
问题描述
最近要做多义词消歧,最好利用到wordnet或hownet。有没有什么推荐的论文呢
Python 有一个词义消歧的库,用到了 WordNet:
alvations/pywsd: Python Implementations of Word Sense Disambiguation (WSD) Technologies. (github.com)这个库的原理很简单,就是将多义词的上下文和该多义词在 WordNet 中的释义(英英释义)计算相似度,然后给出相似度最高的释义项。这个相似度有不同的算法,最简单的就是将上下文的单词作为集合 A,释义项中的单词作为集合 B,然后用 A B 交集的元素数量作为相似度。
不过这个方法有点原始,并不能很精确地给出一些生僻释义。另外 WordNet 里的释义项和单词的应用语境在绝大多数情况下并不匹配。若要计算相似度,应当是在该释义下的相关例句与多义词的上下文之间进行。
当然,好处也是有的,那就是上述算法不需要训练模型,只需要有 WordNet 这样的语料就行了。
若要更进一步,那么可以考虑一下词向量了。词向量就是用一个向量表示一个单词。那么每个单词之间就可以计算余弦相似度。代入多义词消歧义的场景中,我们关心的是计算特定上下文中的多义词,与该单词在词典中的多个释义项中哪一项最相似。用词向量的角度来考虑,就是如何计算特定上下文中的单词对应的词向量,和词典中每个释义项对应的词向量。
其实还挺简单的,调 BERT 就可以了:
BERT Word Embeddings Tutorial · Chris McCormick (mccormickml.com)给 BERT 输入一个句子,它会输出整个句子中每个单词的词向量,该词向量是上下文相关的,可以代表单词的语境含义。
至于释义项的词向量,则可以用相关例句来作为上下文输入 BERT 得到。如果有多条例句,把每条例句中对应的多义词的上下文词向量取平均即可。
效果展示:
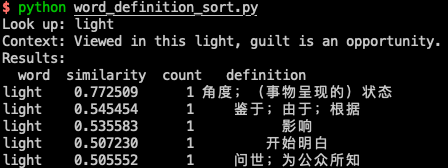
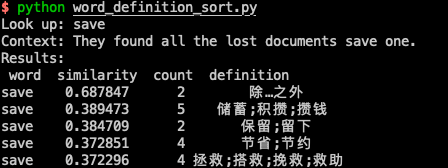
差不多就是一个更准确的查词工具。
另外这个效果也只是用了 BERT 的预训练模型,并没有 fine-tune,所以应该还有提升空间。
另外,GPL-3 也会词义消歧任务:

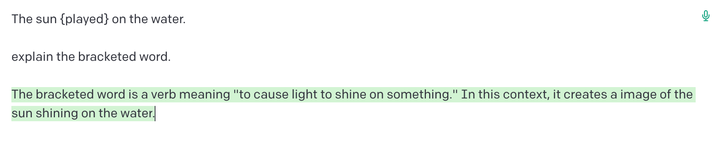
另外我在 Hugging Face 上也找到了一个做类似任务的模型:
https://huggingface.co/jpwahle/t5-word-sense-disambiguation希望以上内容对你有所帮助。