励的时间里逐渐下降。)由于人类心智在规划和监控能力上是如此有限,我们不能被允许「关闭」机会成本的警报,然后不顾一切地对某些可能毫无价值的事情进行超常专注;从这个意义上说,拖延症代表了一种精神层面的痛苦。
从这个视角来看,我们便不难理解为何如此多的兴奋剂都作用于腺苷或多巴胺系统^[这并非指多巴胺效应本身是奖励,而是关乎对当前任务与替代任务的感知。(毕竟,兴奋剂不会让你在无所事事时,单纯地因为盯着墙看而感到愉悦。)如果所有事情都变得更有回报,那么切换任务的收益就变小了,因为替代选项的回报预期也水涨船高;或者,如果奖励敏感度只对当前活动增强,那么就会产生一种抗拒切换任务的压力,因为大脑不太可能预测替代选项会比当前任务回报更高。],为何幼儿似乎尤其难以应对精神疲劳(因为整个世界对他们来说都充满了诱人的新奇机会),以及为何许多反拖延策略(如《搞定!》(Getting Things Done)或拖延方程式)的本质,都可以归结为优化更多或更频繁的奖励(例如,将大任务分解为许多小任务,以便能逐一完成并获得更小但更频繁的奖励;或者更清晰地思考某件事是否真的值得做):所有这些,都将影响奖励感知本身,从而降低那作为基准的机会成本「痛苦」。
这个视角可能也为抑郁症[^depression],或为职业倦怠提供了新的见解,并解释了为何能让人恢复精力的爱好,最好与工作本身截然不同,以及一些更零散的观察,比如为何「爱好」在西方以外的地区不那么普遍:职业倦怠可能是一种长期的稳态反应,起因是尽管早期曾尝试过追求其他机会(那些可能永远不会带来回报的任务),但这些尝试总被压制,最终导致系统在某个困难且缺乏即时回报的任务上,过于频繁地投入了「过多」的时间,从而引发了全面崩溃^[进一步推测:职业倦怠是否类似于抑郁症的学习理论和迷幻疗法的突触可塑性范式,即个体因学习速度过慢而过度固执己见,最终导致倦怠?例如,那些(被时代进步甩在身后的)思想僵化的老研究员,是否能从迷幻疗法中受益,从而重启他们的工作?];而爱好,则应当在地点、体力活动和社交结构上与工作尽可能不同(例如,一个独处的室内程序员,应当追求一种户外的、社交性的体力活动,作为一种精神的修行),以确保大脑能感到它与日常工作截然不同;而在那些工作专业化程度较低或工时较短的地方,多样化的任务和机会的正常流动,意味着像「爱好」这种特殊的活动变得不再必要。 另一个可能的类比是沟通:电子邮件和即时消息过载,与那些「更落后」的沟通技术相比,可能反映了发送方缺乏「痛感」——从而对不堪重负的接收方造成了「损害」。
[^depression] Hollon et al 2021 认为,长时间的抑郁发作具有演化上的适应性,因为它强迫个体反复思索和审视过去,以找出错误。
有人可能会反驳说,在许多情况下,比如因配偶年老去世而悲伤,这种反复思索纯属有害——但从黑箱视角来看,当事人很可能错误地相信自己没有犯错!毕竟,一件极其糟糕的事情确实发生了。因此,不如强迫进行长时间的思索,只为抓住那一线可能,最终发现一个错误。(这又让我们回到了 RL 中,高方差的演化/蒙特卡洛学习,与更聪明、低方差但可能存在偏差的、使用模型或自举法的学习方法之间的区别,以及那个「致命三元组」。)
或许,如果我们是超级智能AI,能够以 1000 赫兹的频率,轻而易举地规划出考虑到所有潜在损伤的、完美无瑕的人形运动;或者,如果我们是被无尽的演化过程所塑造的仿真大脑,能凭纯粹的本能执行完美适应的计划;又或者,如果我们只是培养皿中一个没有真正选择可言的简单变形虫,那么,我们就不会需要一种令人痛苦的痛。同样,倘若我们能永无止境地规划和再规划,直到世界末日,我们便绝不会体验到意志薄弱(akrasia),我们只会去做必要之事(或许甚至不会体验到任何努力或深思的主观感受,只是眼看事件如其必然地、无尽地展开)。但我们并非如此。痛苦让我们直面现实。归根结底,痛苦才是我们唯一的老师。
永久和平
这些法则,从最广义上而言,即:伴随繁殖的生长;几乎已内含于繁殖之中的遗传;源于生命内外环境条件的直接或间接作用、以及用进废退所产生的变异;高到足以引发生存斗争的增长率,并由此带来自然选择,继而导致性状分异和劣等类型的灭绝。于是,从自然的战争,从饥荒与死亡之中,我们所能想象的最崇高的造物,即高等动物的产生,便直接诞生了。生命以此观之,何其壮哉!其若干力量,最初被注入寥寥几种或仅一种形态;而后,当这颗星球依照固定的引力法则循环往复之际,从如此简单的开端,无数至美至奇的生命形态,业已并仍在演化之中。
——Charles Darwin, 《物种起源》
在战争中,存在着这样一种全然的可能性:不仅是单个的规定性,更是这些规定性的总和,作为一种生命形态,可能会被彻底摧毁——无论对于绝对精神本身,还是对于一个民族而言。因此,战争在民族对具体事物的漠视中,维系了他们的伦理健康;它防止这些事物僵化,防止民族对其习以为常,正如风的运行使海洋免于因永久的宁静而陷入停滞,而一种永久的(乃至「永久的」)和平,也将在民族之间造成同样的停滞。
—— G. W. F. Hegel[^Hegel]
[^Hegel] 《论处理自然法的科学方法》,Hegel 1803;另可参见 H. G. Wells 的《时间机器》(1895),第 13 章:
> ……此刻我终于明白,那地上世界的人们(埃洛伊人)所有的美丽之下掩盖着什么。他们的日子安逸愉快,如同田野间的牛羊。也像牛羊一样,他们不知有何敌人,也无需为任何匮乏做准备。而他们的终局,也别无二致。
> 我为人类智识的梦想竟如此短暂而悲伤。它已然自戕。它曾坚定地朝着舒适与安逸迈进,以安全和永恒为信条,构建一个均衡的社会。它实现了自己的希望——却最终沦落至此。曾几何时,生命与财产必定已臻于绝对安全之境。富人高枕无忧,劳者衣食无虞。毫无疑问,在那个完美世界里,已无失业之虞,无社会问题待解。随之而来的,是一片沉沉的死寂。
> 我们忽略了一条自然法则:智识的变通,乃是为应对变化、危险与困境而生的补偿。一只与环境完美和谐的动物,便是一台完美的机器。除非习惯与本能尽皆失效,自然从不求助于智识。无变化之处,无变化之需,便无智识可言。唯有那些须应对千般需求与万种危机的动物,才拥有智识。
> 所以,在我看来,地上世界的人类已然漂向了他们那孱弱的美丽,而地下世界的人类则沦为了纯粹的机械劳工。但即便是为了机械的完美,那个完美国度也缺少了一样东西——绝对的永恒。显然,随着时间流逝,地下世界的食物供给,无论其方式为何,已然断裂。那位被暂时驱逐了数千年的必然性之母,又卷土重来,并从底层开始了她的反扑。
我们必须承认,战争是常态,斗争即是正义,万物皆依斗争与必然性而生……战争是万物之父,亦是万物之王。
——Heraclitus, B80/B53
仅仅成功是不够的;其他人必须失败。
——Iris Murdoch,《黑王子》
倘若我们移除了外部损失函数,会发生什么?
在元学习的语境下,系统要么会对单一问题实例产生过拟合,要么会学到一个可能任意次优的平庸对策;在《雷神之锤》夺旗赛中,如前所述,内部损失函数可能会收敛到「各自为战」的策略,或是那种能带来战术小胜,却注定导致战略溃败的贪婪策略;在人类种群中,其结果(在目前拒绝使用人工选择或基因工程的情况下)将是突变负荷的逐渐累积,导致严重的健康问题,并最终可能引发突变崩溃或错误灾难;而在经济体中,它则导向了……苏联。
这种约束的强度可以变化,它取决于非基准真相的优化算法有多强大、复制的保真度有多高、以及选择的准确性有多强。普莱斯方程为我们提供了群体选择在何种条件下才可能起作用的量化洞见:如果一个神经网络只能以粗糙、有损的方式复制自身,那么元学习从一开始就无法有效运作(因为优良特性必须代代相传);如果一个人类细胞的复制错误率高达百万分之一,那么人类将不复存在,因为繁殖适应度这个奖励信号太弱,根本无法清除不断累积的突变负荷(选择增益为负);如果企业破产变得更具任意性,更多地取决于天灾人祸或政府干预,而非消费者需求,那么公司将会变得愈发病态和低效(因为性状与适应度之间的协方差太小,无法以有意义的方式累积)。
正如 Shalizi 在他的书评中总结道:
在有限的领域内,规划当然是可能的——至少如果我们能为规划者提供高质量的数据——并且随着计算能力的增长,这些领域的边界还会扩大。但规划之所以只在这些领域内可行,是因为赚钱这个目标,为公司(或类似公司的实体)提供了一个既明确又狭隘的目标函数。而为整个经济进行规划,即便在最乐观的假设下,在可预见的未来也是一项棘手的任务,至于如何决定一份计划,我们更是对其间的难题束手无策。在《红色丰裕》中角色们所梦想的那种高效计划经济,我们根本不知道如何实现,即便我们愿意为此接受独裁统治。
这便是为何规划算法不能简单地无限膨胀,并最终取代所有市场:「谁来监督监督者?」尽管各种内部的组织与规划算法功能强大,远胜于演化或市场竞争,但它们优化的终究是代理的内部损失函数,而非最终目标。因此,它们必须受到一个基于基准真相的外部损失函数的约束。对这种外部损失的依赖可以也应当被减少,但只要内部损失函数所收敛的最优点,与基准真相的最优点存在差异,那么将其完全移除便是不可取的。
鉴于一家失败的公司通常能苟延残喘很长时间,公司在统一员工目标方面困难重重,及其无法复制自身「文化」的特性,市场中的群体选择充其量是微弱的,而外部损失函数无法被移除,这一切也就不足为奇了。但另一方面,这些缺陷未必是永恒的:随着公司逐渐软件化^[顺便一提,API 是双层优化的又一个实例。在 API 内部,软件工程师可以利用随机 A/B 测试等技术进行精确的爬山优化。但你无法对整个生态系统及其 API 进行随机化!对 API 集合的选择只能在公司层面(甚至更高层面)发生。一个 Stripe 和一个 PayPal 支付 API 的区别,绝非调用 2 个还是 3 个函数的差别;而对亚马逊 AWS 而言,有史以来最重要的决定,莫过于杰夫·贝索斯自上而下地颁布法令,规定此后一切都必须是一个 API——其内部实现乃至 API 细节,与相互竞争/协作的 API 所形成的生态系统效应相比,都显得微不足道。另可参见「技术圣战」。],能够被复制,并存在于拥有更快 OODA 循环(观察-导向-决策-行动)的、更具活力的市场中,或许我们可以期待一个新时代的到来:届时,公司确实能够精确复制,并由此开始持续演化,实现效率的大幅跃升,迅速超越迄今为止的一切进步。
另见
略
外部链接
略
附录
略
Thoughts Memo 汉化组译制
感谢主要译者 gemini-2.5-pro、校对 Jarrett Ye
原文:Evolution as Backstop for Reinforcement Learning · Gwern.net
作者:Gwern Branwen