

你会遇到无数值得了解的想法,然后忘记其中的绝大部分。间隔重复记忆系统让记忆成为一种选择[1]——但这只有当你编写出能够有效强化这些想法的练习提示时才成立。这既困难又耗时,因此大多数用户只会记录他们感兴趣的一小部分内容。我们能否让记忆变得像使用荧光笔一样毫不费力?我们探索了 LLM 能否将随意的阅读划线转化为实用的记忆提示。
这里有一个例子。在一篇关于星球地球化改造的文章中,我们中的一人划线了这段关于泰坦星的话:
……重力如此之低,以至于人类只要穿上带翼的宇航服,只需拍打手臂就能飞行。
——“Greening the Solar System”, Asterisk
这正是我们想要从这类文章中带走的惊人细节。然而,如果不加以强化,我们预料自己很快就会忘记它。
当输入完整的源文本和我们的划线时,前沿模型生成的抽认卡如下:
问:理论上人类可以在哪个天体上通过拍打手臂来飞行?
问题直接泄露了我想要强化的细节
问:为什么人类只需穿着带翼的宇航服就能在泰坦星上飞行?
我并不想强化引力机制
问:在人类飞行的潜力方面,是什么让泰坦星独一无二?
几个月后会变得模棱两可,而且在事实上是错误的(它并不独一无二)
这些大方向是正确的!它们都是关于泰坦星、关于飞行、关于被划线的文本的。但它们漏掉了这段话中最有趣的部分。下面是一个行之有效的提示:
问:在泰坦星上,重力如此之低,以至于人类只需通过……就能飞行。
答:……拍打手臂(穿着带翼的宇航服)
我们希望再次遇见曾经打动我们的新奇事物,而不是背诵被剥离了新奇感的干瘪事实。「在人类飞行的潜力方面,是什么让泰坦星独一无二?」这个问题虽然指向了正确的细节,但太过模糊。好的提示需要一种「品味」:一种经过高度凝练的判断力,建立在过去数千次复习的基础上,能够判断一个线索在几个月后是否仍然有效。
我们试图通过指令、评分标准、少样本提示示例(few-shot examples)以及在 93 个来源的约 1,500 个带标签提示上进行训练,将这种品味转移给 LLM 。我们发现,模型能够识别出划线的意图,但无法判断一个提示能否经受住长达数月的复习考验。
1. 一个由两部分组成的问题
记忆提示不是抽认卡
记忆系统——也称为间隔重复系统,或 SRS ——的工作原理是在你即将遗忘某段记忆的时刻,促使你重新提取它。它们由两部分组成:一个处理时间安排的调度程序,以及提示提取的记忆提示(通俗地称为抽认卡)。
乍一看,这些提示与普通的抽认卡很相似,但它们在更严格的约束下运行。一个 SRS 记忆提示必须在长周期的复习中存活下来。一个今天看到的提示,三个月后再次看到,一年后再次看到,每次都必须能可靠地提示出相同的答案。如果上下文不够明确,或者问题没有引导出对同一细节的一致回忆,那么回忆就会发生偏移,测试效应就会失效。
一些不寻常的提示实际上并不希望每次都提示出相同的答案。例如,你可能会写一个提示来定期反思一句引人注目的名言。但在本文中,我们关注的是旨在强化特定细节的常规提示。
一个好的记忆提示存在于一个狭窄的区间内。它必须足够简洁以便快速阅读,但又必须足够详细,以便在几个月后提示出相同的记忆——同时又不能详细到问题直接暴露了答案。试图将编写优秀记忆提示的过程程序化和描述出来是很有挑战性的,因为其中大量的知识来源于亲身经验。你通过经历失败来学习什么有效。一个提示最初往往看起来不错,但几周后的遗忘会暴露它的弱点。遗忘就是塑造品味的反馈机制。
当这种品味完全依赖于人类自身时,记忆系统就会出现两个结构性瓶颈:
停滞。 提示永远是一成不变的。理想情况下,它们应该随着时间的推移不断演变,以产生更深刻的理解,并随着你兴趣的改变而调整。然而实际上,它们往往会变得陈旧,复习也变得机械化。
需求。 编写好的提示需要付出努力,而好奇心通常不足以支撑这种努力。「值得注意」和「值得付出努力」之间的差距是巨大的。你感兴趣的内容中,只有很小一部分会进入系统。
我们可以通过将机器引入这个循环来解决这些瓶颈,但这只有在它们生成的提示能够经受住长周期复习的考验时才可行。我们在一个最基础的场景下测试了它们是否能做到这一点:休闲阅读中的划线。你的兴趣足以让你标记一段话,但还不足以让你为它写一个记忆提示。
确立问题的前提
在转向内容生成之前,我们首先需要验证一个更基本的假设:划线能捕捉到读者想要记住的内容吗?如果不能,再多的建模也无法恢复这些信号。如果两个读者经常出于完全不同的原因划线同一个句子,那么瓶颈就不在生成环节,而在推断本身。
我们对 42 名经验丰富的记忆系统用户进行了测试。每位参与者阅读三篇文章中的一篇,并使用数字荧光笔高亮他们觉得有趣的任何段落。随后,为了直接获取他们的偏好,我们要求他们从 10 到 13 个预定义的兴趣点中选出他们希望包含在可下载记忆提示集中的内容。
作为一个朴素的基准,我们可以跳过划线和兴趣选择这一步。我们可以直接提供关于文章中每个主题的记忆提示——为每个人提供相同的提示。这将符合当今中心化的可下载提示库的做法。但是,许多记忆系统用户觉得这些题库并不适合他们,我们的数据证实了这一点。我们平均每位参与者需要删除超过三分之一的那些提示,才能与他们的兴趣选择相匹配。
这通常并不是因为提示本身选得不好。读者只是关心不同的细节。当我们测量所选兴趣的重叠度时,平均一致性仅为 39% 。因此,任何「一刀切」的题库必然会包含许多任何特定读者都不想要的提示。
这 39% 的数据(成对的 Jaccard 相似度)排除了 19% 选择了所有可用兴趣的参与者。如果包括他们,相似度将达到 45% 。选择每一个兴趣的参与者并没有提供关于读者之间差异的信息,因此我们在估计分歧时将他们排除在外。
那么,问题在于,我们能否从某一特定读者的划线中推断出他们真正想要记住的内容。在这里,一个简单的测试产生了充满希望的结果。在进行实验之前,我们将每个候选兴趣点映射到文本中的一段代表性段落。如果我们通过将这些预先映射的段落与他们的划线取交集来预测用户的兴趣选择,与朴素基准相比,我们将平均每位参与者不需要的提示减少了一半。
似乎划线可以为读者的兴趣提供强烈的信号。现在的困难在于,如何将这种信号转化为在经过数月时间后仍能可靠提示相同记忆的提示。
参见附录 B 节以获取此实验的更多细节和分析。
怎样的记忆提示才有效
有效的记忆提示必须同时满足两个标准:
- 目标定位: 提示是否捕捉到了用户真正想要记住的内容。
- 提示构造: 提示是否能在较长时间的间隔后,仍然可靠地唤起相同的记忆,并且不会丢失太多细节。
提示可能在任意一个维度上失败。目标定位的失败通常显而易见。你一读到提示,就会立刻意识到它问错了重点,或者问的是你根本不想记住的东西。而提示构造的失败则更难被察觉。它们往往在复习时才会暴露出来,此时由于提示存在歧义、表述不清或过于抽象,会导致回忆过程充满阻力甚至完全遗忘。
这两种失败模式不仅性质不同,代价也不同。定位失败的代价相对较低:你扫一眼就会直接将其否决。而构造失败的代价却很高。它们看起来像模像样,所以你会仔细阅读,尝试回答,直到后来才发现这个提示根本无法支撑稳定的回忆。随着时间的推移,此类提示的不断重复会逐渐削弱你对系统的信任。
为了系统地分析这个问题,我们采用了一种四级分类法:
T3 可直接复习
问:在泰坦星上,重力如此之低,以至于人类只需通过……就能飞行。
答:……拍打手臂(穿着带翼的宇航服)
T2 需要润色
问:由于重力低,人类在泰坦星上会获得什么奇妙的超能力?
答:只要穿上带翼的宇航服,人类就可以通过拍打手臂来飞行。
定位准确,但过于啰嗦,容易造成回忆阻力
T1 需要重构
问:泰坦星的低重力和稠密大气如何影响人类在那里的移动方式?
定位尚可,但结构模糊到根本没法用(存在许多可能的正确答案)
T0 偏离目标
问:泰坦星的哪两个属性使得飞行成为可能?
答:低重力和稠密的大气。
定位到了错误的细节,而且结构存在歧义
基于这一分类法,我们构建了 srs-prompts 数据集,它包含大约 1,500 个基于划线的记忆提示,涵盖 93 个信息来源。这些划线是由作者和一个小规模社区通过在线平台收集的。文章来源主要是技术讲解、博客文章和观点评论——选择这些内容是为了反映真正的好奇心,而非应试学习。每条划线至少配有一个构造良好的提示,以及一个或多个存在缺陷的变体。
目前没有任何现成的数据集涵盖了这个问题。SQuAD 是最接近的替代品,但它只包含简单的阅读理解问题——而不是旨在经受数月复习考验的记忆提示。像 FSRS 这样用于优化调度算法的数据集只包含复习的时间戳,而不包含提示本身。至于公开的 Anki 牌组和 Quizlet 题库,它们完全脱离了原文,是为了考前突击而设计的,无法满足长期的好奇心。同样,也没有任何真实的划线数据集能帮助我们解决这一问题中的「目标定位」环节。
构建这个数据集的过程让我们明确了一个重要的不对称现象:T0 提示的失败代价极低,一眼就能看穿;但 T1 提示却非常具有欺骗性。它们看起来很合理——往往甚至很符合你的需求——但它们根本经不起长期的复习考验。
这里的挑战在于要同时满足两项要求。一个好的提示必须保留那些让细节值得标记的东西——新奇感、情感体验或打动你的独特视角——而不是把它扁平化为干巴巴的冷知识。同时,它又必须足够精确,以至于几个月后依然能准确提示出相同的答案。大多数失败的提示往往顾此失彼。
当经验丰富的记忆系统用户评估一个提示时,他们会调用过去成千上万次的复习经验。他们会将自己带入到未来的情境中,设想在以后的复习环节里,自己会对这个提示作何反应。它还会依然清晰、生动吗?它还能唤起同样的记忆吗?这就是我们所说的「品味」!运用这种品味对认知能力要求极高,并且完全依赖于使用间隔重复系统的亲身经验。
如果想让机器生成获得成功,它就必须能够模拟这种对未来的预测能力。其中的关键界限在于 T1 和 T2 提示的分水岭。T1 提示看似合理,但在复习中效果会衰退;而 T2 提示则能经受住考验。如果模型无法可靠地区分这条界线,它就无法像人类那样预测未来,其输出的结果自然也会暴露出这种缺陷。
2. 模型无法判断质量
我们运行了各种各样的测试,以探索如今的模型是否能可靠地区分提示的质量。在本节的所有实验中,我们向模型提供了一段划线、其对应的上下文,以及一个用于评判的提示或一小组用于选择的提示。
完整的指令模板、精确的过滤规则以及数据集的划分都详见附录。
二元分类
一个最简单的测试是:模型能区分好用的和不好用的提示吗?我们将这四个层级简化为了一个二元决策,我们称之为可用性(pluckability)。如果一个提示在记忆系统里能经得起时间的推移——即达到 T2 或 T3 级,它就是「可用的」。被评为 T0 或 T1 级的提示则是「不可用的」:它们要么偏离了目标,要么本身存在缺陷,无法在长期复习中存活下来。
模型接收到一段划线、上下文以及一个候选提示,然后将其归类为可用或不可用。我们测试了两种指令方案:零样本(仅提供任务描述)和少样本(提供 11 个带有评估解释的示例)。在排除了少样本示例集中出现的来源后,剩下了 1,198 个提示——其中 485 个可用,713 个不可用。
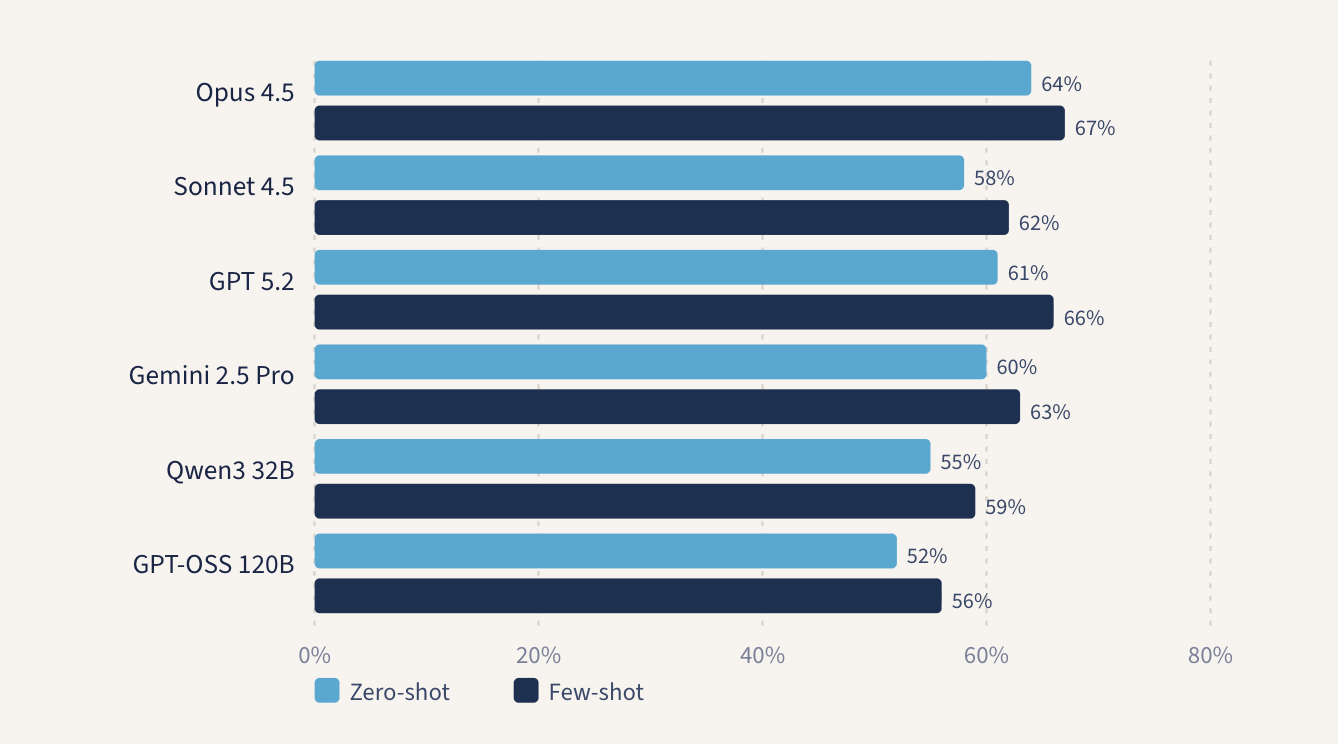
总体表现令人失望地集中在同一个水平。表现最好的几次运行准确率也只在 65% 左右。添加示例和解释稍微有所帮助,但远远不够。
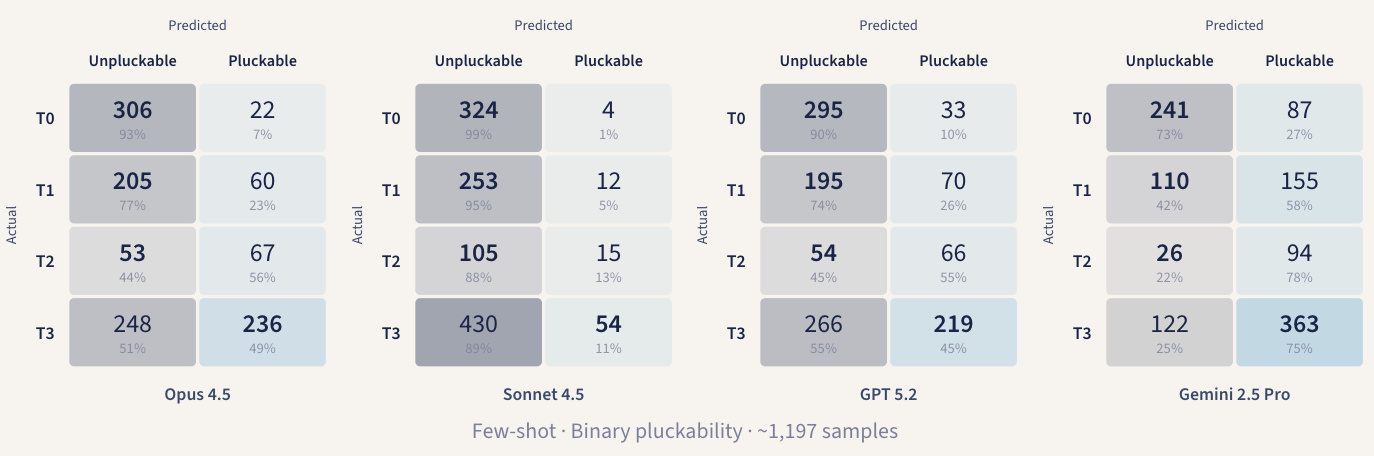
按层级细分的表现揭示了更深层次的规律。Opus 4.5 在将近 93% 的情况下能正确识别出 T0 (偏离目标)提示。它知道提示什么时候偏离了用户划线的内容。问题出在提示的构造上。Opus 4.5 有 77% 的概率能正确地将 T1 提示归类为不可用,但只有 44% 的概率能将 T2 提示识别为可用。Sonnet 4.5 却在相反的方向上翻车了:它过度预测了「不可用」,导致其在识别 T3 提示时准确率仅有 11% 。同样的指令,失败的模式却截然不同。
评分标准
也许模型无法学会「可用性」这个整体概念,但它能够检测出特定的失败模式。这是「LLM 作为裁判」的常规套路:将品味转化为清单,然后要求模型逐项核对。
我们为 srs-prompts 数据集中一部分失败的提示打上了标签,表明它们表现出了以下一项或多项特征:
| 缺少上下文 | |
| 之前 | 之后 |
| 问:附加操作(excise)涉及什么? | 问:根据 Alan Cooper 的说法,什么是附加操作(excise)? |
| 答:不是直接为了达成目标而付出的努力。 | 答:使用某个工具所带来的认知或物理负担。 |
| 「附加操作(excise)」在不同语境下有不同的含义。 | |
| 引出多个答案 | |
| 之前 | 之后 |
| 问:什么导致了 LLM 内存分配中的内部碎片? | 问:在 KV 缓存内存中,内部碎片与外部碎片有什么区别? |
| 原问题有很多种合理的解释。 | |
| 肤浅 | |
| 之前 | 之后 |
| 问:经济学家经常讨论的「生产要素」是什么? | 问:当出现「劳动力 / 土地 / 资本边际收益递减」时,这意味着什么? |
| 答:劳动力、土地和资本。 | 答:这些要素并不是生产中的限制性因素;产能增加 10 倍只能带来极少的收益。 |
| 原问题只是在索要教科书上的清单;而段落的主要见解是关于边际收益递减的。 | |
| 啰嗦 | |
| 之前 | 之后 |
| 问:正如 Marcus Aurelius 所总结的那样,斯多葛哲学如何看待障碍与个人成长和进步之间的关系? | 问:Marcus Aurelius 的斯多葛哲学如何看待障碍? |
| 同样的问题被埋没在徒有形式的修饰语之下了。 | |
| 狭隘 | |
| 之前 | 之后 |
| 问:AI 研究人员常犯的一个错误是什么? | 问:Rich Sutton 的《The Bitter Lesson》(2019)讲了什么? |
| 答:他们经常试图将知识构建到他们的智能体(agent)中。 | 答:人类设计的知识可能会带来短期的收益,但依赖计算和通用学习算法的可扩展方法总是表现得更好。 |
| 原问题只捕捉到了背景(研究人员将知识构建到系统中),却错失了主要观点:从长远来看,计算能力将主导人类设计。(另外,这个问题很模糊,会引出多个答案) | |
对于每一个类别,我们使用合成的示例专门编写了指令,以避免数据集污染。然后我们指派模型独立评判每一项标准。
| 模型 | n_positive | n_negative | 精确率 | 召回率 | f1 |
|---|---|---|---|---|---|
| 有歧义 缺少上下文 | |||||
| Gemini 2.5 Pro | 96 | 96 | 94.0% | 81.3% | 0.87 |
| Sonnet 4.5 | 96 | 96 | 79.6% | 93.8% | 0.86 |
| Opus 4.5 | 96 | 96 | 97.3% | 75.0% | 0.85 |
| Qwen3 32B | 96 | 96 | 85.7% | 75.0% | 0.80 |
| GPT 5.2 | 96 | 96 | 83.0% | 76.0% | 0.79 |
| GPT-OSS 120B | 96 | 96 | 97.7% | 44.8% | 0.61 |
| 有歧义 引出多个答案 | |||||
| GPT 5.2 | 40 | 96 | 37.7% | 72.5% | 0.50 |
| Sonnet 4.5 | 40 | 96 | 36.3% | 72.5% | 0.48 |
| Opus 4.5 | 40 | 96 | 53.1% | 42.5% | 0.47 |
| GPT-OSS 120B | 40 | 96 | 36.5% | 47.5% | 0.41 |
| Gemini 2.5 Pro | 40 | 96 | 41.2% | 35.0% | 0.38 |
| Qwen3 32B | 40 | 96 | 56.3% | 22.5% | 0.32 |
| 狭隘 | |||||
| GPT 5.2 | 48 | 96 | 73.5% | 75.0% | 0.74 |
| Gemini 2.5 Pro | 48 | 96 | 63.5% | 83.3% | 0.72 |
| Opus 4.5 | 48 | 96 | 68.8% | 68.8% | 0.69 |
| Qwen3 32B | 48 | 96 | 96.2% | 52.1% | 0.68 |
| Sonnet 4.5 | 48 | 96 | 51.1% | 93.8% | 0.66 |
| GPT-OSS 120B | 48 | 96 | 60.0% | 50.0% | 0.55 |
| 肤浅 | |||||
| Opus 4.5 | 47 | 96 | 65.5% | 80.9% | 0.72 |
| GPT 5.2 | 47 | 96 | 57.4% | 74.5% | 0.65 |
| Qwen3 32B | 47 | 96 | 60.4% | 68.1% | 0.64 |
| Gemini 2.5 Pro | 47 | 96 | 53.6% | 78.7% | 0.64 |
| Sonnet 4.5 | 47 | 96 | 40.5% | 95.7% | 0.57 |
| GPT-OSS 120B | 47 | 96 | 50.8% | 63.8% | 0.57 |
| 啰嗦 | |||||
| Opus 4.5 | 25 | 96 | 58.3% | 28.0% | 0.37 |
| Sonnet 4.5 | 25 | 96 | 34.5% | 40.0% | 0.37 |
| Gemini 2.5 Pro | 25 | 96 | 42.1% | 32.0% | 0.36 |
| GPT 5.2 | 25 | 96 | 23.8% | 20.0% | 0.22 |
| Qwen3 32B | 25 | 96 | 25.0% | 12.0% | 0.16 |
| GPT-OSS 120B | 25 | 96 | 25.0% | 4.0% | 0.07 |
有些标准被顺利地识别出来了。在所有前沿模型中,「有歧义 缺少上下文」的 F1 分数达到了 0.85-0.87 。其他的则没有。「啰嗦」这一项彻底崩溃了,F1 分数仅在 0.07 到 0.37 之间。
最容易被 LLM 察觉的那些失败,恰恰是与复习记忆提示的亲身体验关联最弱的那些失败。似乎它们无法检测到那些只有通过实际练习才会显现的、关于可回答性和提取对齐中更微妙的崩溃。不幸的是,仅仅基于机器可读标准的评分机制,无法充分代表我们的偏好。
偏好选择
如果绝对判断太难,也许相对判断会容易些。我们用对比的方式重新设计了这个任务:给定一段划线,我们提供 2 到 4 个候选提示(其中一个是 T3 级别,其余是 T1/T2 级别),并要求模型挑选出最好的一个。我们排除了 T0 ,以专注于测试提示的构造质量,而不是那些显而易见的定位失败。这基于 srs-prompts 数据集生成了 90 个对比任务。
这是一个非常宽容的设定。人类评选出的最受偏好的记忆提示存在于每一组选项中。然而,模型依然未能可靠地将其识别出来。模型仅仅在 约 40–50% 的情况下选择了 T3 提示。更糟糕的是,在 约 30–40% 的情况下,模型选择了 T1 ——这个我们最想剔除的层级。即使当「被选中」的标准提示就在选项中时,最强大的模型 Opus 4.5 仍有 32.6% 的概率选择最不受欢迎、结构上存在缺陷的替代方案。
品味无法转移
我们发现,模型能够可靠地拒绝 T0 提示。对于语言模型和人类复习者而言,偏离目标的提示都是代价极低的失败:你一读就能立刻认出它们并不匹配。但 T1 和 T2 之间的界限则不同。对于人类来说,区分这两个层级需要仔细阅读,以及通过数千次复习锻炼出的判断力——这是一种日积月累的直觉,能够感知哪些提示的回忆会发生偏移,而哪些能保持稳定。在我们所有的实验中,模型都未能可靠地区分这两个层级。
没有任何模型在二元分类任务中准确率超过 70% ,而且在识别 T1 上的表现差异巨大。使用评分标准时,模型能够抓住缺失上下文的问题(F1 = 0.87),但在判断一个提示是否会引出多个有效答案时却显得十分吃力(F1 = 0.32–0.50)。即使把最好的提示和三个较弱的替代方案放在一起,模型仍然有大约三分之一的概率选中那个有缺陷的提示。我们可以描述并展示我们的品味,但辨别品味的能力却无法转移给模型。
T1 和 T2 之间的差异绝不是评分上的吹毛求疵。T1 提示会悄无声息地拖垮系统:它们浪费用户的注意力,导致回忆偏移,并随着时间的推移不断侵蚀用户对系统的信任。识别它们需要高度专注,因此用户很难提前将它们筛选掉。一个在三分之一的时间里都在生成 T1 提示的系统,绝对不是我们想用的系统。
3. 训练未能取得突破
如果描述品味行不通,也许我们可以通过训练让模型学会它。我们有大约 1,500 个带标签的样本——虽然不算庞大,但也足以让我们探究这些数据中是否蕴含着可学习的信号。我们按文章来源对数据进行了划分,确保没有任何文章同时出现在训练集和测试集中,最终得到大约 1,300 个训练样本和 200 个测试样本。
触及了天花板,但未能打破它
在最简单的设定下,我们回到了可用性的问题——这次我们训练分类器来预测一个记忆提示是否可用。在设定了合适的阈值后,一个 Qwen3-0.6B 分类器在精确率和召回率的权衡上达到了与少样本提示下的 Gemini 2.5 Pro 相同的水平:精确率 0.60 ,召回率 0.80 。一个 0.6B 的模型能达到比它大几十倍的前沿系统的性能,这很令人鼓舞。但是,当我们使用 LoRA 在同一任务上微调 Qwen3-14B 时,我们发现其 ROC-AUC 几乎完全相同(0.754 对比 0.752)。在不同的操作点上,增加模型容量并没有带来任何有意义的提升。
这种性能上的停滞意味着一些比规模效应瓶颈更严重的问题。较小的分类器似乎利用了与前沿模型相同的表面特征——这些特征足以检测出显而易见的失败,但不足以将 T1 提示从 T2 中区分出来。
达到与前沿模型相同的表现,并不意味着解决了问题。0.60 的精确率意味着,在每十个被认可的提示中,有四个其实是不可用的,而这其中绝大多数都是具有欺骗性的 T1 级别。训练只换来了效率,而非能力的提升。我们只是得到了更廉价的裁判,而不是更明智的裁判。
偏好学习遇到了同样的瓶颈
我们的层级结构隐含着一种自然的偏好顺序:T3 > T2 > T1 > T0 ,而奖励模型被明确设计来学习这种信号。它们不是划定一条硬性边界,而是学习给更好的选项打出比差选项更高的分数。
我们利用基于同一划线的提示构建了偏好对,生成了 353 对训练数据和 93 对评估数据。其中约一半的对比用于测试目标定位(偏离目标对比命中目标),另一半用于测试提示构造。训练完成后,奖励模型在 70% 的保留测试对中更倾向于较高层级的提示。
在目标定位的对比中(T0 对比高于它的任何级别),准确率达到了 77% 。奖励模型能够可靠地学会偏好那些方向正确的提示。但在提示构造的对比中,准确率却降到了 62% 。监督学习可靠地捕捉到了目标定位上的偏好,但未能学会我们在提示构造上的品味。
为什么强化学习救不了我们
我们还尝试了强化学习,特别是 GRPO (群体相对策略优化),试图教会模型在分类前生成推理过程。我们的直觉是:如果模型能学会一步步地分析提示——首先评估目标定位,然后是构造质量,最后是可复习性——它或许就能内化这种判断过程,而不是仅仅对表面特征进行模式匹配。
然而,这种方法并没有带来超出基线的统计学改善。GRPO 通过对意见不一(有的成功,有的失败)的采样生成结果进行学习,并利用这种对比来更新策略。但是,如果一个任务的所有生成结果都得出相同的结论,就不存在梯度信号。
我们测量了跨基础模型的 pass@8 准确率:即每个任务采样 8 次生成结果,至少有一次判断出正确层级的频率是多少?最强的模型 DeepSeek V3.1 达到了 60% 的准确率。但在 212 个任务中的 116 个里,所有 8 次生成结果都是一致的——要么全对,要么全错。没有对比,就没有梯度,GRPO 也就无从学习。数据集本来就很小,强化学习让有效数据变得更少了。
针对特定领域的预训练或许是一个潜在的补救措施:如果模型对构造质量拥有更强的先验知识,它或许能在每个任务中生成更多样化的结果,从而恢复 GRPO 所依赖的对比信号。但这仍有待探索。
记忆提示的数据成本高昂
我们有约 1,500 个样本。也许如果数据量增加十倍或一百倍,模型就能展现出对提示构造的品味。但在实际操作中,收集此类数据非常困难。
划线数据需要模拟,而不是简单的识别。 评估人员必须理解源材料,推断出划线内容反映了什么有趣的信息,然后模拟在长时间复习中遇到这个提示会是什么感觉。构造质量并不是停留在表面的属性。它取决于对多次复习中可能出现的歧义、记忆偏移和新鲜感丧失的预判。
现有的 SRS 社区并不太适合承担这项任务。他们大部分时间都专注于冷知识、语言学习或备考。而本文提出的这种以划线为核心、由好奇心驱动的工作流,无论在动机还是实践上都与他们截然不同。通过众包来收集标签,将需要先教授他们一套全新的工作流,且初期会被质量低劣的提示所充斥。高质量的数据标签需要高度投入的用户,而高度投入的用户需要优秀的提示作为前提。
复习行为发出的信号是混杂的。 另一种思路是:跳过人工划线,直接从用户的实际复习行为中推断提示质量。顽固提示(Leeches,即那些永远稳定不下来的提示)可能意味着构造上存在问题;而被废弃的提示可能意味着目标定位不佳。但在我们的场景中,每个用户都在为不同的文章创建提示。一个提示被废弃,可能是因为它的构造太差,但也可能仅仅是因为用户的兴趣消退了。
用户的偏好仅仅代表「错得最少」,而不是「完全正确」。 当在多个记忆提示中做选择时,用户很少有一个非常明确的目标:他们往往只是想抓住某个特定的细节或视角,他们能辨认出那个感觉,但无法清晰地表达出来。面对两个都不完美的选项,他们会选择那个偏离较少的一个。偏好信号所编码的,只是提示与某个未明言目标之间的接近程度,而不是对该目标的完全满足。用户真正想要的那个完美提示,根本就没有出现在数据中。
当规模足够大时,信号或许能从这些噪音中浮现出来。但要克服这种数据失真,我们需要的数据集规模将比我们现在拥有的要大上好几个数量级。
4. 通过引入基准参考来避开品味转移
训练遇到了与提示工程相同的瓶颈。这两种方法都没能教会模型区分 T1 和 T2 的边界。在评分标准、偏好学习和微调的实验中,失败的模式如出一辙:那些至关重要的提示构造元素,恰恰是模型最无能为力的地方。既然这种品味无法转移给模型,我们就必须找到一条不依赖品味转移的破局之路。
于是我们改变了提问方式。与其问一个提示是否符合所谓「好提示」的抽象理论,不如问它与同一段划线的其他提示相比究竟孰优孰劣。我们向模型展示从同一段落中提取出的一些带有标签的示例——也就是我们已经评定过等级的提示——然后要求它将一个新的候选提示归入其中。模型通过局部的对比来进行判断,而不是在真空中孤立地进行评估。这种引入基准参考的方法,就不再依赖于品味的转移了。
我们要求这个引入了基准参考的裁判模型预测完整的四级评分,然后将其预测结果折叠为可用性(pluckability)的二元分类(即 T2/T3 对比 T0/T1)。这让我们不仅能测试基准参考是否提高了模型细粒度的辨别能力,还能测试这种提升是否能真正转化为在那个至关重要的边界上更好的分离效果。
Krumdick 等人也使用了相同的策略:用人类编写的参考资料为 LLM 裁判提供基准,而不是让它们孤立地进行评估。
事实证明确实有效——但也伴随着权衡。使用 Sonnet 4.5 ,在引入基准参考后,层级分类的整体准确率从 39% 上升到了 49% 。更重要的是,可用性判断的精确率从 56% 跃升至 78% ,假阳性率从 52% 降至 17% 。裁判模型变得更加保守:它认可的提示变少了,但那些被它认可的提示成为真正可用提示的可能性却大大增加了。这是第一次,错误的分布方式与复习的成本结构对齐了。T1 提示——那些代价高昂的失败——被更频繁地揪了出来。
Claude Opus 4.5 在同样的方案下表现得更差。
混淆矩阵让这种转变清晰可见。虽然 T1/T2 边界依然不够完美,但矩阵的对角线变得更加清晰,而不是像之前那样糊成一片。在三次独立的测试中,人类与模型在可用性判断上的一致性达到了 κ = 0.61 ± 0.03 ——这一水平已经足够高,可以支持数据聚合和后续的对比工作了。
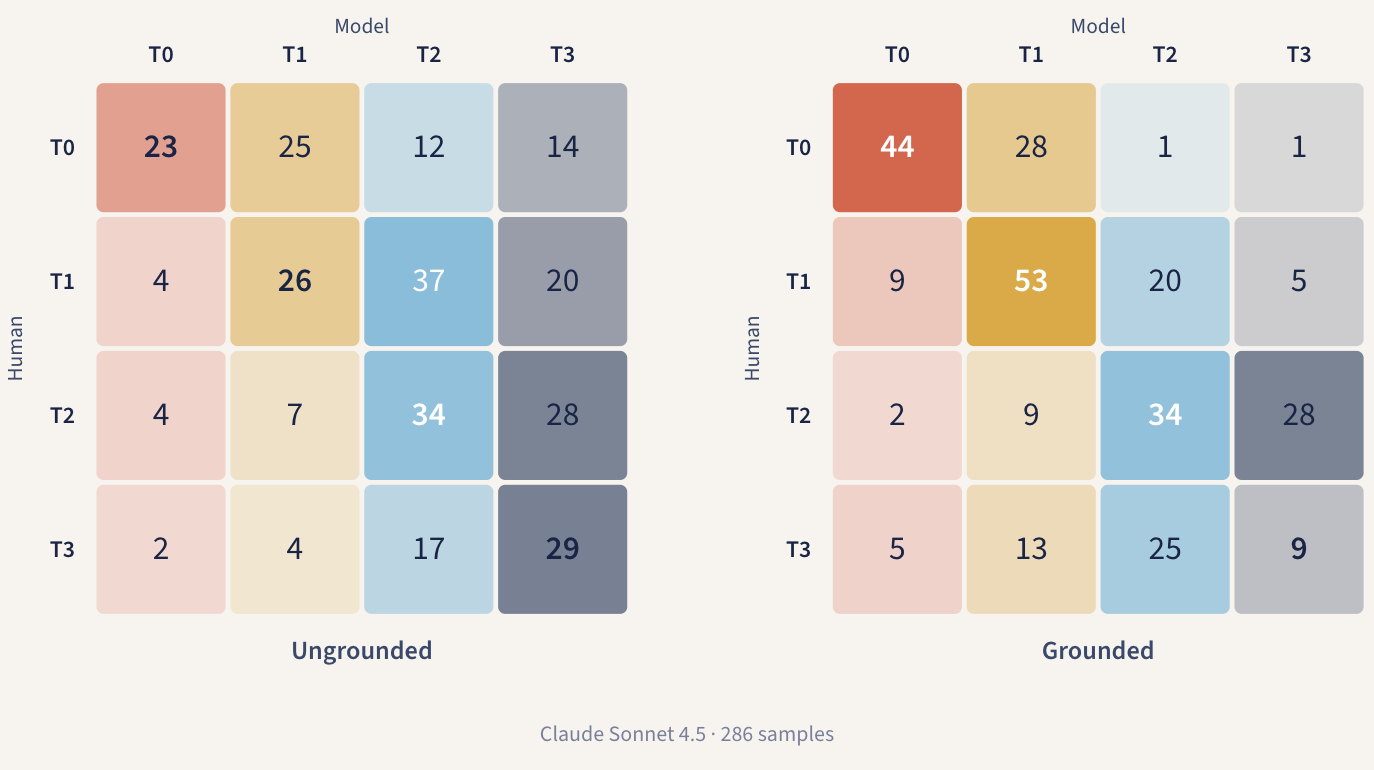
在这种配置下,T3 的准确率较低,因为在引入基准参考的过程中,标准的 T3 提示被从参考集中隐藏了。模型只能通过与带有标签的 T1 和 T2 示例进行比较,然后依靠外推来识别 T3 。
有了基准参考,模型不再需要学习怎样才算是一个普遍意义上的好提示。它们只需在局部上下文中对候选提示进行比较即可。我们不再试图转移我们的品味,而是将其编码在这些带标签的示例中。这种方法为我们提供了一个评估框架,即使在我们更换模型、调整指令或改变其他变量时,它也能大致保留我们的判断偏好。
5. 模型的生成能力究竟有多差?
基准参考为我们带来了新变化:一种足够稳定并可用于衡量的评估标准。这个裁判模型并不完美——它在相当大的比例上仍然会混淆 T1 和 T2 ——但它的错误具有一致性。当它认可一个提示时,这个提示真正可用的概率远远高于之前任何方法评估出的提示。这足以让我们终于能够回答一个问题:大语言模型在生成提示方面究竟有多差?
我们用前沿模型处理了相同的一组划线,并让带有基准参考的裁判对所有输出进行了评分。为了验证这种评估方式确实能够检测到生成质量的下降,我们加入了一个对照组:给 Gemini 2.5 Pro 下达了“死记硬背式(trivia-style)”的指令,要求它生成那种字面的、脱离语境的问题。这正是我们的分级标准旨在惩罚的提示类型。如果裁判不能将这些与真正符合要求的生成区分开来,那么这个基准测试也就失去了意义。
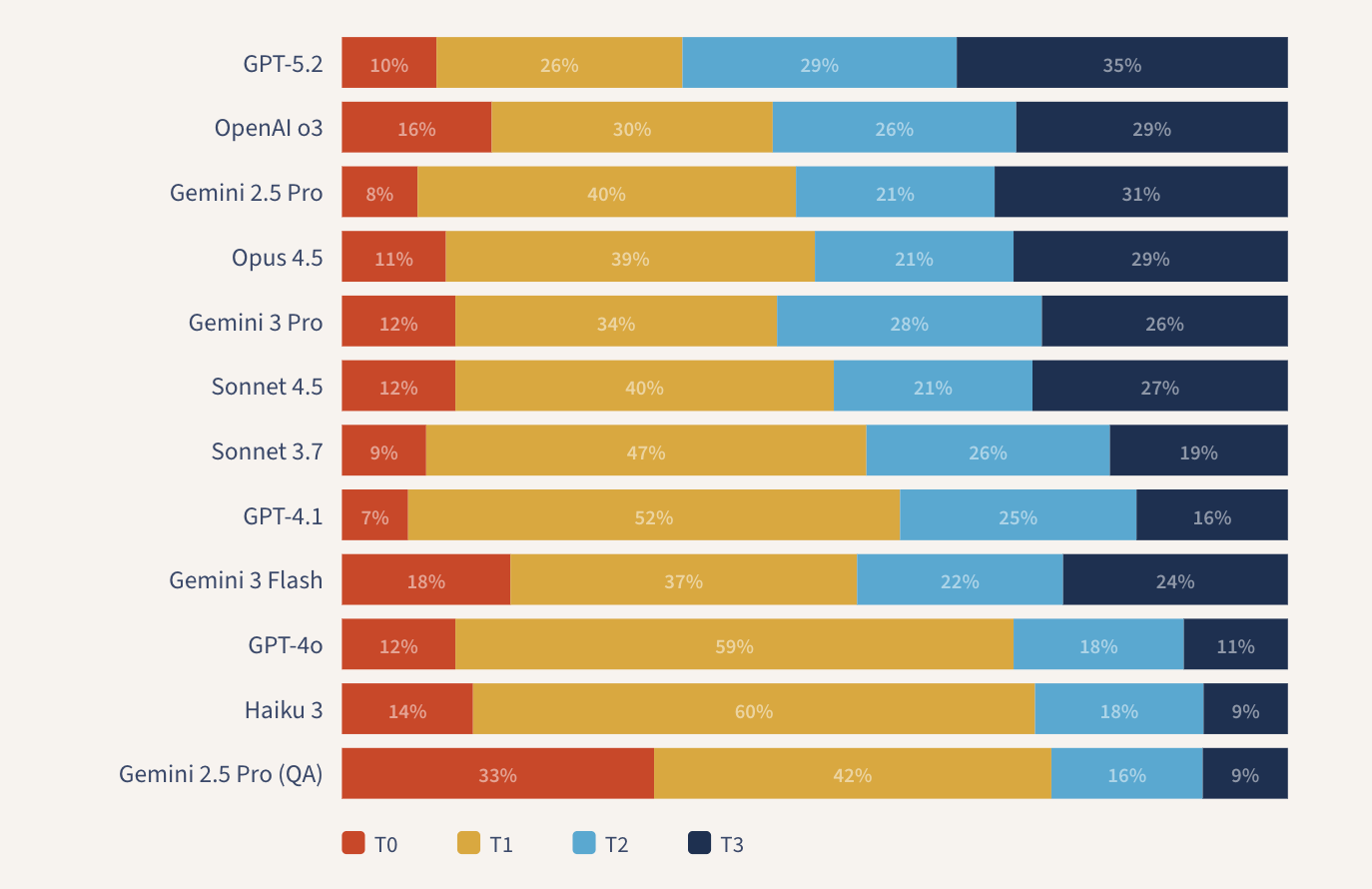
在死记硬背式的指令下,Gemini 2.5 Pro 生成了 33% 的 T0 和 42% 的 T1 提示。它四分之三的输出都是不可用的,并且有三分之一甚至完全偏离了目标。而同一模型在使用正确指令时,生成了 8% 的 T0 和 40% 的 T1 。单从 T0 比例的巨大差距就能确认,裁判模型对目标定位的失败是非常敏感的。而相近的 T1 比例也是合乎情理的:因为即使提示恰好切中了主题,这类死记硬背式的问题如果没有经过精心构造的措辞,通常也无法经受住长期的复习考验。
在其余的模型中,T0 的比例普遍较低——大多数在 10% 左右,少数略高。这说明模型现在很少会完全偏离目标了;主要的失败模式在于提示的构造。
一年前,T1 比例的问题非常严重:GPT-4o 高达 59% ,Claude 3.7 Sonnet 为 47% ,GPT-4.1 为 52% 。2025 年末发布的模型确实取得了明显的进步。GPT-5.2 将 T1 的比例降到了 26% 。Gemini 3 Pro 则降到了 34% 。然而,即使是我们测试过的最强大的模型(GPT-5.2),仍然有大约三分之一的时间在生成不可用的提示。
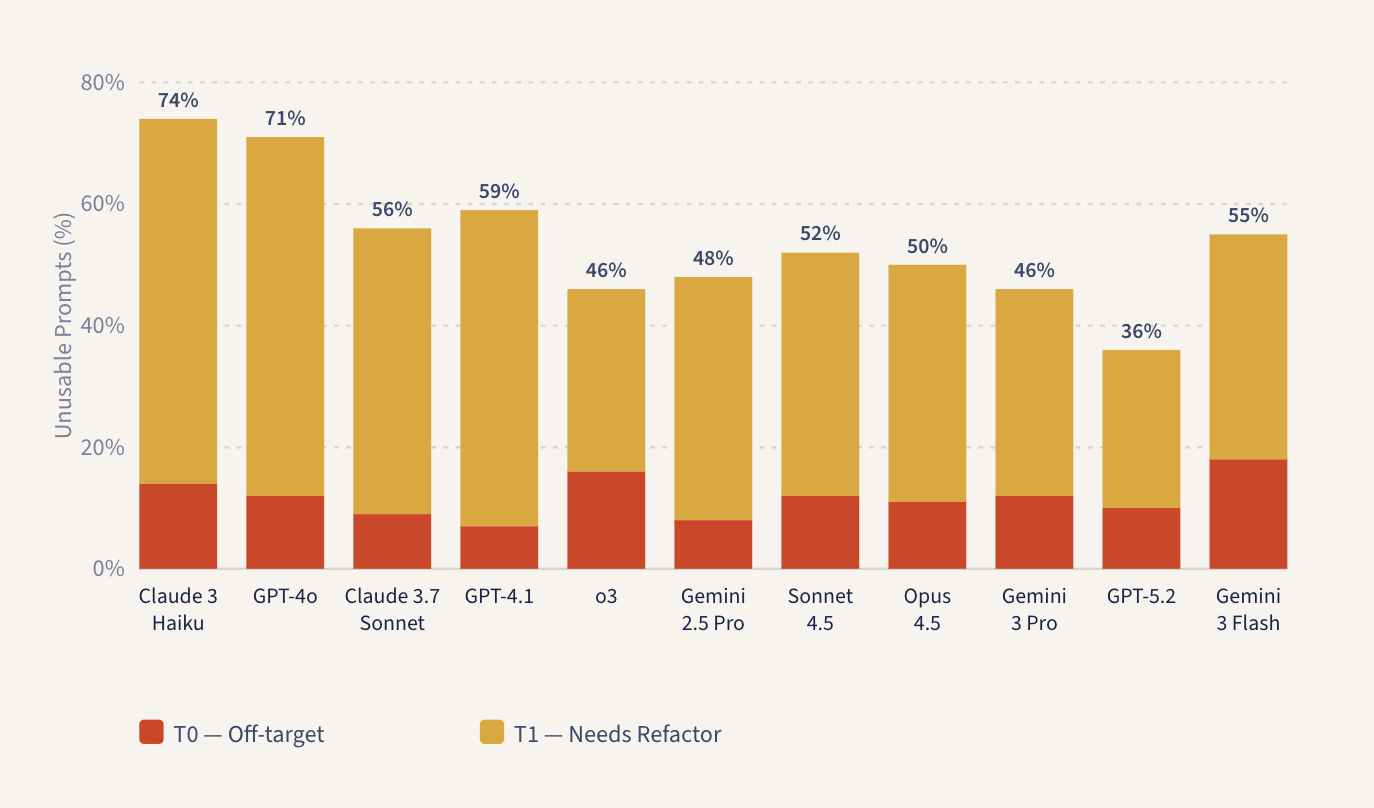
6. 模型竞技场
第 5 节中的分级数据能说明一些问题,但它们并未反映出用户的实际体验。
想象一下针对同一段划线的两个生成流程。流程 A 生成了四个提示:三个 T1 和一个 T3 。流程 B 生成了两个提示:都是 T2 。如果光看分级分布,流程 A 似乎更好——因为它拥有唯一的 T3 。但在实际使用中,流程 B 往往更受青睐。因为流程 A 的用户必须忍受并阅读三个存在缺陷的提示后,才能找到那个真正管用的。每一个 T1 都需要用户仔细去辨别。但并非所有的错误代价都一样。T0 提示往往错得很明显——你一眼就能毙掉它们。但从复习成本的角度来看,T1 才是最糟糕的失败模式。我们在评估模型时必须考虑这一点。
对成本敏感的评分机制
为了比较不同流程而非单个提示的优劣,我们需要一个考虑到模型产出全貌的评分函数——既要奖励优质的提示,又要惩罚其余无用提示带来的筛选负担。
基于这种不对称性,我们对效用进行了赋值:T0 = −1.0,T1 = −3.0,T2 = +1.5,T3 = +2.0。负值代表负担;正值代表有效的贡献。但请记住,我们的裁判是不完美的。它在很大程度上仍会混淆 T1 和 T2 。如果我们直接采信它的预测,就会将这些错误也继承下来。因此,我们利用了在“人类-裁判一致性研究”中得到的混淆矩阵来计算后验预期效用。当裁判预测某提示为 T2 时,这些预测中有一部分实际上是它误判的 T1 提示。
我们应用贝叶斯定理,计算出裁判在每种预测下提示真实等级的数学期望,然后乘以如上所列的成本。经过校准后,得出的预期效用如下:
裁判评定 T0 → −1.10 · 裁判评定 T1 → −1.43 · 裁判评定 T2 → +0.50 · 裁判评定 T3 → +1.02
请注意,裁判评定为 T2 的预期效用仅仅是微弱的正值。这反映了“ T1 泄漏”问题:裁判混淆 T1 和 T2 的频率太高,以至于即使是很小的误判概率也会大幅拉低预期值。这是我们在设计上有意保持的保守态度——我们宁愿低估那些处于边界上的提示,也不愿让代价高昂的失败漏网。
对于每个产生预期效用提示组合的(模型,划线)对,我们计算一个综合得分(completion score):
公式的第一项代表收益:一批提示中最好的那一个决定了效用的上限。第二项代表成本:所有负效用的提示都会增加复习负担,不管这批提示里有没有好提示。根据这个公式,包含一个 T3 和两个 T0 的组合得分,会低于包含两个 T2 的组合——因为前者虽然包含高质量提示,但浪费了复习者的时间。通过这种设计,我们修正了裁判模型的误判偏差,并将评分机制与实际的复习成本对齐了。
结果
我们借鉴了“模型竞技场(arena)”式的基准测试来比较不同的生成流程。对于每一段划线,模型只接收最基础的指令和完整的源文本,然后执行生成提示的任务。我们没有引入任何中间的转换步骤,因此性能差异纯粹反映的是生成质量,而不是上游的过滤处理。带有基准参考的裁判对每个提示进行评分;组合的综合得分决定两两对决的胜者;最后通过 Elo 评分系统将结果汇总为全局排名。
| # | 模型 | Elo | 胜率 |
|---|---|---|---|
| 1 | GPT-5.2 | 1634.2 | 54.0% |
| 2 | OpenAI o3 | 1591.2 | 47.6% |
| 3 | Gemini 2.5 Pro | 1571.1 | 46.7% |
| 4 | Claude Opus 4.6 | 1548.3 | 46.2% |
| 5 | Claude Opus 4.5 | 1547.0 | 45.4% |
| 6 | Gemini 3.1 Pro | 1535.3 | 42.6% |
| 7 | Gemini 3 Pro | 1534.5 | 46.9% |
| 8 | Claude Sonnet 4.5 | 1496.6 | 42.7% |
| 9 | GPT-4.1 | 1488.8 | 35.0% |
| 10 | Claude Sonnet 3.7 | 1488.6 | 37.7% |
| 11 | Claude Opus 4.7 | 1468.0 | 42.3% |
| 12 | GPT-5.4 | 1466.7 | 38.4% |
| 13 | Gemini 3 Flash | 1456.9 | 38.5% |
| 14 | GPT-4o | 1433.3 | 27.5% |
| 15 | Claude Haiku 3 | 1405.1 | 27.5% |
| 16 | Gemini 2.5 Pro (QA) 对照组 | 1334.5 | 22.7% |
由 Claude Sonnet 4.5 评判 · 每对对决 5 次
方法: 带有位置去偏的成对比较
数据集: 200 个提示,按主题分层
一个助力进步的原型
竞技场仅仅是一个原型,而不是一个最终完善的基准测试。目前仍有几个误差来源存在。
裁判模型具有随机性。同一个提示在多次评估中可能会得到不同的评分,而且单次比较的结果也充满了噪音。在较低的生成温度(temperature)下运行微调过的裁判模型,将有助于减少这种方差。即便准确率没有提高,更具确定性的推断也会产生更稳定的排名。
现有的提示是各自独立进行评判的,在同一场对决中缺乏全局视角的仲裁。一个模型的输赢,部分原因可能仅仅取决于裁判在那次调用中的状态如何。如果能在同一次推断过程中,同时对同一段划线的两个生成结果进行评分,就能在每次对决中强制执行统一的评判标准。
我们的成本赋值(T0 = −1,T1 = −3,T2 = +1.5,T3 = +2)更多是基于对复习负担的直觉,而不是经过直接测量得出的。如果能开展受控研究,让人类来复习已知层级的提示,就可以将这些权重建立在实际观察到的行为基础之上。
尽管存在这些局限性,但这个框架依然推动了进步的发生。当我们将大量的比较结果汇总起来时,我们就能看到不同生成流程之间稳定的差异。竞技场并没有解决“品味转移”的问题。但它为我们提供了一种方法,让我们能对提示生成器和裁判模型进行迭代,即使个别裁判的结果仍然存在噪音且不可靠,我们也依然能够追踪到进步的轨迹。
结论
在我们包含约 1,500 个记忆提示的数据集中,我们发现模型在检测偏离目标的提示时通常表现得很好。目标定位的能力很大程度上已经转移给了模型。但在我们测试中排名最高的模型 GPT-5.2 ,仍然有 36% 的概率会生成不可用的提示。模型的失败恰恰发生在对间隔重复至关重要的那条边界上:它们无法区分一个看似合理的提示,究竟是能在较长的时间跨度内可靠地强化目标记忆(T2+ 级),还是会带来困惑与复习阻力(T1 级)。
无论是在评估环节还是生成环节,模型都很难辨别 T1 和 T2 之间的界限。我们在评分标准研究中得出的发现也印证了这一点。模型最擅长评判那些不需要实际复习就能看出端倪的标准:比如缺失上下文、表面上的歧义、肤浅的措辞等。而它们最不擅长评判的,恰恰是那些只有通过反复使用才会显现出来的构造特性:比如提示的清晰度和答案的稳定性。
我们曾试图通过提示工程、评分标准、偏好数据和模型训练来弥合这一差距。其中,引入基准参考(Grounding)带来的效果最显著:当向模型展示同一段划线中带有标签的提示作为参考时,评分判断的精确率从 56% 跃升至 78% 。但即便有这种在实际中难以实现、却极其有用的基准参考辅助,模型在 T1/T2 边界上的评分依然不够可靠。
无论如何,模型竞技场还是让我们取得了进展。通过对那些充满噪音的裁判结果进行汇总,它揭示了不同模型和生成策略之间稳定、相对的差异。即使缺乏一种能完全转移人类判断力的裁判方法,这也为我们提供了一个可供衡量的基准,以及一个指引未来研究去不断改进评估与生成技术的指南针。
记忆系统的用户通过在日复一日的复习中留意哪些提示能够长久留存,从而培养出了判断优秀提示的“品味”。我们可以在评分标准这类技术中去近似模拟这种品味,也可以粗略地对它进行衡量。但至于如何将我们在这些复习体验中获得的品味更完整地转移给机器,目前仍是一个悬而未决的问题。
致谢
我们感谢 Giacomo Randazzo 审阅了本文的早期草稿,也感谢 Piergiacomo De Marchi ,Andrew Mayne ,Nic Becker ,Stefan Djokovic ,Julian Alvarez 和 David Holz 提供的有益探讨。文中的所有错误均由我们自己承担。
附录
参考文献
Krumdick, M., et al. (2025). No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding. arXiv:2503.05061
Nielsen, Michael A. (2018). Augmenting Long-term Memory. http://augmentingcognition.com/ltm.html
Shao, Z., Wang, P., Zhu, Q., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300
Zheng, L., Chiang, W., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS 2023. arXiv:2306.05685
资金致谢
这项研究的主要资金由 cyber•Fund 提供。
额外的资金支持由 Andy’s Patreon community 提供。特别感谢截至 2026 年 4 月的赞助级别的支持者:Adam Marblestone,Adam Wiggins,Andrew Sanchez,Andrew Sutherland,Andy Schriner,Ben Springwater,Bert Muthalaly,Boris Verbitsky,Calvin French-Owen,Dan Romero,David Wilkinson,Dylan Houlihan,fnnch,Greg Vardy,Heptabase,James Hill-Khurana,James Archer,James Lindenbaum,Jesse Andrews,Kevin Lynagh,Kinnu,Lambda AI Hardware,Ludwig Petersson,Maksim Stepanenko,Matt Knox,Michael Slade,Mickey McManus,Mintter,Patrick Collison,Peter Hartree,Ross Boucher,Russel Simmons,Salem Al-Mansoori,Sana Labs,Thomas Honeyman,Todor Markov,Tooz Wu,William Clausen,William Laitinen,Yaniv Tal。
在学术研究中,请按如下格式引用本文:
Ozzie Kirkby and Andy Matuschak, “Memory Machines: Can LLMs create lasting flashcards from readers’ highlights?”, Memory Machines: Can LLMs create lasting flashcards from readers' highlights?, San Francisco (2026).
Thoughts Memo 汉化组译制
感谢主要译者 gemini-3.1-pro,校对 Jarrett Ye
原文:Memory Machines: Can LLMs create lasting flashcards from readers' highlights?
作者:Ozzie Kirkby 和 Andy Matuschak