

引言
这些年来,很多人问过我:在学习日语的过程中,我「具体」做了什么。这篇文章会详细讲清楚:我的学习路径、我做过的具体事情,以及我学习日语的总体理念。
每个人学习方式都不一样。这并不是因为有人可以省略关键要素(沉浸——顺带一提,这一点不可妥协),而是因为即便大家都在做所谓「同一种」方法,每个人也会有自己的一套做法。 不管好坏,每个人都有一个属于自己的「沉浸法」分支版本。
很自然地,这种个体差异意味着:严格来说,每个人其实都在用「不同的方式」学日语——这是你需要纳入考虑的事。 我的人生哲学是「一切都重要」。如果把学习方法上的差异轻描淡写地当作「无关紧要」,对「把日语学到熟练」这样宏大的目标而言,几乎可以说是智识上的不诚实。因为整个过程彼此缠绕得太深。
我相信这个过程有许多可动的部件,而每一部分都重要。也正因为一切都重要,我也相信:学习日语中的某些步骤与方法,可能就是你最终「走得出来」或「走不出来」的差别所在。
这对你来说重不重要,由你决定。 你是否在意「学得好」/「走得出来」,完全取决于你的目标。 你永远改变不了一个人的目标。我对这一点痛苦地理解到:每当我在 TheMoeWay Discord 回答问题时,「这取决于你的目标」几乎成了我的口癖。事实就是:在日语学习里,几乎不存在那种放之四海而皆准的标准答案。
但我的目标一直是:
- 把日语学好
- 帮助他人学习
我最初写 TheMoeWay 的主要动机,是因为我感觉有些重要信息被「藏起来」了,我得不到。 那大概是 2018~2019 年。那时沉浸在社群里还算不上主流。社群里的人基本只会把彼此困在无尽的初学者循环中;似乎只有住在日本、并且围绕日语建立起社交生活的人,才被允许「爬上去」。
当我第一次通过「AJATT」和 Matt vs. Japan 接触到沉浸时,那在当时对我来说几乎是革命性的。它给了我一直想要的东西:心态、务实方法,等等——这些正是我觉得日语学习社群里最匮乏的部分。 我厌倦了那些屁话。我知道必须改变。我知道我得把这些信息传播出去,确保别人不要再掉进我曾经掉进去的陷阱。
译者:基于二语习得理论的日语学习指南的作者也是类似的想法。
从某种意义上说,TheMoeWay 只是我写给过去的自己。即便我写的东西并不完全严谨客观,也无所谓;关键在于:那些信息是「过去的我最希望有人告诉我的一切」。
于是,人们在我什么都没做的情况下就开始自发宣传我的网站。我从来没有主动打过广告。我只是写下我认为能帮助人的内容,然后人们就开始口口相传。
我在青少年时期写下的东西,在完全没指望它会火的情况下,最终帮助了这么多人——这件事至今仍让我觉得不真实。再加上 TheMoeWay Discord 的成员不断鼓励我把「Shoui 方法」写出来,我觉得现在是合适的时机。 即便这篇文章最终会被认为太主观、太古怪,甚至慢慢被遗忘,只要它能帮助哪怕 1 个人实现目标,也足够了。我不仅想把日语学好,我还一直想让那条路对其他人更清晰——尤其是那些像过去的我一样挣扎的人。
如果它能帮助哪怕一个人摆脱停滞,对我而言就意义重大。
P.S.,这不是一份面向一般自学者的通用指南;通用指南请看日语学习指南[1]。这篇文章是一份强烈带有个人观点的「如何学习日语」文章。
核心原则
- 不要使用日语字幕。
- 把你做的事联系回真实世界。
- 通过走出舒适区来进步。
- 一切以设置的简单为先。
- 真正让你成为流利口语者的是听力。
日语字幕是一种拐杖:它既不会让你的听力变强,也不会让你的阅读变强。它之所以诱人,是因为你可以借此学新词,也因为无字幕观看实在太难。但你必须尽早放掉这根拐杖,去训练真正的听力能力。
把你做的事情联系回真实世界——也就是说,不要只是不带脑子地沉浸。想一想:你之后会在什么时候用到你正在学的东西,你又会怎么用。
不要只待在自己舒服的内容里。你必须去做那些你还不擅长的事情,才能变得擅长。
设置要简单。避免复杂设置(尤其是复杂的 Anki 设置与挖词设置),因为它们会给学习过程增加不必要的摩擦。在我的理念里,学习过程应该尽可能低摩擦。
如果「口语流利」在你的目标里占有一席之地,那你必须知道一个残酷事实:阅读不会让你流利,只有听力会。大量听力会为你成为流利口语者打下基础,而输出练习会真正把你带到那里。但阅读是最快学到大量词汇的方式——这些词汇可以被视为帮助理解的「可见收益」;然而仅靠它,并不能代表与输出(口语)相关的完整语言能力。
背景:我在入门阶段做过什么
传统学习
我学习日语的最初将近一年,基本都在用一些低效方法,比如:
- 使用语言学习 App
- 和「学习伙伴」/ 笔友 100% 用日语交流,即便我的日语完全不对。
- 用 Discord 和日本人文字聊天。
- 看关于日语的 YouTube 视频(英文)。
- 用各种方法试图「学汉字」,包括把《Remembering the Kanji》的 PDF 抄下来、刷 JLPT 汉字表、以及用汉字卡片(正面写汉字,背面写音读/训读、意思和各种词)。
- 刷 JLPT N5 + N4 词表(我用 Shirabe Jisho 刷的,大概 1500~2000 个词)
- 用 YouTube 播放列表和 JLPT N5+N4 学习材料学语法。
- 拼命读 NHK Easy News。
在这些事情里,最有用的其实是:
- 学词汇
- 学语法
- 尝试输出
这三件事为后续沉浸带来的收益打下了基础。对初学者而言,我不推荐其他东西。这三项(词汇、语法、输出)属于学习过程最核心的组成部分;另一块核心拼图则是「沉浸」。
我是在一个日语学习 Discord 里听到有人对我说「多读,你就会变强」之后,才开始了解沉浸的。那个人是那个社群里唯一一个日语很强、但又不是混血(haafu)、帰国子女、华人、或日语母语者的人。 我记住了这句话,然后开始研究沉浸方法。也就是那时我找到了经典 DJT 指南。但我得说,这份指南对「变强的过程到底是什么样」解释得很差,并且漏掉了两个关键要素:无字幕听力和「容忍模糊性」。
那份指南让你去做 Core2k(那时候 Kaishi 还不存在)。但因为我刷过 N5 和 N4,所以我已经认识太多词,不适合再做 Core2k,于是我直接开始阅读——但那实在太折磨了。 在不理解诸如「习得 vs 学习」与「容忍模糊性」这些关键概念的情况下,被人一句「就去读」打发,会把人推向燃尽。我没有取得多少有意义的进步,因为我会在同一页上耗上好几个小时,并且觉得如果从沉浸第 1 天起不能理解所有内容,那就不算「真正的学习」。用这种方式根本不可能累积大量日语接触量。
直到我通过 Matt vs. Japan 发现 AJATT,并接触到「容忍模糊性」这个概念后,我才终于开始有那种可以称之为「进步」的进步。 「如果你想练成无字幕看动画,那就从现在开始无字幕看」这个想法完全正确。 我采纳建议、亲自试过之后,就被说服了。因为我学到的词终于有了用武之地;也因为过了一段时间后,我终于能听懂无字幕日语:没有拐杖,没有日语字幕,没有翻译,没有自我安慰。这太关键了。
这也是为什么我在日语学习指南[1]里传递这些要点:
- 学词汇
- 学语法
- 尽快沉浸:无字幕听;容忍模糊性。
另外,当我开始沉浸后,我经常遇到那种「哦,原来那个想法在日语里是这么说的」时刻。 我可以把沉浸内容联系回真实世界的使用场景,这是因为我之前做过输出尝试。 沉浸方法常常低估输出的重要性,但我认为把输出和沉浸结合起来效果最好。
当然,我也理解他们为什么劝退输出:在我沉浸时长还不到 100 小时之前,我的输出确实停滞又难看,几乎看不到改善迹象。
沉浸:我在入门阶段怎么沉浸
最简单的概括是:「听力:阅读=9:1」。
我并不是那种纯粹的「音频洁癖」路线;我从来没疯到「只听音频、只做音频卡、完全避免阅读」的程度。 相反,我会:
- 看无字幕动画,或做其他无字幕听力(日剧、YouTube 等)
- 读一点小说或漫画来学新词
- 把阅读里学到的词做进 Anki
这基本就是我作为初学者时的学习循环。
早上第一件事做 Anki → 沉浸:看 12~13 集无字幕动画 → 用 Yomichan(现在是 Yomitan)读一点小说或轻小说,大概 30 分钟到 1 小时,添加一些新卡片 → 睡觉
你应该怎么做
如果你还没开始做,我建议你每天用 Kaishi 学核心词汇,并把你选择的语法指南里讲的语法要点过一遍。Kaishi 按默认速度每天 20 张新卡。 (我个人从来没低于 20 张/天;但对有些人来说可能太猛了,那就试试 10 张/天。)
不过我也要说明:我当年并没有做 Kaishi,也没有做 Core2k。我的第一套 Anki 牌组其实是挖词牌组——我很讨厌它——而我本质上也只是学常见词而已。我认为:为了学核心词汇,做 Kaishi 是更好的替代方案。
我个人最早是用我在资源页里链接的 Japanese Ammo 播放列表学语法的,但我觉得她的讲解并不够好;如果能重来一次,我会改用这些年更推荐的语法指南来学:Yokubi、Cure Dolly、IMABI。
我现在对初学者最推荐的是 Yokubi。它是一份书面指南,旨在教你日语语法的核心概念;剩下的内容应该用沉浸来补足。
初学者在语法上过度纠结是一种徒劳。不要在你还不够熟练之前,把太多精力砸在语法上。你只需要掌握基本想法即可。不过我也要说:我在开始沉浸时,已经会基本的活用(conjugation)了。
我强调学词汇与学语法,是因为如果你真的想完全照我当年那样做,那么你在每天沉浸时就需要一个不断扩张的词汇量。
在你用 Kaishi 学词的同一天,去做无字幕动画沉浸。需要说明的是,这里的「无字幕动画」只是你可以沉浸的一个例子。我个人用的就是无字幕动画,但任何「足够吸引人」且「没有字幕」的日语内容都可以。
有趣的是,我在初学者阶段对沉浸内容反而没那么挑剔;我不太在意动画难度,基本是看什么自己感兴趣就看什么。那段时间我看的大多是 CGDCT 生活向、热血少年漫,以及擦边后宫动画。
当你觉得自己今天的听力做够了,就读一点小说来挖一些词。(我的挖词设置细节在这里)
总结一下:同一天里做这些事:
- 做 Kaishi
- 把基础语法要点过一遍
- 无字幕动画沉浸
- 试着读一点
我会把这称为 Shoui 方法的「阶段 1」:无字幕动画沉浸、学词、以及少量阅读的持续循环。 这个阶段请至少做到听力 100 小时。
我个人其实做得比这更久一些:大概看了 1000 集无字幕动画,也就是约 300 小时。
相关链接
本指南内的相关链接:
Shoui 方法阶段 1——听力
记住:不要使用日语字幕。它们是拐杖。现实生活没有字幕,未经处理的原生内容也没有字幕;那我们为什么要一直保留这种训练轮?
听力是一种自上而下、偏直觉的活动。你不会因为不断停下来分析一切而变成好听者。
听的时候,尽量把你听到的内容联系回真实世界。沉浸时在脑中进行输出模拟。 试着去想:「如果是我,我会怎么用我现在听到的这句话?我能不能用自己的方式改写这句话?」 不要只是不带脑子地沉浸;试着想一想你听到的日语到底在「做什么」。你还能想到你在别处听过这个词/结构吗?你能想到你现在听到的用法,和你过去听到的有什么不同吗? 你能不能把自己想象成角色/说话者在说这些话?如果你要对别人表达同样的意思,你会怎么说?
想象一下:你未来会如何在自己的生活中使用你现在听到的表达。
这是一个长期重要的概念;在我看来,这就是「正确」的听法。你应该在整个日语学习旅程中都用这种心态来做听力。
我在这里讲的东西经常被忽略,但它们是你在听的时候应该去想的、非常重要的内容,请务必记住。
在这个阶段,我不认为你需要太纠结沉浸内容的多样性。一直看动画完全可以;不过我当时也会在这个阶段稍微扩展到日剧和 YouTube 视频。
你们中有些人可能会想:「真的?第 1 天就无字幕听力?这也太离谱了吧。」 我知道——无字幕听力很难,所以大多数人都会不可避免地把它一拖再拖。 「我还没准备好,我是不是应该多做点 Anki / 多读点 / 多用点日语字幕……」 这是一种永无止境的循环。 想把无字幕听力练好,唯一的方法就是:直接去做。 我让大家从一开始就做无字幕听力,主要是为了建立心态。你越久回避无字幕听力,你就越难逼自己去无字幕听;因为你在各种舒适区学习活动(Anki、阅读、日语字幕)上投入越多,就越难离开它们。 我不希望大家掉进这样的陷阱:一直读、一直用字幕,同时被「我还没准备好」这个想法压得喘不过气。 太常见了:有人极度害怕开始无字幕听力,于是满足于自己的阅读能力、满足于自己在 Anki 里认识多少词、满足于自己读日语字幕有多顺。这些人其实已经够好了。他们的问题不在于「没准备好」,而在于太害怕去试。 此外,人们第一次开始听力时还有一个非常常见的问题:他们会每一句都暂停;当他们发现自己听不懂所有内容时,就极度沮丧和泄气。但真相是:没有人在第一天就能听懂一切。我当然也不可能。 所以记住一件重要的事:不要暂停。别做,我知道你很想暂停,但不要。别暂停。把时长堆起来。
另见:被动聆听
Shoui 方法阶段 1——阅读
我在最开始并不太强调阅读,尽管阅读确实是你扩大词汇量的最重要途径。
与听力相反,阅读是一种自下而上、偏分析的活动。你可以花任意时间,查任意多的词。
我在阅读方面主要做的是:
- 把手机和电脑的 UI 语言设置成日语
- 多用日语 YouTube,这样你会在视频标题里不断自然地看到词
- 听力之后尝试读一本小说,慢慢读下去。你从听力中习得的结构会逐渐让阅读没那么难。
- 用 Yomitan 的绿色按钮把你查过的词做成卡片
阅读很难,所以我一直尽量读得很仔细。我反对「让不懂的东西直接滑过去」这种做法,但我也认为这里需要保持平衡。
所谓「精读」,是指你读得非常仔细,并尽量确保自己理解一切(顺带一提,对初学者来说这非常难;而「理解」也只能到你当前能力的天花板为止——但再小的成就也算数)。
所谓「泛读」,是指你只是为了「享受」而阅读。
总体来说,我采用的是「一半精读、一半泛读」的策略。 为了进一步理解,我确保自己能用到好的 Yomichan 词典,并会在网上搜索那些我实在卡住的问题。 有时把内容丢进机器翻译很诱人,但我发现这会制造一种错觉:你以为自己「学会了」之前难懂结构的意思;然而你并没有真正打下基础去直觉地理解它为何如此。这对我们的目标是反效果的。尽量总是靠自己把文本解出来!这也会让「用 AI」变得没什么意义,并进一步固化那种「我学会了」的错觉。
我承认:一开始我并没有一个明确的每日阅读目标。我觉得这很拖慢我的进步,因为我通常只是「读到不想读为止」。如果能重来一次,我会告诉自己设一个「字符数」目标;这个目标应该根据你当前的阅读水平而变化。
Shoui 方法阶段 1——挖词
因为我当年既没做 Kaishi,也没做 Core2k,所以你们中有些人可能会疑惑:如果你还需要学核心词汇,那要怎么做 Shoui 方法?
背景
我先完全坦白:我不做核心牌组,并不是因为我什么都懂了,而是因为自尊心作祟,我拒绝去做。 事实上,我开始沉浸时大概只认识 ~1000 个词,还不到 Core2k 的一半。我也没耐心在 Core2k 里翻来翻去,找到我开始遇到陌生卡片的位置。并且我当时跟的指南(DJT Guide)也让你尽快设置 Yomichan、设置挖词牌组、尽快开始阅读,所以我就这么做了。
我当时开始读《日常の夏休み》,因为它有振假名(顺带一提,振假名其实就是一种自我安慰式的权宜之计;但那时我觉得一切都太难了,它至少稍微没那么难)。我用 Yomichan 查词,并且不加筛选地把所有不认识的词都丢进 Anki。我的新卡和复习积压都按每天 20 张新卡的速度推进。顺带一提,哪怕只读完一本日语书都非常痛苦,但我还是在几个月后读完了。 我其实从来没有真正清掉那堆积压。后来我接触到 AJATT 和 Matt 的方法,就开始反思自己的做法。回头看,我没做那套自己建的牌组也没损失太多——反正都是常见词和误挖(mis-mines:因为你水平不够,没能正确解析句子,于是加进 Anki 的卡片其实并不是文本里真实使用的词/结构)。所以我删掉了那套牌组,重新开始。
你应该如何开始挖词
说实话,你不需要先做完核心词汇牌组再开始挖词。如果你很在意生活的秩序感,你可能会倾向于先把 Kaishi 一路做到底再开始挖词;但我不认为这是严格必要的步骤。因为你在沉浸中学到的词,反正不可避免会覆盖到高频 1~1500 的范围。 这也是为什么 Kaishi 1.5k 的卡片数比 Core2k 以及其他牌组(如 Core2.3k、Core6k)少。因为 TheMoeWay 社群里也有人在没做完 Core2k 之前就开始沉浸,并取得了不错的结果。我知道 Kaishi 对某些人来说有多折磨。最好的做法是尽快结束这个过程,然后开始建立个人牌组。
我没有亲身经验来断言,但社群里的其他人是这么说的:
你的挖词牌组会比 Kaishi / Core 更容易、更有效。
当你学到大约 1000 个词时,你就应该差不多可以跳进去了。
我的语法学习方法
作为初学者,你不应该在语法上想得太深。所谓「学语法」并不是一个整体式的单一任务;它是一个多步骤过程。
在我的方法里,初学者只需要做这些事:
- 用你选择的指南把基础学明白(抓住要点)
- 大量听与读,让语法「流过你」
- 尝试输出
当你已经能比较舒服地读轻小说之后,再做这些事:
- 系统刷 DoJG / JLPT 语法点(即便你不在意 JLPT 也无所谓;这些是学习者很难靠直觉理解的日语结构)
- 尝试用日语学日语语法。对我来说,最开始是用单语词典查基础语法点,并参考 nihongokyoshi。
- 补齐你在入门阶段没学到的其他语法点
我的 Anki 学习方法
请确保你读过我的 Anki 设置指南,否则下面这些内容可能很难看懂。
在学习与复习 Anki 卡片时,最关键的信息永远是意思,其次是读音。
(对于有多个意思的词,可以参考研究社词典里的例句。记住与你遇到该词的那句语境相关的释义即可。导入单语词典也会让你更容易判断「在那句里用的是哪个意思」。对 Anki 卡片来说,只记住句子里用到的那个相关意思就够了;你不需要把每一个意思都刷到会。)
我总是把 Anki 放在早上第一件事做,并尽可能早做完,这样我后面一天就不用再惦记它。
我一直用 PassFail(同样见我的 Anki 设置指南)。 复习时,我先看正面单词,尝试回忆意思和读音,然后按 Space 翻到背面;接着根据自己是否没能同时回忆出意思与读音来评分(如果两者有一个没回忆出来,我就按 2;如果两者都回忆出来了,就按 1)。
Reveal: Space
Pass: 1
Fail: 2
Undo: Ctrl Z
在不作弊(作弊只是在骗自己)的前提下,我会尽量用最少时间完成每一次复习,同时尽可能保持效果。
在我学习的大部分时期,我都把新卡上限维持在每天 20 张。当然我有时也做过 30、40、50,甚至直接不设上限。但要注意:如果你把新卡上限提高到 20 以上,你就必须准备好面对接下来几天复习堆积的问题。那如果更低,比如每天 10 张呢?我几乎从来没有低于 20 张;如果偶尔低于 20,通常是因为那天完全没时间学日语。但我也理解:社群里很多人觉得每天 20 张太压迫,所以对一部分人我会推荐 10 张/天。
争议点 / 小癖好
旧牌组不必留恋
我不认同「一直留着旧牌组」这种做法。在 TheMoeWay 里这非常常见:人们会一直留着自己的一套旧牌组,即便里面都是常见词也照刷不误;但这么做几乎没什么收益。即便他们讨厌那套牌组,也很难放手——他们把它当成自己日语学习进度的游戏存档,但这和现实相差甚远。
我几乎每年都会把自己的 Anki 牌组全部删掉,我对此非常满意。我甚至会把「每年刷新一次牌组」视为 Shoui 方法的一部分。
如果那些词真的那么重要,那你下一次沉浸时就会再遇到它们。而如果你确实又遇到了、并且不得不再挖一次……那就说明 Anki 没能完成它帮助你记住词的工作。
什么时候开始用单语词典
我开始用单语(日语→日语)词典的时间很早:读完 1 本日语书之后我就开始了。但我并没有完全单语化,因为我仍然保留了双语(日语→英语)词典。重点在于:只要我做得到,我就不会犹豫去读单语释义。
脱离语境的汉字学习——Remembering the Kanji(RTK)
我做过 RTK:2200 个汉字。我并没有全程用「Heisig 方法」(关键词→默写笔顺);我只对前 1000 个汉字用了这一套,剩下 1200 个汉字我用的是「recognition RTK」(汉字→关键词)。 我是在读完 1 本日语书之后做 RTK 的,因为经典 AJATT 理念让我彻底相信:我必须做。 说实话,RTK 是我日语学习中最痛苦的记忆之一,我不知道还有什么能与之相比。每天做 100 张新词卡?一天读完一本书?每天听 10 小时?都远远比不上做 RTK 的痛苦。
脱离语境学汉字,是日语学习里争议最大的部分。 社群里很多人都说这完全是浪费时间:「就去读就行了。」
尽管我非常讨厌做 RTK,但我认为它值得。我不会立刻推荐所有日语学习者都去做 RTK;但当我看到其他学习者时,我总会觉得自己被「平反」了:RTK 事实上并不是浪费时间。在 TMW Discord 里,经常有人发帖说:自己学了很久,才发现某个常见汉字一直被他看成另一个常见汉字。我在做完 RTK 之后从来没遇到过这种问题,笑死。独特的汉字会立刻显得独特,不会混。那些没有做脱离语境汉字学习、只听「就去读」建议的人,仍然会把长得稍微像的汉字搞混——这说明只靠阅读不足以真正掌握汉字。在我看来,忽略汉字构成、只靠阅读就是一种自我安慰。
但关键问题是:你在乎吗?我在乎,所以我做了 RTK。
针对「汉字区分 + 笔顺记忆」这个问题,一个「现代」解决方案是:在你已经能流利阅读日语之后,再去做 QM Kanken 牌组。从某种意义上说,这能一石二鸟;但我并不赞同把汉字区分拖到这么晚才处理。
那你该做多少 RTK 呢?社群里常见共识是做 RRTK450 的 450 张卡片,但我本人没做这个。我做的是完整 RTK:2200 张卡片。我没有做过 RRTK450,所以没有经验可谈。归根结底,这是你的选择:要么做 RRTK450;要么做完整 RTK(2200 个汉字),前 1000 用 Heisig 方法,其余用 RRTK 方法。
被动聆听
我一直很认同被动聆听这个概念。 被动聆听指的是:你在做别的事情时,把日语音频放在后台播放。 尽管我一直在安利被动聆听,但社群里有人认为它很荒唐/没用,主要理由是:
- 很烦
- 我都听不懂,那不就没用吗?不如直接做主动沉浸
但我认为这没抓住重点。我做被动聆听,是因为我相信「纯数量」本身就有用。我很看重它能填补一天里那些我原本不会做日语、或无法做「像样输入」的时间缝隙。更何况,即便你没在注意,你的耳朵其实也在听音频;你的大脑只是把它过滤成背景噪音,直到它听到某个抓住你注意力的东西。那一刻你就会开始注意到被动沉浸,而这时它最有用。
我主要用有声书,以及我批量下载的 YouTube 频道内容来做被动沉浸。
音高重音与发音
我曾经很相信一种说法:只要大量听,就能练出完美口音。但事实证明这不是真的。不过我仍然确信:听得不够的人不可能成为好说话者,也不可能有好的发音。
我很早就知道音高重音的存在,甚至在我开始沉浸之前就知道了;但直到我积累了大约 200~300 小时听力之后,我才开始认真关注它。我认为音高重音非常基础;忽视它等于在给自己挖坑,因为它几乎和日语口语不可分割。 我相信语音训练是有用的、甚至是必要的,但我直到 2023 年才开始认真做这件事——那已经是我开始沉浸 4 年之后了。
关于音高与发音相关的一切:越早越好。
有声书:自我安慰?
我这些年一直说有声书是一种自我安慰。但我怎么能这么说呢?从技术上讲,有声书是「词密度最高」的听力内容:句子最长、词汇最复杂,所以它「肯定」最适合练听力,对吧?其实并不是。它主要适合练音高重音,以及训练你用日语的工作记忆。长句和复杂词汇确实让它比大多数内容更「难」,但这种语言仍然更偏阅读党吃得惯的那一套。我认为最大的问题是:有声书太清晰、太慢,这完全不反映真实世界的口语语速与含糊度。我觉得,如果你想变得「できる」,你确实应该强到能听懂有声书;但与此同时,你也应该沉浸在其他各种听力内容里——包括脚本化与非脚本化的口语。
阶段 1.5——视觉小说拯救的自我安慰
这是我处在这两个阶段之间的一段奇怪过渡期……我很难把它们清晰分开。所以我就直接讲清楚:在我感觉自己进入「下一个学习阶段」之前,我到底在做什么。 那时我的沉浸仍然以听力为主:看动画、日剧、YouTube,并且每天听声優ラジオ。但说实话,在阅读这件事上我自我安慰得很严重。我仍然认为阅读次于听力(老实说,这至今仍是我理念的一部分),但我真的很想达成一个目标:能用日语读轻小说。可我就是觉得读日语书太难了。 你知道的,即便我已经投入那么多,读日语书仍然很难「享受」,因为太难理解到底发生了什么;那种折磨和打击会让人极度泄气。 所以我就继续自我安慰,继续以听力为主。那段时间我总共读完了大约 8 本书,但阅读能力依旧很烂。也就是那时我接触到了视觉小说,并开始疯狂安利——因为它们比书有趣得多、更能抓住人。 这也是为什么我做了视觉小说指南,并说「视觉小说让我的阅读起飞」。因为它们确实做到了:在我读完一部视觉小说之前,我一直在强行自我安慰;读完之后,我的阅读明显提升,我也更有信心继续读,于是我带着新技能和信心回到书本。 我一直说「我在自我安慰」,是因为即便我在回避阅读,我仍然非常确信:如果继续保持这种听力中心的路线,我会严重停滞。我清楚地知道:想进步就必须读得更多。
我之所以能大量读视觉小说,主要是因为:它不是一堵文字墙;你只需要鼠标点一下就会产生「我在推进」的感觉——很神奇,这点小反馈就足以让我想读更多。
如果你现在在阅读这件事上也在强行自我安慰,我建议你这么做:
- 找一部你想读的视觉小说。
- 给自己设一个目标:每天至少读
20,000 字。* - 每天都读那部视觉小说。
用视觉小说指南里的设置来做这件事。
*需要说明:这个文字数目标取决于你当前的阅读能力。对当时的我来说,这是一个合理目标;但如果你觉得这对你来说太难了,可以考虑每天 10,000 字,甚至 5,000 字。
你的挖词方法应该和其他时候完全一样:见这里。按绿色按钮就行。那种塞满上下文和图片的复杂卡片被严重高估了。
总之,我是在读完 8 本小说、2 部视觉小说,并积累了大约 500 小时无字幕听力之后,才感觉自己完成了这段日语学习章节。
阶段 2——单语词典与词汇量暴涨
到了这个阶段,我给自己设定的主要目标是:完全切换到单语词典,并强到能更深入地理解听力内容。 为此,我知道我必须在这些方面显著提升:
- 词汇量与词汇深度
- 语法
- 总沉浸量
在这个阶段,我逼自己在看完动画之后,连续读完了《俺の妹がこんなに可愛いわけがない。》的 12 卷。 我也正是在这时意识到:「先看动画改编,再读轻小说原作」这个方法到底有多强!我在阅读技巧里谈过这点。
这也是我开始强调的一条理念:(阅读时)「目标是 99%+ 的理解度,尽量理解一切」。
我具体做的是:
- 完全移除双语词典
- 看《俺妹》(当然不一定要看它,任何有轻小说原作的动画都可以)
- 仔细读完整套轻小说。确保自己理解一切。只要对「我是否真的理解」有一丝怀疑,就去查。全部挖词。除非没选择,否则只用单语词典。所有不认识的词都去词典里查,然后也把这些词全部挖进 Anki。
可以说,那时我的进步非常大。我查过的词数量,在填补词汇漏洞方面发挥了离谱的作用。
这也是我开始做「阅读周」和「听力周」的时候——这是 Shoui 方法里很重要的一部分。
当我把这么多时间投入到一个任务(阅读)时,我甚至不想去「考虑」如何塞进其他事情。只要我知道自己只需要做一件事,我就更能运转。 所以我这么做:
- A 周:所有时间都用来阅读。听力只做被动或娱乐性质的。
- B 周:专注听力。你会发现上一周阅读带来的收益大得离谱。
- 然后继续循环:再来一轮 A 周,再来一轮 B 周。
这样我就不用再想「怎么平衡」沉浸了。
当我完全单语化、挖完 12 本书,并且从单语词典里挖了无数词之后,我真的感觉自己在阅读这件事上不再是在自我安慰了。我第一次尝到了「日语很强」是什么感觉。 我的词汇量暴涨,以至于我能明显感觉到:仅仅因为我认识更多词、对日语整体更熟,我的听力也大幅提升了。
我也觉得终于该回头认真补语法了。我意识到:如果不把这些语法点脱离语境单独学,我会在沉浸中把它们当成白噪音,于是我就用 NihongoKyoshi 语法牌组和 DoJG 牌组学完了所有 JLPT 语法点。 至于基础语法,我觉得这是个好机会:把所有基础助词都在单语词典里查一遍,读它们的释义,并尽可能内化。
我也觉得这是个好时机去尝试「掌控」听力内容。我开始把自己最喜欢的动画一直放在后台,作为半被动半主动的沉浸。我这么做的目标是:最终把整段台词都记住。我在这个阶段非常强调「重复」:我发现反复观看、反复聆听、反复阅读的帮助大得惊人。这也是 Shoui 方法一个相当重要的支柱:把你听的内容记住。
总结一下:
- 完全单语化
- 看一部由轻小说改编的动画
- 只用单语词典读完整部轻小说,并把每一个词都挖出来
- 把时间分成阅读周与听力周。
- 系统刷 JLPT 语法点。
- 阅读单语词典里关于基础语法的释义。
- 把我最喜欢的动画一直在后台重复播放,直到我把整段台词背下来。
阶段 3——专精
在前面的阶段里,你会一直感觉到:阅读促进听力,听力促进阅读。但当你在两方面都已经很强时,这种互补会开始变弱。到了这一步,如果你真的想把某项技能磨得更锋利,你只能继续做那件事。 于是问题就变成:你想专注什么?我选择了阅读。
我希望自己的日语能力至少在某种程度上接近英语能力,直到我可以在互联网上完全使用日语,而不感到任何不自由。要做到这一点,我必须读得远远比当时更多。于是我做了:我从大约 20 本书读到 100 本书,中间只偶尔停下来处理生活中的其他事情。
在这段阅读期里,我并没有忽视听力;我只是确保自己每天都读半本书。 我在听力上也下了狠功夫:去模仿一个我很喜欢其说话风格的日语母语者的语气、表达习惯和小动作。他是一位声優;声優基本都会有声優ラジオ,这种内容网上能找到几百小时。这被称为「认一个语言家长[2](language parent)」。 我会一直把它当作被动沉浸放着。我也会把日本电视和 YouTube 放着当作被动沉浸。 我也会很用力地做真实输出:在 Discord、5ch 等社群里和母语者交流;影子跟读;全程用日语发消息。
在阅读方面,我仍然在做「Shoui 方法」:全部挖词,使用单语词典。但后来我开始把双语词典和单语词典一起用,因为我感觉自己已经沉浸了很多,并且用单语词典用得够久,日语已经足够直觉化;于是我可以同时吃到「单语」与「双语」的好处。即便我在 Yomitan 里装了双语词典,当我需要去读单语释义时,我也完全不会怵;这对我来说很自然。
我的阅读内容也不再以虚构作品为主。我开始沉浸在 5ch、ふたばちゃんねる、知恵袋、http://Note.com、Wikipedia、NHKニュース,以及其他日语互联网角落里(通过 Google 搜索)。
不过,这些年你需要避免 Reddit 的机器翻译污染你的搜索结果;可以用 uBlacklist 来屏蔽。
说实话,到了这个阶段,「Shoui 方法」其实也没什么别的了,无非是:
- 读 IMABI。我按顺序从 0 读到 200。
- 学音高重音。这份指南不错。
- 永远不要把挖词流程复杂化
- 找一个能让你不断回到日语的东西。到了这个阶段,问题会变:你不再是在问「我该怎么学日语?」,而是在问「我想用日语做什么?」
结语
走到这里之后,我觉得你接下来要做的无非就是:用你的日语去做你想做的事,然后:
- 多读
- 多听
- 多说
- 多写
杂项
一些我不知道怎么分类的东西都放在这里。
我如何学习音高重音
基础内容基本都在这里讲得很清楚: Usagi Chan 发音指南 | Darius 的指南 | Dogen
- 学会了「downstep position」这个概念。
- 用 kotu.io 训练音高敏感度,目标是 100%。
- 开始高度关注自己在听力中能听出哪些音高重音,并且疯狂加大听力量。
- 开始在阅读时查词,以确保自己知道这些词的正确音高(把 アクセント辞典v2 导入 Yomitan)。
- 开始给 Anki 卡片打分时,不仅看意思 + 读音是否正确,也看我是否至少答对了 1 种音高模式。
- 请母语者听我朗読,并指出我在音高重音与发音上的错误。
- 刷完了这套牌组,以确保我知道日语最常见的 10,000 个词的音高。
- 做过一些 audiobookreading*(配有声书的阅读),用来纠正我已经内化的音高重音错误。
- 做过影子跟读和口语练习,以纠正我口腔肌肉记忆里的错误音高重音。
*需要说明:配有声书阅读是一种自我安慰,它应该只用来学音高重音。它既不会让你更擅长听力,也不会让你更擅长阅读。这意味着:对 ttsu-whispersync 说不!
日语数字听力训练
我意识到自己在听日语数字(尤其是大数字)时,并没有真正内化。比如,我能听到声音,也能想象这个数字有多大,但我无法当场算出这个数字的数值。当我意识到光靠更多沉浸根本不够时,我决定单独训练这项技能。
恰好有个专门训练这个的网站: LangPractice
语法学习
我在日语语法学习上花了很多功夫。我可以自豪地说:我不是「语法仔」。下面是我按顺序学习日语语法时做过的事情:
- Japanese Ammo by Misa
- 纯沉浸。尤其是:认真读书。
- 单语词典释义
- NihongoKyoshi Anki deck
- DoJG Deck
- 初級を教える人のための日本語文法ハンドブック
- 中上級を教える人のための日本語文法ハンドブック
- どこよりも曖昧でない日本語教室
- 日本語類義表現と使い方のポイント―表現意図から考える
- IMABI
我的排序:IMABI > 初級を教える人のための日本語文法ハンドブック > 纯沉浸 > NihongoKyoshi Anki deck/DoJG Deck > どこよりも曖昧でない日本語教室 > 单语词典释义。
其他的我都认为是「対象外」。它们还不够格进入这个排序。
顺便说一句,我没看 Cure Dolly。
Anki 的边际收益递减
虽然在我还处于中级阶段时,Anki 的帮助似乎和沉浸一样大,但到了更后期,它就不再像以前那样有用了。
我并没有真正「戒掉」Anki;它从来没有让我觉得负担,因为我一直会做牌组刷新。 这也让我有机会从一张「白纸」开始挖词——当你已经会日语时,Anki 到底还有多有用?
当我在 Discord 服务器上达到了「Eternal Idol」(N1 语法熟练+能读 25,000 词频范围的单词)时,我开了一个新的 Anki 牌组,在里面我把能找到的每一个词都挖进来(经典的 shoui 方法)。 我不留 backlog,把新卡/天设成 9999,也就是不设上限。我在挖词后的第二天就把这些词全学掉。我的保持率很高,大概 95%。
我遇到了一个独特的困境:常见词我都认识了。但如果我想 100% 理解,读书时仍然需要查一些词。 仍然有新东西要学,所以我干脆把能学的都学了。这些新词非常容易学,我只要重复几遍就能记住。但我能添加的新词量几乎是无限的。多么棒的机会。
我记住了这么多东西,但 Anki 依然感觉没那么有用。
现在日语学习里最珍贵的部分,毫无疑问是沉浸(immersion)。我每天做成千上万次重复,但我仍然觉得 Anki 很难真正发挥价值。到了这个阶段,继续挖词并在 Anki 里复习,除了追求「完美」之外几乎没有别的理由。这很反直觉,因为如果你想变得非常强,你应该更多沉浸,而不是在 Anki 上花更多时间。
另外,Anki 真的会扭曲你对日语里哪些词常见的判断。它太不真实了,完全不反映现实。
我觉得到了这个阶段,Anki 适合短时间突击:当你想把信息硬塞进脑子里、希望能记住时。但你不会看到我每天为了那些 50,000+ 词频的词做成千上万的复习。
我的设置
对你的日语之旅来说,最具革命性的两样东西可能是:
- 一台 Windows PC
- 一部 Android 手机
我刚开始学习时,只有 iPhone,没有电脑;当时所有工具都很烂,直到今天也依然很烂。我讨厌在 iPhone 上学习。后来我有了自己的 PC,这帮助非常大。所以如果你现在没有 PC,我建议你现在就去弄一台。哪怕是一台二手的、150 美元翻新的商务本,对你的日语学习之旅来说,也会比你在 iPhone/iPad(甚至 Android 手机)上能做的任何事情强太多。 我不用 Mac,也永远不会写 Linux 的配置。我的所有配置都是给 Windows PC 用户准备的;Android 的配置只是额外福利。
动画
只要没有字幕,你用什么方式看动画都无所谓。我以前下的是带软字幕(soft-sub)的盗版资源,用 MPC-HC 播放;后来改用 MPC-BE。我一直会打开「Ignore embedded subs」选项。
很多人吹 mpv 的画质和可定制性,但我希望 mpv 的开发者和 mpv 的拥趸能明白:和 MPC 相比,mpv 真的非常不友好、也非常不符合人体工学。
mpv 最棒的地方是脚本能力;社区里很多用字幕的人会利用这一点从动画里挖矿。但我不从动画挖矿;从动画挖矿会给学习流程增加大量摩擦,这违背了 shoui 方法。另外,日语字幕也是一种自我安慰。
你也可以直接用 hianime.to,把字幕关掉就行;我也用这种方式看过动画。
Yomitan 设置(初学者)
在这里为你的浏览器下载 Yomitan:
Chrome Web Store
Microsoft Edge Add-ons
Firefox Add-ons
安装完成后,你还需要安装一些词典。点击 Get recommended dictionaries… 之后,列表里几乎所有词典我都推荐作为基础使用。所以把这些装上:
- JMnedict
- KANJIDIC
- BCCWJ
- JPDB
- Jiten
不过,这还不是全部。
我不推荐「Jitendex」!它本质上是 JMdict,但往卡片里塞了大量 HTML、CSS 和超链接。这会给 Anki 卡片制作增加摩擦。你怎么可能在不手工处理的情况下,有效过滤掉多余信息?做不到。用一个更简洁的 JMdict 版本,比如我合集里的那个。
除了 Yomitan 默认可安装的「Recommended Dictionaries」(不含 Jitendex)之外,你还应该再装一些额外词典;它们可以在我的词典合集里找到。
导入词典的方法是:点击 Configure installed and enabled dictionaries…,然后点「Import」。
你也可以一次性把所有东西都下载下来: ➡Shoui 方法词典包(一键下载全部)
Bilingual/[Bilingual] JMdict (English) ("Legacy")Bilingual/[Bilingual] 研究社 新和英大辞典 第5版.zipBilingual/[Bilingual] NEW斎藤和英大辞典.zipBilingual/[Bilingual] Babylon Japanese-English.zipBilingual/[Bilingual, onomatopoeia] Onomatoproject.zipKanji/[Kanji] TISMKANJI.zipMonolingual/[Monolingual] 実用日本語表現辞典 Extended (Recommended)Monolingual/[Monolingual, Encyclopedia] PixivLight.zipGrammar/[Grammar] Bunpro.zipGrammar/[Grammar] Dictionary of Japanese Grammar 日本語文法辞典.zipGrammar/[Grammar] JLPT文法解説まとめ(nihongo_kyoushi).zipGrammar/[Grammar] どんなとき使う日本語表現文型辞典.zipGrammar/[Grammar] 毎日のんびり日本語教師 (nihongosensei).zipGrammar/[Grammar] 絵でわかる日本語.zipPitch Accent/[Pitch] アクセント辞典v2 (Recommended).zipFrequency/[Freq] CC100.zipFrequency/[Freq] Jiten (Anime).zipFrequency/[Freq] Anime & J-drama.zipFrequency/[Freq] Visual Novel Freq v2.zip
词典的排序很重要;对初学者,我建议按下面的顺序来:
- Jitendex (JMdict)
- 研究社 新和英大辞典 第5版
- Bunpro
- Dictionary of Japanese Grammar
- 実用日本語表現辞典
- (everything else can be in whatever order.)
对初学者来说,这就够用了。
接下来修改一些非常重要的 Yomitan 设置:
在「Popup Behavior」里,启用 Allow scanning popup content。把 Maximum number of child popups 设为 9999。
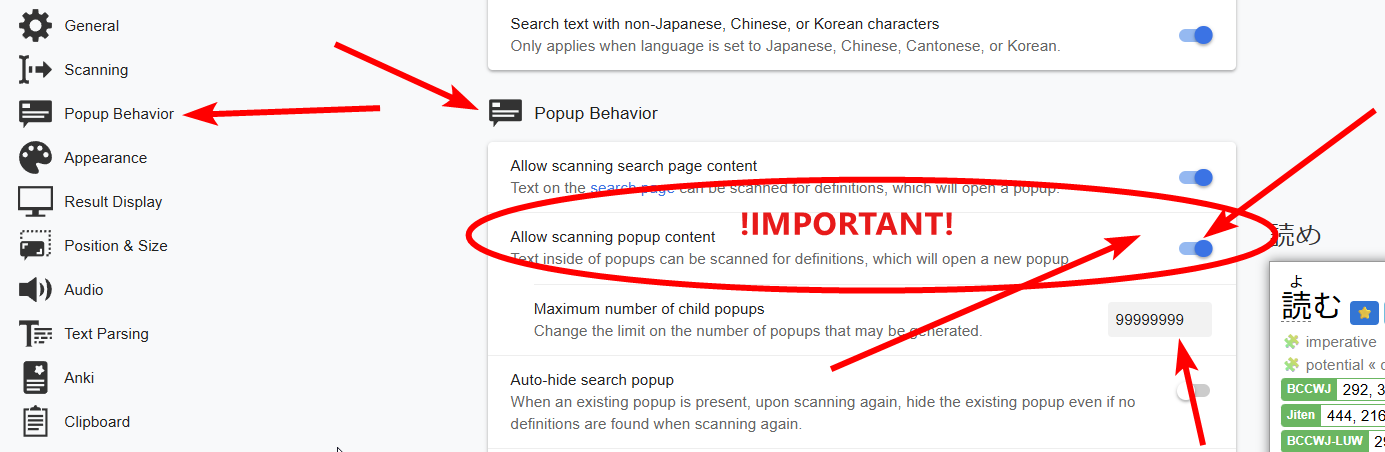
如果不打开这个功能,你就无法在词典释义里继续查词。启用之后,流程会轻松很多:你可以在释义内部无限层级地继续查词。
另一个我总会打开的选项是自动播放音频。 在「Audio」里,启用「Auto-play search result audio」。
如果你觉得太干扰,也可以不开。
另外,Yomitan 默认的弹窗尺寸小得离谱。在这里把它翻倍:
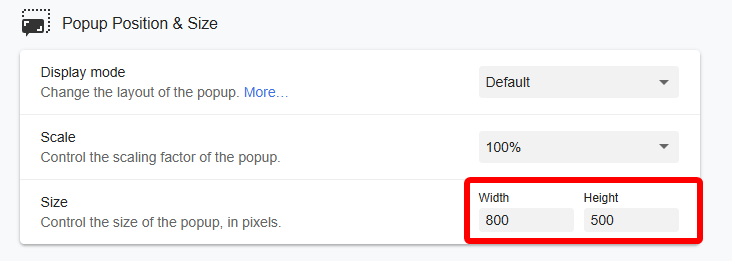
Width=800, Height=500.
最后,把这个蠢东西关掉:
Anki 设置
我在日语学习旅程的大部分时间里使用的 Anki 卡片格式,是 Animecards 的格式,不过我修改了正面,让它同时包含单词和例句。 后来我切换到了 Lapis;在我看来,它凭借「以简洁为导向」的理念,以及对大家既有配置的广泛兼容性,堪称卡片类型的「救星」。Animecards 后来也改成使用 Lapis 了。 虽然这不是我本人使用的卡片类型(如果你真的想要,可以在这里找到:"Shoui card type"),但我会演示我个人如何使用 Lapis note type 来配置 Anki。
安装
在这里下载 Anki,并安装与你的操作系统对应的版本。
截至 2025 年,安装程序现在会先装一个「Anki Launcher」,除了让普通用户更难用之外毫无意义。 安装时,你会看到这个:
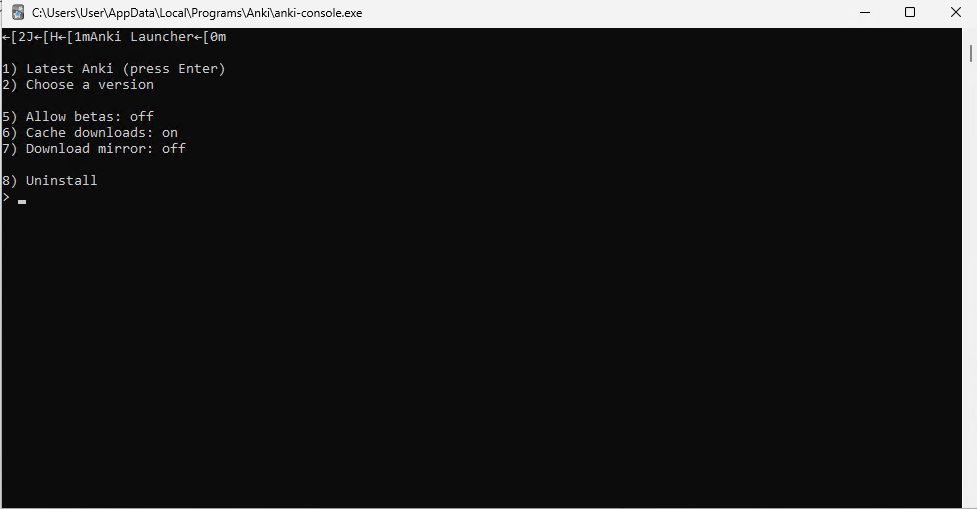
按下 Enter,真正的 Anki 程序才会开始安装。
完成后,它会显示「Anki will start shortly. You can now close this window.」。关闭这个黑色终端窗口。 然后,你会看到弹出一个新窗口,像这样:
这里是在设置 Anki 界面的显示语言。选一个你看得懂的语言就行。
接下来你会看到 Anki 的主界面。在做任何事情之前,我建议你先安装一些必备插件。操作如下:
- 点击「Tools」打开工具菜单。
- 点击「Add-ons」。
- 点击「Get Add-ons..」。
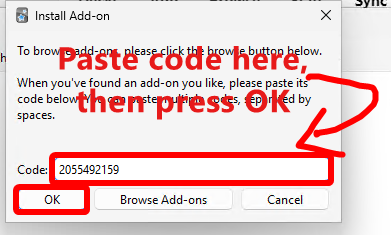
- 粘贴目标插件的 add-on code,然后点 OK。对列表里的所有插件都这么做。
下面是你必须安装的所有必备插件的 add-on code:
- AnkiConnect:
2055492159 - PassFail2:
876946123 - AutoReorder:
757527607 - True Retention:
613684242 - Local Audio Server for Yomichan:
1045800357 - Advanced Browser:
874215009
把所有插件都加完后,彻底关闭 Anki,然后重新打开来重启。
到这里,Anki 的基础配置其实就完成了。
导入牌组
下载 Kaishi 1.5k deck 的 .apkg 文件。
译者:中文版牌组下载在这里Releases · maimemo/kaishi-zh-cn
把牌组导入 Anki:双击 .apkg 文件即可。你也可以在 Anki 里用「Import File」手动选择文件导入。
然后你会看到这个界面,点击 Import 导入:
之后你可以关闭导入窗口。
牌组现在已经导入完成。接下来你需要调整牌组设置。因为这套设置同样适用于所有牌组,所以我会在全局牌组设置里解释。
全局牌组设置
导入牌组之后,点击齿轮图标,然后点「Options」。
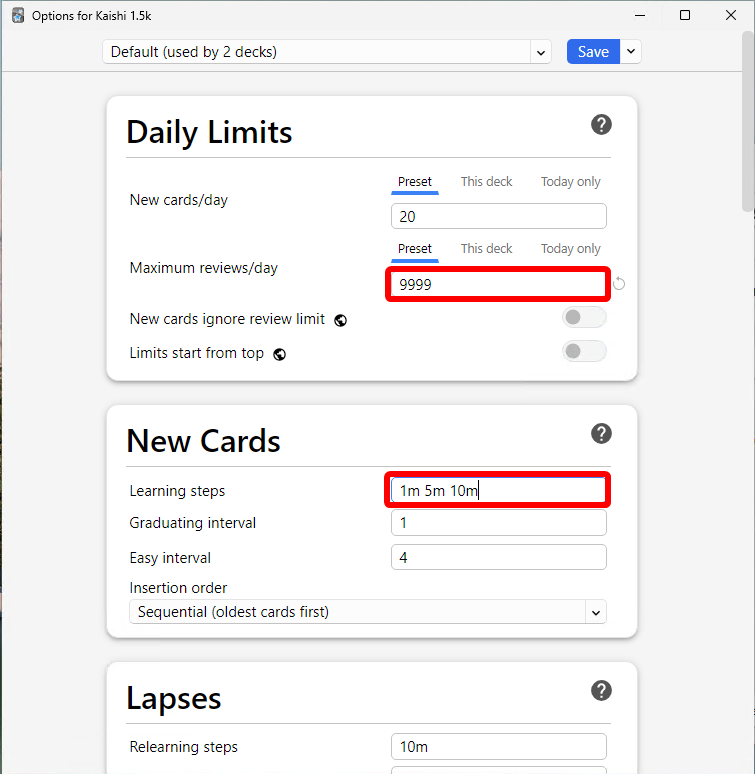
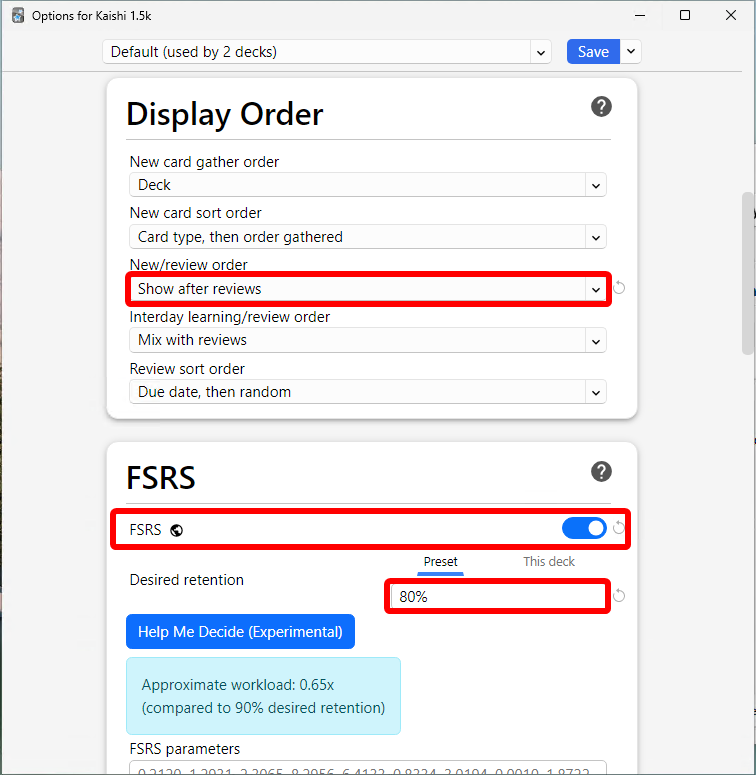
按如下方式调整设置:
- Maximum reviews/day:
9999 - Learning steps:
1m 5m 10m - New/review order:
Show after reviews - FSRS: ON
- Desired retention: any value between
80%-95%
*我个人用的目标保持率是95%;如果你真的想完全照抄我,可以自行决定用这个数值,但我觉得对大多数人来说可能太高了。对大多数人而言,80% - 90% 最合适。FSRS 在我日语学习旅程的大部分时间里还不存在,但我觉得它比 Anki 默认算法略好一点。 另外,你也可以隔一段时间就重新优化一次 FSRS 参数。
现在你已经可以用 Kaishi,以及其他任何牌组开始学习了。
使用 Lapis 的挖矿设置(shoui 方法)
下面是如何用我的配置来挖矿。
前置条件:
- Yomitan
- Anki 里已安装 AnkiConnect 插件。
- 我默认你已经导入了本指南里我推荐的词典。
然后:
- 在这里下载 Lapis。
- 把它导入 Anki。导入这个
.apkg之后,把它留下的那个牌组删掉:我们只需要 note type。 - 在 Anki 底部点击「Create Deck」,给牌组命名(比如
Mining),然后点 OK。 - 打开 Yomitan 设置:先点击浏览器工具栏里的 Yomitan 图标

,再点齿轮图标

。
- 在侧栏点击「Anki」,然后启用 Enable Anki integration。
- 再点击 Configure Anki flashcards…。
- 把「Deck」改成你刚创建的牌组名(比如
Mining)。把「Model」改成Lapis。
接下来配置卡片字段:
| Field | Value |
|---|---|
| Expression | {expression} |
| ExpressionFurigana | {furigana-plain} |
| ExpressionReading | {reading} |
| ExpressionAudio | {audio} |
| SelectionText | {popup-selection-text} |
| MainDefinition 1 | {single-glossary-jmdict-legacy-2026-01-14}{single-glossary-研究社-新和英大辞典-第5版} |
| DefinitionPicture | |
| Sentence | {cloze-prefix}<b>{cloze-body}</b>{cloze-suffix} |
| SentenceFurigana | |
| SentenceAudio | |
| Picture | |
| Glossary | {glossary} |
| Hint | |
| IsWordAndSentenceCard 2 | y |
| IsClickCard | |
| IsSentenceCard | |
| IsAudioCard | |
| PitchPosition | {pitch-accent-positions} |
| PitchCategories | {pitch-accent-categories} |
| Frequency | {frequencies} |
| FreqSort | {frequency-harmonic-rank} |
| MiscInfo 3 | {document-title} |
1 理想情况下,你应该在这里放你最常用的两本词典。我在这里定义的(JMdict + 研究社)只是基础组合,适合还没切到单语的人使用。它的作用是:当你懒得为 SelectionText 高亮选词时,给你一个「安全网」。理想操作是先高亮你想要的释义,再按绿色按钮加卡;但我理解,那确实挺费劲。所以 MainDefinition 就是你的安全网。下一层安全网/兜底是 Glossary:它包含你加卡时 Yomitan 弹窗里的全部内容。Lapis 足够智能:如果某个字段为空,它会自动回退到相关字段(例如:如果 SelectionText 为空,就回退到 MainDefinition;如果 MainDefinition 为空,就回退到 Glossary)。
另外提醒一下:JMdict 的名称里包含词典构建日期。如果你是从我的网盘下载的,它应该是 {single-glossary-jmdict-legacy-2026-01-14};如果你是直接从源仓库获取的,日期会不同,请相应调整。
2 在我的方法里,正面同时放例句和单词。但我几乎不会去读那句例句,它主要只是提供视觉语境。看你是什么类型的人:如果你容易把例句当拐杖,那就把 y 去掉。你可能会觉得它很有用,也可能会发现它是在坑自己。就我个人而言,我喜欢保留它,因为它更贴近真实使用场景,同时又不像句子卡那样既累又容易。
3 我把这里设成 {document-title},因为我在 ッツ 里读书时主要是从小说挖词;这样就能把书名作为「内嵌信息」放进卡片里,之后你随时可以查看。
现在,要挖一张卡,你只需要把鼠标悬停在某个词上,按住 Shift 呼出 Yomitan,然后按绿色按钮即可。用这个测试一下:テスト。按绿色按钮加卡;按书本图标会在 Anki 浏览器里打开这张卡。
理想情况下,你应该在按绿色按钮之前,就先高亮你想要放在背面的释义。这样你的卡片会非常干净。
用这个词试一下:この世
用鼠标高亮「研究社 新和英大辞典 第5版」释义的第一行,然后按绿色按钮。点书本图标,再在 Anki 里点「Preview」,就能看到卡片长什么样。把它和你上一张卡对比一下:高亮过你想要的释义的那张,会更干净。如果你在复习时想查看完整信息,Lapis 允许你点击释义框的左右边缘来展开查看。
我的挖矿理念是什么都挖。我不会纠结自己挖了什么,同时也尽量让挖矿流程投入最少的精力。这意味着:我的大多数卡片,都是直接按绿色按钮生成,或者高亮后再按绿色按钮生成。
另外,如果你挖的词是名词,或者是非常具象的形容词,那么你应该去 Google Images 搜一下这个词,复制一张图片,放到卡片的「Picture」字段里。这是你为卡片需要做的最多的一步手工操作。我真心觉得:名词卡的背面放一张图,效果有天壤之别,非常值得花这点力气。
如果你的 Google 总是默认给你中文结果,那是因为你的 Google 还没设置成日语。你可以用下面任意一种方式解决这个中文结果问题:
- 把 Google 语言设置为日语
- 对所有纯汉字的搜索都在末尾加上「とは」
- 使用我写的 Google JP Only tampermonkey 脚本。链接
词频排序(简单!)
这个功能会按日语里的常见程度,对你挖出来的新卡进行排序,决定它们呈现给你的先后顺序。
词频排序的好处是:你会在牌组里先学最重要的词。
前提是你的卡片里已经有词频信息,这个就非常简单。(如果你在 FreqSort 里用了 {frequency-harmonic-rank},那说明你的卡片已经有词频信息了。)
前置条件:
- Anki 的 AutoReorder 插件,代码:
757527607 - 我默认你在用 Lapis,并且你的卡片里已经有词频信息。
安装 AutoReorder 插件后,重启 Anki。然后:
- Go to
Tools→Add-onsthen double clickAutoReorder - 在这个文本编辑器窗口里,仔细把
search_to_sort:后面引号里包着的牌组名,改成你的牌组名。同时也要仔细把sort_field:后面的字段名改成"FreqSort"(同样需要带引号)。 - 按 OK,然后重启 Anki。之后每次你启动 Anki,卡片都会按常见程度自动重排位置。
如果你搞不清楚,下面给一个例子:假设你的牌组名是「Mining」,并且你使用 Lapis,那么它应该长这样:
{
"search_to_sort": "deck:Mining is:new",
"shift_existing": true,
"sort_field": "FreqSort",
"sort_reverse": false
}注意:如果你的牌组名包含空格,你需要对空格进行「转义」。例如,如果你的牌组名是「Mining Deck」,你需要这样写:
{
"search_to_sort": "\"deck:Mining Deck\" is:new",
"shift_existing": true,
"sort_field": "FreqSort",
"sort_reverse": false
}就这样。你完成了!之后你照常挖卡就行;每次启动 Anki,它们都会自动重排。
词频回填
如果你已经挖了很多没有词频信息的卡,就做这个。 照这个做。
本地音频(简单!)
本地音频为什么好:因为它提供的音频比 Yomitan 默认可用的更多;因为本地音频使用的来源有准确的音高重音;因为它完全离线可用。
配置起来比较麻烦,但我觉得非常重要。 我会尽量把步骤写得简单易懂。
首先,你需要下载一个很大的文件。官方提供的是 .torrent,但我觉得对用户太不友好,所以我把它做成了直链下载。
你还需要 Local Audio Server 这个 Anki 插件,代码是:1045800357。 安装这个 Anki 插件(Tools → Add-ons → Get Add-ons... → 粘贴代码 → OK),然后重启 Anki。
如果你还没有解压工具,你还需要 7-Zip 或 NanaZip(Windows 11 推荐)。
另外,我建议把这个本地音频 .tar.xz 文件放在 SSD 上,而不是机械硬盘上。
下面的步骤
对 .tar.xz 文件右键 > 7-Zip/NanaZip > Extract to %folder%,得到 local-yomichan-audio-collection-2023-06-11-opus.tar。
然后对这个新的 .tar 文件重复同样操作:对 .tar 文件右键 > 7-Zip/NanaZip > Extract to %folder%,把所有本地音频解压出来。这个过程会花很久。
完成后,你应该会看到一个 user_files 文件夹。你需要把它移动到正确位置,操作如下👇
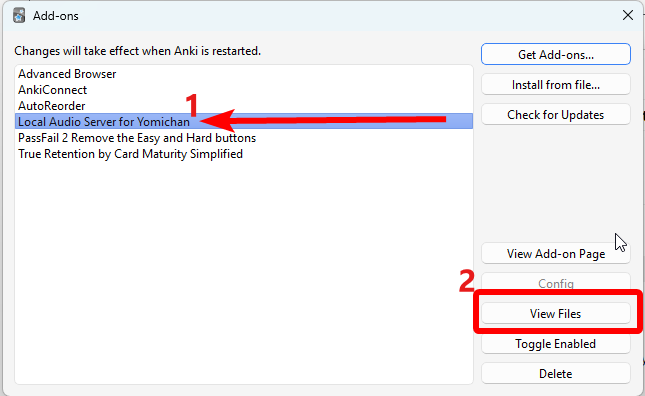
在 Anki 里,进入 Tools → Add-ons,点击 Local Audio Server for Yomichan,然后点 View files。
这个路径是 %APPDATA%\\Anki2\\addons21\\1045800357。你也可以把它粘贴到 Win+R 里打开。
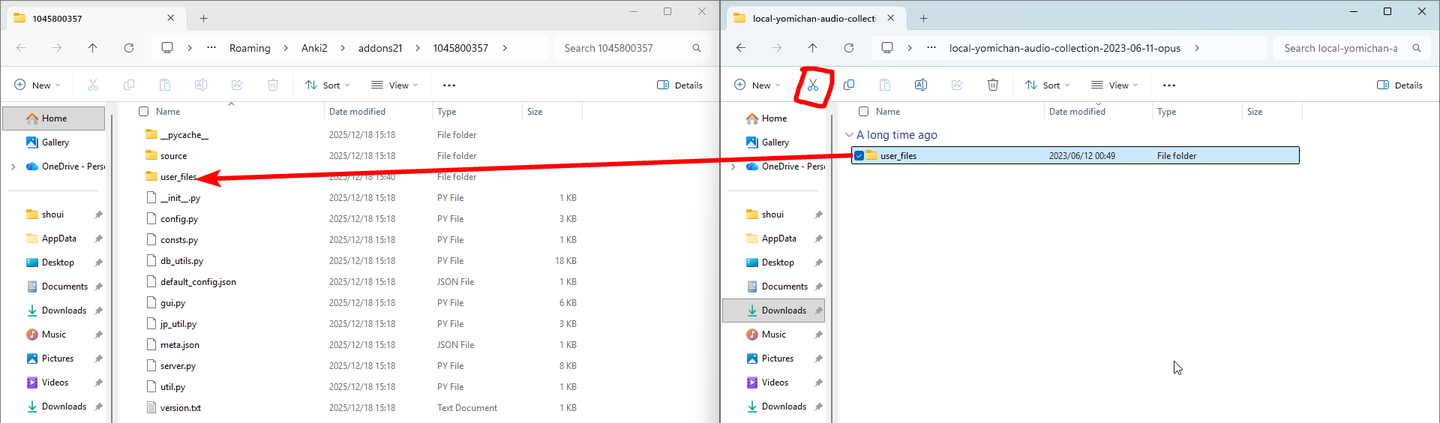
找到你解压出来的 .tar 文件夹,里面应该有一个 user_files 文件夹。 把整个 user_files 文件夹移动到本地音频插件文件夹里,最终应长这样:
快完成了! 现在你只需要重新生成本地音频数据库! Tools → Local Audio Server → Regenerate database
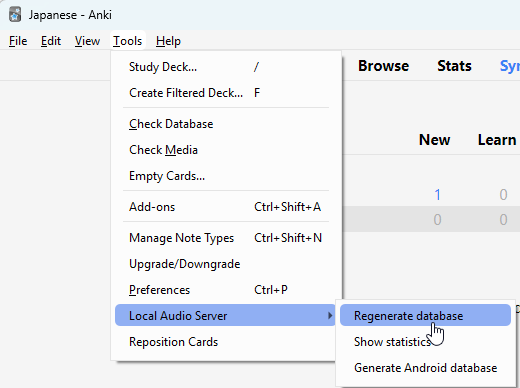
最后一步!
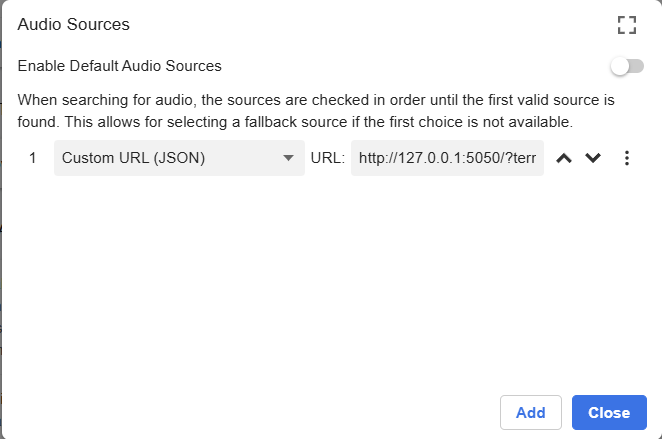
- 进入 Yomitan 设置。
- 进入「Audio」。
- 点击
Configure audio playback sources…。 - 把你在这里看到的所有内容都删掉。(三个点 > Remove)
- 点击「Add」,在下拉框里选择「Custom URL (JSON)」。
- 在 URL 字段里粘贴:
http://127.0.0.1:5050/?term={term}&reading={reading}
必须是「JSON」!不是不带 JSON 的那个「Custom URL」!
你完成了!🎉
Yomitan 设置(单语)
在「Popup Behavior」里,启用 Allow scanning popup content。把 Maximum number of child popups 设为 9999。
我的单语配置这些年一直在演变。我可以告诉你我过去做过什么,以及我现在推荐什么。
背景
最开始时,我只是把旧版的新明解国語辞典和明鏡国語辞典装在 JMdict 与研究社 新和英大辞典 第5版旁边,偶尔翻一翻。我一听说 Yomichan 有这些词典就立刻导入了,但那时我对单语并不认真。
当我开始认真做单语时,我写了(早已过时的)《单语指南》。那时我采用的词典顺序是:
- 明鏡国語辞典
- ハイブリッド新辞林
- 実用日本語表現辞典
- 新明解国語辞典 第五版
- JMdict (English)
- 研究社 新和英大辞典 第5版
- 大辞泉
现在已经有好得多的替代方案了。我不推荐你照那个顺序来。
在我第一次真正认真的单语阶段(我做到 100% 单语)里,我导入了所有词典,主要使用的是大辞林和旺文社国語辞典 第十一版。
✅ 我现在的词典栈
我现在在 Yomitan 里按如下顺序排列词典:
- 広辞苑 第七版
- 新明解国語辞典 第八版
- 三省堂国語辞典 第八版
- 大辞林 第四版
- デジタル大辞泉
- JMdict Surface Forms
- 実用日本語表現辞典v2 (extended)
- PixivLight
- 精選版 日本国語大辞典
- 日本語俗語辞書
- 明鏡国語辞典 第二版
任何额外词典(例如词频、音高重音、语法、TISMKANJI 和双语词典)都不属于「词典栈」,你想放哪都行。
我给大多数想入门单语的人推荐的词典栈是:
- 三省堂国語辞典 第八版
- 大辞林 第四版
- JMdict
- 新明解国語辞典 第八版
- 広辞苑 第七版
- デジタル大辞泉
- JMdict Surface Forms
- 実用日本語表現辞典v2 (extended)
- PixivLight
- 精選版 日本国語大辞典
- 日本語俗語辞書
- 明鏡国語辞典 第二版
- (把研究社、Babylon、斎藤之类的其他双语词典放到底部)
如果你不喜欢信息量太大,只想最精简的配置:
- 大辞林 第四版
- 実用日本語表現辞典v2 (extended)
- PixivLight
这样应该也够用,但你会受制于单本词典的解释角度与措辞。我推荐「広辞苑→新明解」这个组合,因为它能带来更丰富的语感细节;不过我也理解,对一些人来说,这可能会变成一面「文字墙」。
❤️ TheMoeWay 新手常用词典
在 TheMoeWay 里讨论「我该用什么词典」时,这些词典经常会被提到。
- 小学館例解学習国語 第十二版
- 三省堂国語辞典 第八版
- 明鏡国語辞典 第三版(带 furigana)
- 旺文社国語辞典 第十一版(避免使用第 12 版转换版;其中的惯用表达没有读音信息。)
这里面最好的两个是三省堂国語辞典 第八版(这本有时候真的很顶)和旺文社国語辞典 第十一版。 我觉得明鏡国語辞典本身也挺好,简洁明了、很容易看懂。但我认为 furigana 是一种自我安慰,所以你应该改用我网盘里的第二版。
小学館例解学習国語 第十二版 深度不够。别用它了,直接用更大、更「正经」的词典。
总体来说,除了三省堂国語辞典 第八版 之外,我不觉得这些词典能给词典栈带来太多额外价值。
100% 覆盖率?
如果你追求真正意义上的 100% 覆盖率,你需要保留全部 4 本双语词典,同时也要拥有所有单语词典。如果你想做到彻底单语,你就得把每一本词典都导入,确保没有词会漏网。 但对 99% 的情况来说,把所有词典都导入实在太夸张、不现实,也没什么意义。
如果你觉得自己的词典配置覆盖不够,可以考虑把这些也加入「词典栈」:
- 三省堂 全訳読解古語辞典
- 角川新字源
- 漢字源
- きっずジャポニカ 新版
- 所有四字熟語和慣用句相关词典。
从哪里获取这些词典
其中大部分词典都可以在我的词典合集里找到。
其他一些(比如角川新字源、きっずジャポニカ 以及其他四字熟語词典)既可以在 Marv 的合集里找到,也可以在 Caoimhe 的合集里找到。特别是角川新字源,因为它需要额外字体,所以必须从 Caoimhe 的合集下载。
词典解释随笔
我在 TMW 里写过的一段关于词典的小随笔。
新明解 →三国→新選国→現国→旺国→明鏡→岩国→大辞泉・大辞林→日国→広辞苑
(语用/主观 → 规范/客观)
这些是「语用型」词典:它们会超出客观意义本身去解释细微语感。新明解比三国解释得更「放飞」;三国的写法更容易懂,即便它会把语感磨平。
- 新明解国語辞典
- 三省堂国語辞典
这本偏向「正确用法」:
- 明鏡国語辞典
这些是偏学校取向的词典:它们不冒犯、尽量安全;目标是清晰、稳妥、够用。
- 新選国語辞典
- 現代例解国語辞典
- 旺文社国語辞典
这些是面向现代日语的通用型词典:中立、全面。大辞泉和大辞林读起来很像并非偶然;不过大辞林在词条数量上更胜一筹:
- 大辞泉
- 大辞林
这本偏历史纵深:它会解释一个词是如何演变成现在这个意思的。它的全面程度不输大辞林和大辞泉,但不会明确强调「现代日语」取向。
- 精選版 日本国語大辞典
这本想做「权威」:只关注语义本身。它会先列原始义,再列后起义;目标是尽可能中立,和新明解刚好相反。
- 広辞苑单语挖矿
这是一个很重要的细节。
理想情况下,你应该每次都高亮你想要的释义。这样加进 SelectionText 的释义会非常干净。
但我理解,对有些人来说这工作量太大了。那就把最好的词典尽量放在最上面,然后照常加卡就行。
我认为,用于 Anki 卡片释义的最佳词典组合是:
- 在
SelectionText字段中,从「広辞苑 第七版」或「三省堂国語辞典 第八版」复制粘贴最简洁的释义。 - 在其下方,在
SelectionText字段中再复制粘贴「研究社 新和英大辞典 第5版」(或 JMdict)里的释义行。
除非你非常认真想走全单语(我曾经很长一段时间就是这样),否则我认为上面的组合最好。你可以考虑把这两个词典放进 MainDefinition,这样默认就会显示出来。
| Field | Value |
|---|---|
| MainDefinition | {single-glossary-広辞苑-第七版}{single-glossary-研究社-新和英大辞典-第5版} |
如果你打算彻底走全单语,我建议在 MainDefinition 里使用下面任意一组组合:
- 広辞苑 + 新明解 组合
- 三省堂 + 大辞林 组合
例如
| Field | Value |
|---|---|
| MainDefinition | {single-glossary-広辞苑-第七版}{single-glossary-新明解国語辞典-第八版} |
或者
| Field | Value |
|---|---|
| MainDefinition | {single-glossary-三省堂国語辞典-第八版}{single-glossary-大辞林-第四版} |
另外,把词典也挖掉。这是 shoui 方法里极其关键的一环:如果你看到一个不认识的词,就用 Yomitan 查它,然后把它挖进来;接着,把释义里你不认识的每一个词也都挖出来。最好尽可能用单语方式学习这些词,但如果太难,就退回用双语词典。
对名词或很具象的形容词,你仍然应该给卡片加图片。另外我也认为:对名词而言,实操上直接用双语释义往往更好。如果你坚持在这里保留单语释义,那就完全是为了让自己在日语上更「dekiru」;这很硬核,而我个人就是这么做的。
如何复习单语 Anki 卡片
这是一个很难训练的技能。 你刚开始做的时候会非常难。我认为它的难度与「你现在的日语水平有多强」直接相关。
我复习单语卡片的方法如下:
- 除非释义很短,否则我几乎不会逐字记住释义。
- 我通常按自己对释义「日语释义的改写/转述」理解得有多好来评分。
- 我也会按「大意」来评分(比转述再低一档)。
- 如果释义很短,我就按自己是否记得它用到的所有词来评分。
- 如果某张卡太难,我就把双语释义放进 SelectionText,改用双语释义复习。
小说阅读设置
如果把我的小说阅读设置简化到极致,其实就是:
- 打开ッツ
- 导入一个 .epub
- 开始阅读,开始挖矿。
对大多数人来说,这样就够了。你喜欢的话就坚持用这套。
但我一直都会自定义设置,因为我的眼睛不太好。
ッツ 自定义
效果(竖排)

效果(横排)

这是配置里非常「shoui 方法」的一部分。我甚至不确定大家是否会想抄我这一套,但我真心觉得我的配置很棒。
我非常吹 MS 明朝。因为我发现:只要加粗并把字号调大,它在我的 1080p 显示器上看起来就像真正的墨迹一样,清晰得离谱。这只在 Windows 上成立。不要尝试在 Android、Linux 或 macOS 上这么做。
另外,如果你用的是 HiDPI 显示器(分辨率高于 1080p 的显示器),那这么做可能完全没有意义。我之所以这么做,只是因为我在 1080p 显示器上看文本时完全不会觉得糊。就像我说的,它对我来说像墨迹一样清晰。
如果你还没装 Windows 的日语补充字体,请先装上;MS 明朝就在其中。只要你安装了日语语言包,通常就会附带。
打开 ッツ。如果你是台式机并且 Windows 缩放为 100%,就把浏览器缩放调到 150%。如果你是笔记本并且 Windows 缩放为 125%,就把浏览器缩放调到 125%。
然后在 ッツ 里根据你想读「縦書き(竖排)」还是「横書き(横排)」来调整设置。
我发现縦書き会导致我眼睛疲劳后,就彻底不读縦書き了。任何会让我读得更少的摩擦都很糟,所以我直接切到横書き并且再也没回头。不过这很个人化:我个人觉得縦書き很酷,但我更喜欢用横書き阅读。
竖排
Writing Mode: Vertical
Theme: light-theme
Font family (Group 1):MS Mincho
Font family (Group 2):MS Gothic
Font size: 21
View Mode:Paginated
Line Height:1.9
Reader Left/Right Margin: 250
Blur Image: Off
Manual Bookmark: On
横排
Writing Mode: Horizontal
Theme: light-theme
Font family (Group 1):MS Mincho
Font family (Group 2):MS Gothic
Font size: 21
View Mode:Continuous
Line Height:1.9
Reader Max Width: 758
Blur Image: Off
Manual Bookmark: On
你还没做完!接下来你需要应用 CSS。
别忘了你的浏览器缩放:150%(笔记本用 125%)!
先给浏览器装 Stylus:
然后在 ッツ 页面上,点击浏览器扩展栏里的 Stylus,并点击「Write a style for...」下方的 ッツ 链接。默认情况下,URL regex 会是错的;我们需要先修正 URL regex:
在顶部下拉框里选择「URLs starting with」,然后在输入框里准确粘贴 https://reader.ttsu.app/b。
现在你可以粘贴下面的 CSS 代码,并按 Ctrl S 保存。
.book-content div, .calibre2 p {
font-family: MS Mincho;
font-weight: 900;
}
.book-content div, .book-content p {
font-family: MS Mincho;
font-weight: 900;
}
.book-content .calibre2 {
font-family: MS Mincho;
font-weight: 900;
}
.book-content .calibre3 {
font-family: MS Mincho;
font-weight: 900;
}
.book-content .calibre4 {
font-family: MS Mincho;
font-weight: 900;
}
.book-content .calibre {
font-family: MS Mincho;
font-weight: 900;
}
.book-content rt {
font-family: Meiryo;
}
.book-content rt.calibre {
font-family: Meiryo !important;
}
.book-content rt.calibre2 {
font-family: Meiryo !important;
}
.book-content rt.calibre3 {
font-family: Meiryo !important;
}
style attribute {
font-family: MS Mincho;
font-weight: 900 !important;
}
body {
font-weight: 900;
}
main {
font-weight: 900;
}
.koboSpan,
[id*="kobo"],
.p-text span {
font-family: MS Mincho;
font-weight: 900;
}
#ttu-book-body-wrapper span {
font-family: MS Mincho;
font-weight: 900;
}你应该就完成了。你的 ッツ 现在应该看起来和我的 ッツ 一模一样。如果它看起来不是这样,说明你哪里做错了;请回去仔细读一遍说明。
移动端怎么办?
在 Android 上,我基本使用 ッツ 的默认设置,只把字体切换为 KZ UDMincho(ッツ 里预装)。 我在 Android 上的其他配置就是移动端阅读设置。
视觉小说
在读视觉小说这件事上,我有点「老顽固」。
- 我不用 JL。
- 我不用 Agent。
- 我不用 GSM。
- 我不用 Lunatranslator。
- 我不用 websockets。
我的配置就是最原始的 Textractor 方法:保留「Copy to Clipboard」插件,然后在浏览器里用「Clipboard Inserter」扩展配合兼容的「Texthooker page」。 我用 Yomitan 查词。
Google Chrome 现在已经不能用 Clipboard Inserter 了,但我本来就不用 Chrome,所以完全没影响到我。
我用的是我自己的 Texthooker 页面: Texthooker shoui
它的独特点在于:你可以给自己设一个字符数目标,并把它拆成多个 session。 例如,目标:100,000 文字,分成 10 个 session——也就是每个 session 读 10,000 文字。
2022 年的「原版」shoui 方法原文
2022 年,我在 Discord 服务器里第一次把「shoui 方法」写成了一个连贯的想法。它很好地概括了我在 2022 年的学习理念。
Shoui 方法
流程:
读完一本轻小说,把整本都挖完,然后把一整季动画刷完(或者听任何可理解的内容大约 6 小时)
# 规则 A:阅读时,在你觉得自己已经把这一段理解透彻之前,不要进入下一段(分析式阅读)。关键在于你的努力(EFFORT)。(把东西当白噪音很 cringe)
# 规则 A.a:作为初学者或中级者,你永远不可能真正 100% 理解某个内容。等过一段时间再重读你很喜欢的书,你就会更能体会这一点。
# 规则 A.b:同样地,无论你多努力想理解,有些东西在你当前阶段就是理解不了。过一段时间再回到同样的内容里沉浸,用它来验证这一点。
# 规则 B:并非所有听力素材都一样。最好的素材是对话/SoL。即便有更文学的词汇,有声书也不更好;有声书是一种自我安慰。
# 规则 C:需要学语法。推荐用单语方式学 Cure Dolly/DoJG 以及 Nihongokyoshi-net 的 JLPT 语法。如果你不学语法,你很可能会把野外遇到的语法点「白噪化」,因为你甚至不知道它是语法点。沉浸只有在可理解输入(comprehensible input)下才有效。让它变得可理解。学语法。什么都查。
# 规则 D:轻小说优先于视觉小说,因为轻小说很容易随手拿起来读,也很容易以后再读。
# 规则 D.a:过了初学者阶段,日语字幕就是自我安慰。看动画之类的不要用字幕。更多信息见规则 G。
# 规则 E:阅读永远不会让你变得流利。自然输出不会来自阅读;它只会来自听力。
# 规则 E.a:音高重音可能需要、也可能不需要专门学习音高重音模式。因人而异(ymmv)。
# 规则 E.b:听力高于一切。听力才是真正的语言,阅读不是。
# 规则 E.c:听的时候做「脑内影子跟读」(mental shadowing)或「脑内角色扮演」(mental larping)。一边听一边假装自己就是在说话的人。这能很大程度帮助你的输出突然开窍,以及你的日语内心独白。
# 规则 F:什么都查。确保你把所有推荐词典都配置进 Yomichan。但查东西会出现一个问题:理想情况下你只想查自己还不懂的东西;可你真的确定你没查的那些就都懂吗?你会不会其实是在把某个语法点或固定表达「白噪化」——比如它以不同顺序出现?这与规则 A.a 有关。
# 规则 G:Anki 必须极简,不要加任何花里胡哨的东西。你的卡片应尽可能朴素。不要总想着「Anki 卡能做什么/不能做什么」。例如,不要浪费时间纠结到底要不要加这张卡:shoui 方法的 Anki 配置能在 0.1 秒内制卡,你只要把你查过的东西全加进去就行。也别纠结要给卡片打什么分。安装 PassFail,这样你就能用二元评分系统,让生活更简单。
# 规则 G.a:最好从书里挖。从动画挖会毁了我个人的观影乐趣。反正你也要用 Yomichan 查词,从书里挖更合理,而且一键生成的 Anki 卡质量会很高、几乎不需要手工处理。我以前也有「动画卡」,但我不觉得它们比我从小说一键生成的卡更有用。
# 规则 H:单语词典。你必须尽快切换到单语词典。更多信息见《单语指南》,不需要我解释。
# 规则 H.a:当你水平还不错之后,你可能会开始钻词典兔子洞。这样做的目的不是为了学你正在读的书里查到的那个词,而是为了学习词典用来「补你漏洞」的常用词,从而填上你日语里的空缺。
# 规则 I:不要把「难」的阅读内容神圣化。它是日语学习社区最蠢的毒瘤之一。传统上,读《装甲恶鬼村正》(Muramasa)类的东西能在社区里拿到所谓的大屌点数,但这不合理,也不会让你日语变强。让你日语变强的,是把阅读与听力涉及的每一项技能都练好。「难」的阅读内容往往语法很简单,但会用大量冷门词与汉字。读你想读的就行。任何内容里都有东西可以学,所以别因为难度就去读某个东西。这不是比谁的鸡巴更大的比赛。我现在仍然同意其中绝大部分内容,除了关于「hard」内容的那一段。当时我是在「普通学习者过度痴迷难度」的语境下说的。事实是:任何内容里都有东西可以学;日语厉害意味着每一项技能都厉害,而不只是能读冷门词。当你已经在日语上很「dekiru」,读小说完全没问题时,推动自己去读最难的东西,反而能让你在最短时间里进步最大。
Thoughts Memo 汉化组译制
感谢主要译者 GPT-5.2,校对 Jarrett Ye
原文:The Shoui Method
目录:日语学习:萌萌二次元之路
参考
1. 日语学习指南 ./2002818500717207719.html2. 3A3:认领语言家长 ./667668557.html