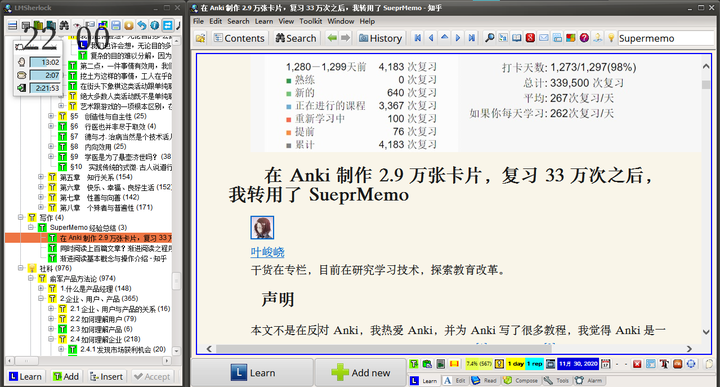

通过前几期的教程介绍,渐进阅读所必须的操作已经教给大家了,希望大家已经开始实践渐进阅读。本文将介绍几种常见阅读材料的导入方法,并介绍如何管理大量导入的材料。
希望各位已经掌握渐进阅读的基础操作后再阅读本文。
对于已经掌握操作,但是还不知道如何处理自己手头材料的朋友,可以阅读渐进阅读中加工知识的示范:
06 示范:增量学习中的实际操作 · 语雀再次强调:材料本身的样式远远没有知识表述重要,在 SuperMemo 里折腾样式就是买椟还珠了。很多卡片不值得你去花时间改样式,请大家自己考虑成本与收益。
如果你仍然不能忍受不完美的卡片样式,那就专心将他们美化吧。没有什么能阻止它们变得完美,这些完美的卡片可能倍受你的喜爱,但你的学习速度肯定也会降低了。[1]
选择最合适的导入材料
不同材料的导入难度不同,我推荐大家在导入材料前先找找看有没有更合适的替代材料。以下是我对材料格式的推荐顺序:
- 网页(Wiki、Blog、『知乎专栏』)
- 电子书(EPUB)
- 有文字层的 PDF(就是可以复制文本的那种)
- 扫描版的 PDF
SuperMemo 官方文档也是这样提倡的:
与其为了增量阅读而扫描纸质书籍和进行OCR,还不如从寻找电子图书开始。在大多数基础知识领域,都有多种学习材料来源。需要扫描的情况越来越少。现在,你甚至可以更挑剔一些,搜索HTML文本来代替PDF材料(以避免将PDF转换为HTML的痛苦)[2]
接下来,我会逐个介绍上述材料的导入方式,希望对大家进一步使用 SuperMemo 进行渐进阅读有所帮助。
注意:
- 先从网页材料开始
- 先从你感兴趣的材料开始
- 先从你收藏夹里吃灰的材料开始
复制粘贴
复制粘贴绝对是首选的添加材料的方式。这里注意一下,请勿使用 IE 浏览器打开网页复制内容,极有可能遇到图片无法在 SuperMemo 中正常显示的问题。
粘贴快捷键 Ctrl + N,使用方法为:选中你想要阅读的文字内容,复制,再打开 SuperMemo,Ctrl + N 即可自动创建相应的摘抄卡片。
如果遇到文本格式问题,请使用我编写的 Quicker 动作:
统一格式 - 已分享的动作 - Quicker网页批量导入(IE 快要没了,不推荐)
由于历史原因,SuperMemo 还是基于 IE 核的,所以 SuperMemo 的批量导入也是针对 IE 浏览器的。

想要导入多个网页的内容,请用 IE 打开它们。
然后在 SuperMemo 中使用快键键 Ctrl + Shift + A,或在菜单里找到这个:
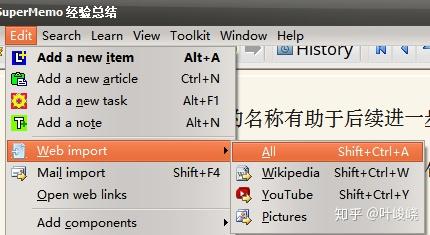
呼出批量导入页面后,
- 点击 Check all 可以勾选所有要导入的牌组;
- 在 Concept group 可以选择要导入到哪一个概念组;
- mode 选择 Local page (whole web pages) 即可;
- priority 有一个最大值和最小值,根据自己对优先级的判断进行修改即可。
最后点击 Import 即可导入
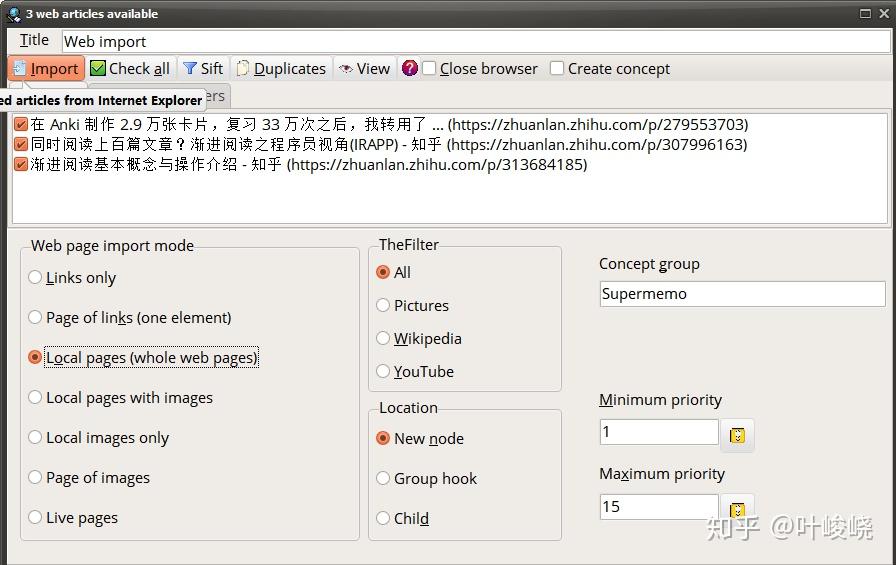
导入后的效果如下,配合前文《渐进阅读懒人样式 - 知乎 (zhihu.com)》的样式去除动作可以获得更好的阅读体验。
SuperMemo 自带的格式去除快捷键是 Ctrl + Shift + F12
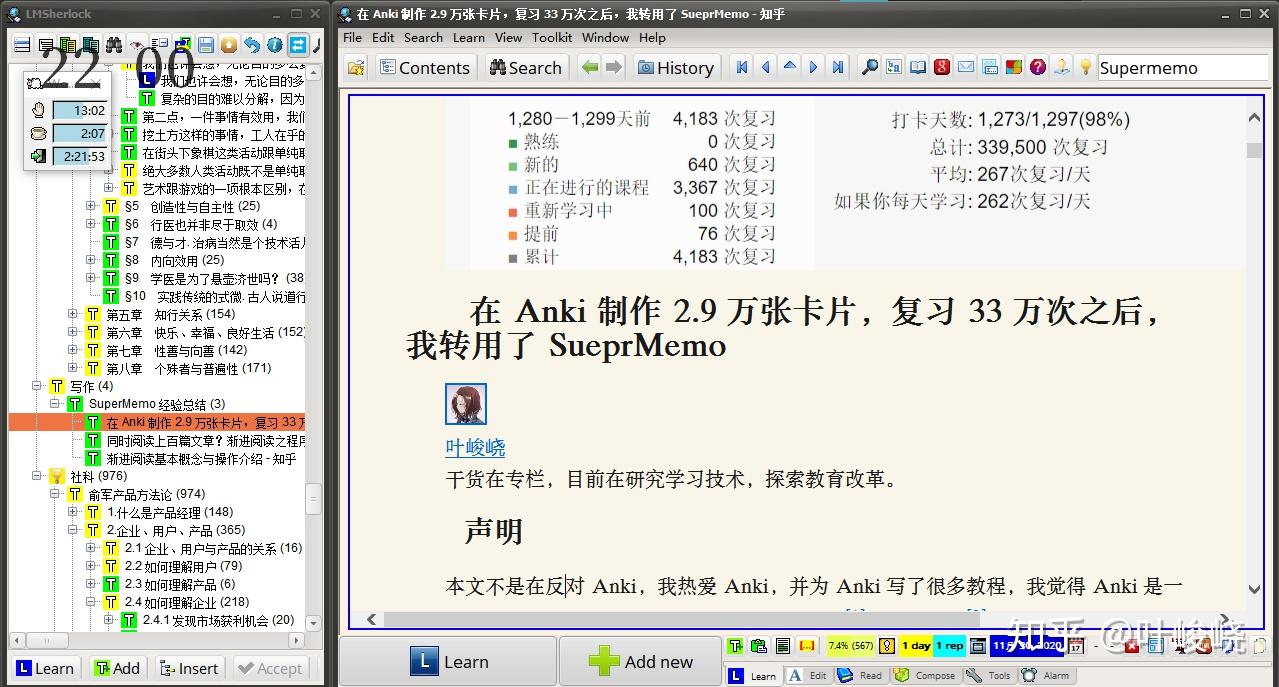
电子书导入
对应 EPUB 格式的电子书,最方便的导入方法就是,将电子书的后缀改成 zip,然后用解压软件解压,就会得到一个装着一堆 html 的文件夹。用 IE 打开这些 html 文件,再用前面介绍的 web import 导入即可。
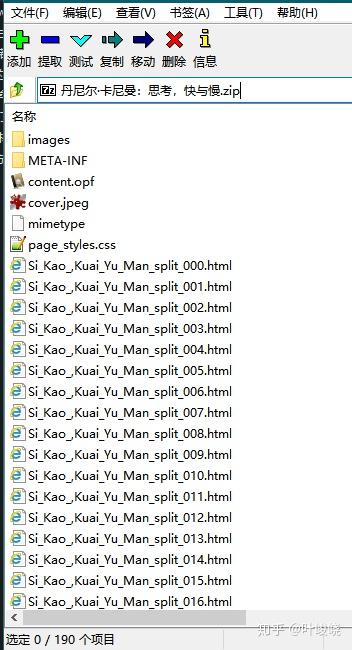
azw3 和 mobi 类型的电子书请先转换成 epub,我自己平时用 calibre。
如果没有 IE 了,请参考:
如何在supermemo中阅读一本书?PDF 导入
大部分教科书的电子版都是 PDF,关于这一点,SuperMemo wiki 是这样提示大家的:
如果你迫于考试的最后期限,仍然不能很好地进行增量阅读,那么并行地进行一些新-老方法混合的学习会更有意义。例如,30%的增量阅读和70%的传统学习。你一定会在安排学习计划上犯很多错误,或许探索时间比距离考试的时间还长。一开始你需要花费很多成本(学习计划,选择学习材料,表达方式,学习使用SuperMemo等等)。如果你第一次考试真的考砸了,那就不足为奇了!你可以选择一些你特别喜欢的章节,并在你的增量学习实践中使用它们。然后,您再使用旧方法处理其余的材料。你不可能在感觉到如何做得对之前,就着手把教科书大规模地转换成SuperMemo里的学习材料!它会适得其反,并使你厌恶SuperMemo。请谨慎地、循序渐进地进行。[2]PDF 在之前一直是我的噩梦,建议非专业人士能复制就靠复制吧,今天看哪一章就复制哪一章的内容进去。不过这可能会遇到换行问题,也就是 pdf 复制出来可能会一行一段,非常影响阅读。这里推荐一个阅读器:Xodo

从 Xodo 中复制出来的文本会智能分行(当然,没有 ABBYY 准,但是它免费啊),这样贴到 SuperMemo 中就方便许多。
如果觉得这样复制粘贴太慢了,建议用一些 PDF OCR 软件将 PDF 转换成 TXT,比如这样:

然后再把 txt 里的内容粘贴到 SuperMemo,一次可以贴很多。
当然,由于这个 txt 会非常长,建议分段粘贴。
如果还嫌这样麻烦的话,我这里可以分享一下我写的 python 脚本(非程序员可以退避了,这里提供我的思路),仅供参考:
import re
filename = "人工智能" # 文件名
with open(filename + ".txt", 'r', encoding="utf-8") as f:
split_txt = None
for line in f:
if re.match(r"[0-9]\.[0-9]\.[0-9]", line): # 按照三级标题切分
split_txt = open(filename+"/" + re.sub(r'[\/:*?"<>|\t\n]', '', line) + '.html', 'w', encoding="utf-8") # 写入 html 文件
split_txt.write('<p>'+re.sub(r'[\t\n]', '', line)+'</p>')
else:
if split_txt:
split_txt.write('<p>'+re.sub(r'[\t\n]', '', line)+'</p>')
else:
continue切分后的效果图:
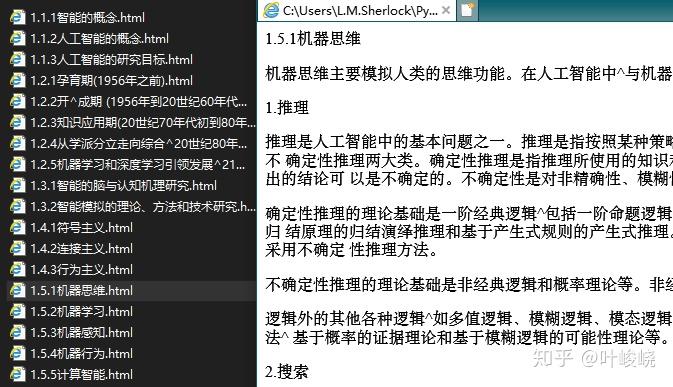
导入效果:
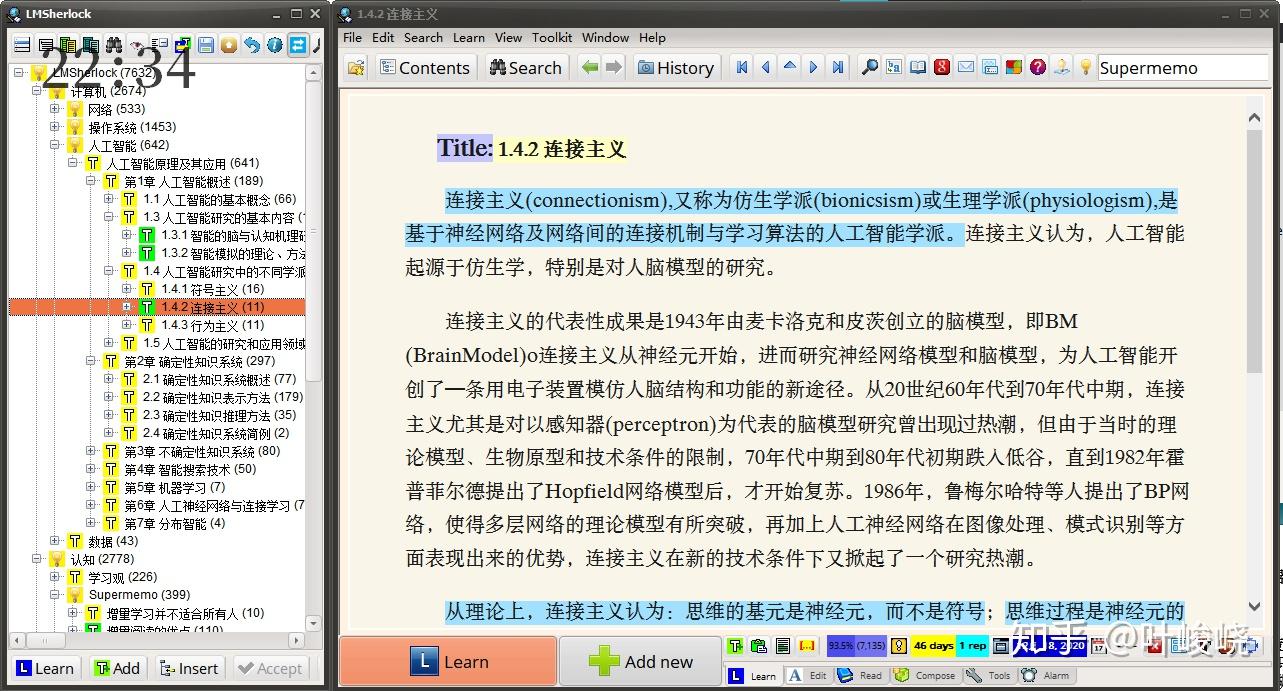
这样虽然效果很好,但是又引来了下面这个问题:
管理大量导入材料
如果我们平时导入个十几篇文章,互相之间没有太多的依赖关系(就是没有严格的阅读顺序)的话,那么 SuperMemo 自动安排的阅读间隔就足够用了。
但是假如我们导入了一整本书,再用 SuperMemo 的自动安排可能就不太合适了,需要我们自己动手做一些处理。
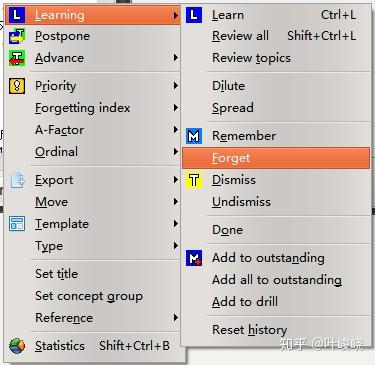
首先,在知识树中右键点击导入文章的父节点,再点击 Process branch,对这个分支做批量处理。

点击 Process branch 后会有一个新菜单,点击 Learning > Forget,就可以将这个分支下的所有卡片设为新材料,不会自动加入待办队列进行复习。
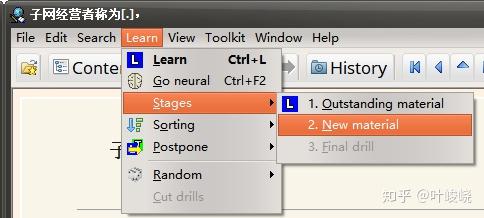
那么,我们该如何学习这些被 Forget 的材料呢?点击 Learn》Stages》New material 即可切换学习新材料的队列:
总结
导入一时爽,复习火葬场。希望大家先导入少量自己感兴趣的材料实践渐进阅读,找到自己的节奏,再考虑导入大量材料。
毕竟,当有大量材料需要渐进阅读时,调整优先级就成为一个很重要的渐进阅读技能了。
希望大家多多实践,渐进学习。
有关材料导入和样式处理的教程就告一段落了,之后会详细介绍:
- 阅读文章中做摘抄的几种情况
- 改写原文应当注意的几个原则
- 拆分时如何保持知识间的联系
- 怎样挖空可以做到最好的效果
这些才是渐进阅读的核心,希望大家在实践过程中能够体会到它们的重要性,这远远比样式重要得多。
参考
1. 完美主义者的增量学习 https://www.yuque.com/supermemo/wiki/il_for_perfectionists2. 导入文章 https://www.yuque.com/supermemo/wiki/hints_and_tips#gj2PV