
问题描述
在不考虑人力物力资源限制的情况下,最理想的情况。
我理想中的教育是一切都围绕着我想要做的事,帮助我学习所需的知识。
理想中的教育应该让我在真正有意义的情境中学习,而不是完成人为设计的任务,达到别人定制的标准。
理想中的教育应该让我融入实际项目或问题中,通过亲身实践和探索,理解和应用所学知识。
理想中的教育应该提供足够的认知支持、指导和练习,帮助我理解和掌握复杂知识,同时保持足够的自由度和真实性,使我能够探索和发现,保持兴趣和内在动力。
理想中的教育应该利用认知科学的原理,通过间隔重复和动态练习,帮助我巩固记忆和深度理解所学内容,确保知识迁移和应用的高效性和持久性。
理想中的教育应该鼓励与实践社区的互动和联系,建立有意义的导师关系和实践机会,使我感觉到与实际应用的紧密关联。
下面这篇译文描述了 Andy Matuschak 他心目中理想的教育。
以下内容摘自 @Thoughts Memo 汉化组的译文《我们如何学习?》
视角:你理想的学习环境
谈论学习技术时,人们常常只关注技术本身。但我想先问:你希望你自己的学习体验是怎样的? 假设现在就给你变出一个完美的学习环境,你希望它是怎样的?
开始思考这个问题的一种方式是问自己:你人生中收获最多、成长最快的时期是怎样的?
我发现,这个问题的回答中有两种常见的模式:首先,人们会提到一段他们学到了很多东西的时期,但学习本身并不是重点。相反,他们沉浸在一个对自己真正有意义的情境中,比如创业、研究项目、艺术冲动,或者只是强烈的好奇心。他们全身心投入,亲力亲为,并在过程中学到了一切重要的东西。然后,在这些故事中,学习确实奏效了。人们从中脱胎换骨,变得更有能力,充满了洞察力和理解力,而这些收获多年后依然伴随着他们。
这些故事之所以如此生动,是因为学习通常并非如此。人们往往怀着一种淡淡的惆怅,讲述那些发生在多年甚至几十年前的经历。学习很少能够完全融入真正的追求中。通常,当我们试图「全身心投入」时,往往会碰壁,或者感到自己只是在模仿他人,却没有真正的理解。
为什么我们不能每次都「全身心投入」呢?
相反,我们常常觉得必须先暂时放下目标,去做一些功课——好好学习。更糟糕的是,学习往往并不奏效!我们上了课,读了书……但当我们试图将这些知识付诸实践时,发现它们很脆弱,无法融会贯通。然后我们常常发现,到实际应用它们时,早已忘了大半。
为什么学习常常没有真正奏效呢?

这些问题触及了教育学家和学习科学家之间一个由来已久的争论——内隐学习(implicit learning,又称为发现式学习、探究式学习或情境学习)和引导式学习(guided learning,通常由认知心理学家主张)之间的冲突。内隐学习的支持者主张,我们应该优先考虑探索发现、动机、真实参与以及融入实践社区。而认知心理学家则认为,我们确实需要关注认知结构、长期记忆、程序流畅性,并适当搭建脚手架以减轻认知负荷。
在我看来,这两种视角都有其道理。但它们互相否定对方的立场,结果两败俱伤。内隐学习重视意义和情感,却忽视了认知上的决定性限制——这往往是使「学习真正奏效」的关键。而引导式学习的倡导者专注于让学习奏效,有时确实成功了,但通常是以牺牲那些让我们感到充实的快速成长时期的沉浸感为代价。
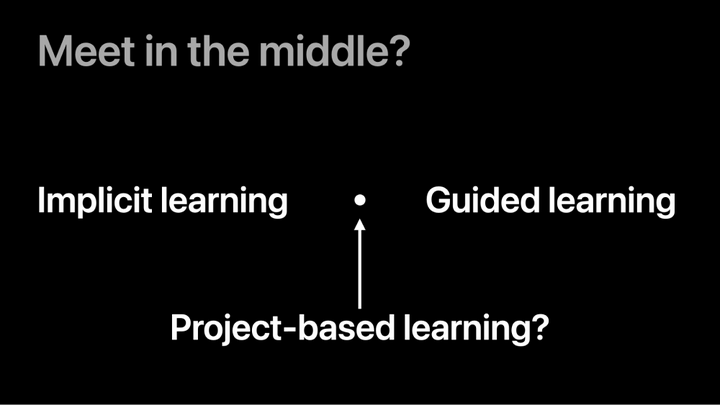
一个显而易见的方法是尝试折衷。项目式学习(project-based learning)就是一个很好的例子。通过设计一系列带有脚手架的项目,我们希望能获得内隐学习的一些好处——真实性、动机和知识迁移——同时也能保持传统课程中典型的教学控制和认知意识。但结果往往是两头不讨好——既没有激发兴趣和意义,也缺乏足够的指导、解释和认知支持。
在大学期间,我对 3D 游戏编程很感兴趣,所以选了一门关于计算机图形学的项目式课程。问题是,那些项目并不是我真正想做的。几周后,我发现自己在实现一个光线行进着色器,以提高凹凸贴图的效率。更糟糕的是,因为这门课试图认真对待项目式学习,没有长篇的教科书可以阅读,也没有习题集可做。我只是把给我的数学公式翻译成代码。最终,我做了一个自己不感兴趣的项目,实现了自己不理解的数学公式。
相反,我建议:我们应该认真对待这两种视角,并找到融合两者的方法。你确实希望将做你想做的事作为主要活动。但认知心理学的现实表明,在许多情况下,你确实需要明确的指导、脚手架、练习和记忆支持。
当学习内容的复杂性较低,与你已有的知识相匹配时,沉浸式学习自然有效。这时,自然的参与会不断强化重要内容,从而建立流畅性。但当这些条件不满足时——这大多数时候都是如此——你就需要一些支持。
你希望全身心投入,并且希望学习真正奏效。为了实现这一点,我们需要在你的真实项目中融入必要的指导和支持,借鉴认知心理学的最佳理念。而对于那些需要更专注的外显学习(explicit learning)体验的内容,你希望这些体验完全服务于你的实际目标。
多年来,我一直在思考如何融合这两种视角,坦白说,我大多时候都很困惑!不过,最近我开始关注人工智能(AI)。我知道,提到 AI,大家可能会翻白眼。每次在学习技术中提到 AI,我也会翻白眼。但我得承认,AI 的可能性让我终于在这个问题上有了一些进展。今天我想分享一些初步的想法。
演示
1. 可驾驭的沉浸式学习
我们将通过一个分为六节的故事来探讨这种可能的融合。

让我们先认识一下 Sam。Sam 在大学时学的是计算机科学,现在在一家大型科技公司担任软件工程师。但 Sam 对日常工作感到有些无聊。然而,并不是所有事情都那么无趣。每次看到关于脑机接口新成果的推文时,Sam 都会被深深吸引。这些项目看起来有趣得多。Sam 会查阅相关论文,寻找参与的途径,但总是碰壁——太多陌生的主题同时出现。
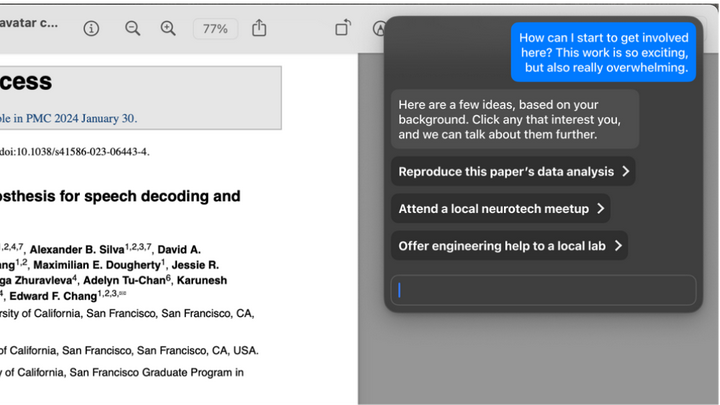
如果 Sam 能请求帮助,找到一种有意义的参与方式,那会怎样呢?在 Sam 的许可下,我们的 AI——假设它是一个本地 AI——可以收集大量关于 Sam 的背景信息。从 Sam 硬盘上的旧文件中,AI 知道了 Sam 的大学课程。通过工作项目,AI 能洞察到 Sam 当前的技能水平。通过浏览历史,AI 对 Sam 的兴趣有所了解。
Sam 对复现论文中的数据分析很感兴趣,因为这似乎正好发挥了他的特长。他注意到,作者用了一个自定义的 Python 软件包进行分析,但该代码并未公开。这引起了 Sam 的兴趣:Sam 之前开发过开源工具。或许 Sam 可以通过构建这个信号处理管道的开源版本做出贡献。
2. 在行动中指导
于是,Sam 开始全身心投入。他找到了一个开源的数据集,并迈出了开始工作的第一步。像 Copilot 这样的工具能帮助 Sam 起步,但要跟随这些信号处理步骤,Sam 真正需要的是一种不仅能够理解代码,还能了解论文内容,并知道 Sam 正在尝试做什么的 Copilot。
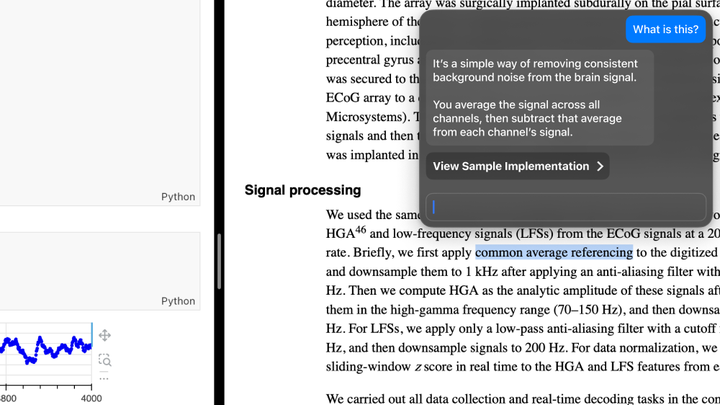
这个 AI 系统不仅限于自己的聊天框,或某个应用的侧边栏。它能看到多个应用中的操作,并在多个应用中提出行动建议。Sam 可以点击按钮,查看潜在实现的变更集,然后继续对话,顺畅地切换到代码编辑器的上下文中。
比如,这个「axis=1」参数是什么意思?解释需要结合代码编辑器中的上下文、正在实现的论文内容,以及数据集附带的文档。AI 会高亮基于特定信息作出的假设,并将其转化为链接。
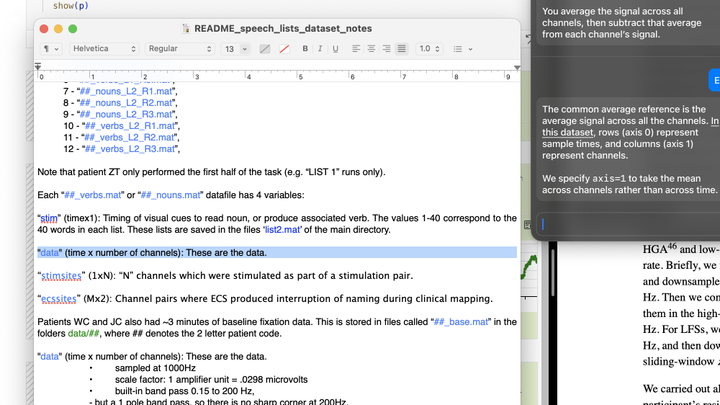
Sam 点击了「在这个数据集中」的链接,我们的 AI 随即打开 README 文件并跳转到相关段落。
这一切都是为了实现我们的核心目标——让 Sam 尽可能沉浸在他实际要做的事情中,同时获得他理解自己正在做的事情所需的支持。
3. 合成动态媒介
这种支持不仅限于文本。

接下来,Sam 需要实现一个降采样阶段。这次,指导包括合成的动态媒介,让 Sam 通过带脚手架的沉浸来理解降采样的作用。
Sam 不需要阅读抽象的解释并尝试想象它对不同信号的影响。相反,他可以通过尝试不同的采样率,动态媒介的实时反馈将帮助他内化对不同信号的影响。通过操作动态媒介,Sam 注意到一些峰值在信号降采样时丢失了。
这些动态媒体不仅限于聊天框。它们使用的是 Sam 在笔记本中相同输入数据和库。在任何时候,Sam 都可以直接「查看源代码」来调整这个图形,或者在自己的笔记本中使用其中的一些代码。
4. 情境化学习
现在,Sam 继续深入学习带通滤波器。但是,这些通过简短聊天得到的宏观解释感觉完全不够充分。什么是频域?什么是奈奎斯特率(Nyquist rate)?Sam 可以复制一些 AI 生成的代码,但他完全不明白其中的原理。显然,聊天界面并不是进行长篇概念解释的理想媒介。是时候进行更深入的学习了。

AI 知道 Sam 的背景和目标,所以建议他参考一本注重实践的本科教材。更重要的是,AI 安慰 Sam,现在不必马上读完这本上千页的书。AI 根据 Sam 的目标,推荐了一些易于理解的路径,Sam 可以根据自己对滤波器理解的深度选择不同的学习路径。AI 还在书的目录中为 Sam 制作了一张个性化的学习地图。
比如,如果 Sam 只是想了解这些滤波器的作用和原因,有一条 25 页的学习路径。如果他想了解数学背景——这些滤波器的工作原理,有一条更深入的路径。如果他想自己实现这些滤波器,还有一条更深入的路径。Sam 可以根据自己的需求选择学习路线。

当 Sam 深入学习这本书时,他会发现每个章节的开头和内容中都有 AI 的注释,这些注释将材料与 Sam 的背景、项目和目标结合起来。例如,「这一章节将帮助你理解如何从频谱的角度看待信号。这正是低通滤波器所处理的内容。」Sam 虽然暂时离开了他的项目,进入了一个更传统的学习环境,但这并不意味着他的学习体验会与真正的实践脱节。
顺便说一下,我听过一些技术专家建议,我们应该用 AI 为每个人定制整本书。但我认为,共享的经典文献有着巨大的价值。在任何一个领域,都有大家共同参考的关键文本,它们构成了文化的共同基础。我认为,我们可以通过在这些文本上添加个性化的背景注释来保留这些经典。
在我理想中的未来,共享的经典文献应该是动态媒介,而不是数字化的纸质书。然而,直到所有的经典作品被重写为动态媒介之前,作为过渡措施,我们至少可以挥手想象,AI 可以合成像这些图表的动态媒介版本。
现在,Sam 在阅读这本书时,可以继续通过提问与文本互动,AI 的回答将始终与他的项目相关。
当 Sam 高亮文本或对某些特别重要或令人惊讶的细节发表评论时,这些注释不会被困在 PDF 中。它们将融入未来的讨论和实践中,稍后我们会看到这一点。

除了 Sam 向 AI 提问外,AI 也可以提出一些问题让 Sam 思考——同样基于他的项目——以促进对材料更深入的理解。
就像 AI 引导 Sam 找到这本厚达千页的书中的正确章节一样,它也可以指出哪些练习对 Sam 最有价值,考虑到他的背景和目标。AI 还能将这些练习与 Sam 的目标联系起来,这样做这些练习的过程就像是他真正实践的一部分。即使练习仍然感觉有些脱离情境,Sam 至少可以更有信心地认为,这些工作将帮助他实现他想要做的事情。
插曲:练习与记忆
Sam 结束了一天的工作,项目上有了些进展,对不少主题也有了新的理解。但这些知识还不够牢固,Sam 对这些内容的掌握还很生疏。如果他试图认真使用这些材料,可能会感觉底气不足。而且,很可能会忘掉刚学到的大部分内容。
我想谈谈记忆这个话题。值得一问的是:为什么我们有时候能记住概念性的内容,有时候却记不住?我们常常上课、读书,甚至查资料,但没多久就几乎忘得一干二净。但有些东西却能记得特别牢。这是为什么?
有些情况比较简单。如果你在熟悉的领域学习新知识,每个新事实都会和已有的知识联系起来。这会提供更多记忆的线索和强化的机会。如果你每天都需要用到这些知识,你会发现记忆很快就变得可靠起来。

像 Sam 正在学习的这些概念性内容,通常不会每天都得到强化。但有时候,环境会巧妙地给这些记忆提供所需的强化。比如,你白天读到一个主题,晚上和同事聊天时又谈到了这个主题。你需要回忆起所学的内容,这个过程会强化记忆。然后,可能两天后,你在项目中再次需要用到这些知识。每次这样强化记忆,你遗忘的速度就会变慢。这样一来,可能一周过去了,你还记得。然后是几周,几个月,依此类推。只要在适当的时间间隔内进行几次回忆,你就能将这些知识记住几个月甚至几年。
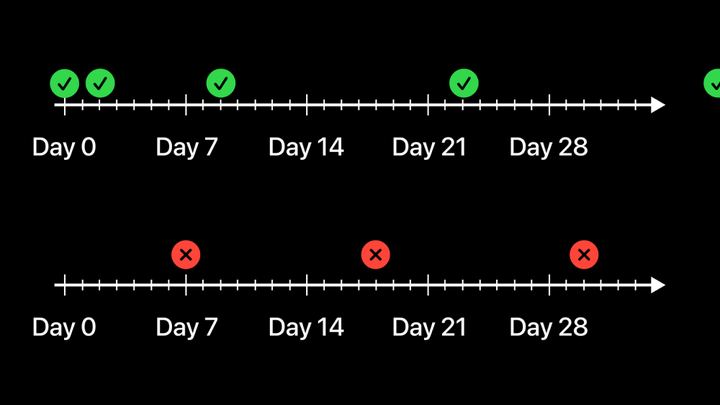
相反,有时候你学到的东西,直到下周才再次用到。这时你试图回忆,但可能已经忘了,所以不得不重新查阅。这对记忆的强化作用不大。如果很长时间内都不再用到,下次可能还是记不住,又要重新查阅的。如此反复。这里的关键启示是,你可以为自己安排一个合适的时间表。
有些课程确实会这样做,每次作业都会有意识地复习之前学过的知识。但大多数沉浸式学习,以及大部分学习方式,通常不会这么安排,所以你经常会忘掉很多内容。如果这种强化能融入学习过程,会怎么样呢?
我的合作者 Michael Nielsen 和我创建了一本量子计算入门书《量子国度》,就是为了探索这个想法。这本书可以在网上免费阅读。如果你访问 quantum.country,你会看到乍一看像一本普通的书。
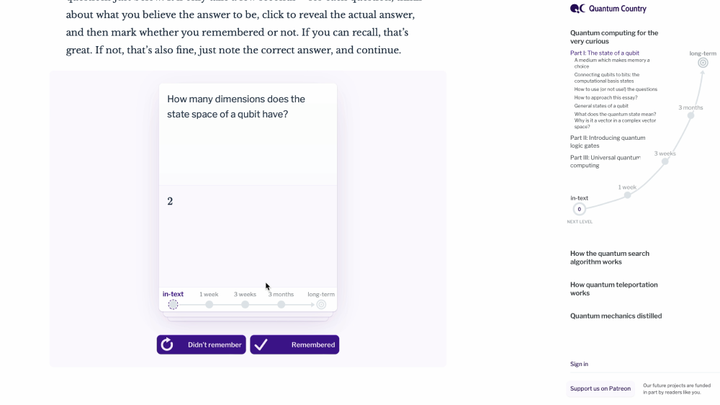
阅读几分钟后,文章会被一些小测验打断。这些问题设计得很简单,每个只需几秒钟:在心里想出答案,然后标记自己是否答对了。到目前为止,这些看起来像是简单的抽认卡。但正如我们讨论过的,即使你现在能回答这些问题,并不意味着几周甚至几天后你还能记住。
注意到每个问题底部的这些标记了吗?这些标记代表时间间隔。你在阅读文本时练习这些问题,然后一周后,你会收到一封邮件,说:「嘿,你可能已经开始忘记你读过的一些内容了。要不要花五分钟快速复习一下?」每次你成功回答后,间隔时间都会增加——先是几周,然后几个月,依此类推。如果你开始遗忘,间隔时间就会缩短,以便提供更多强化。
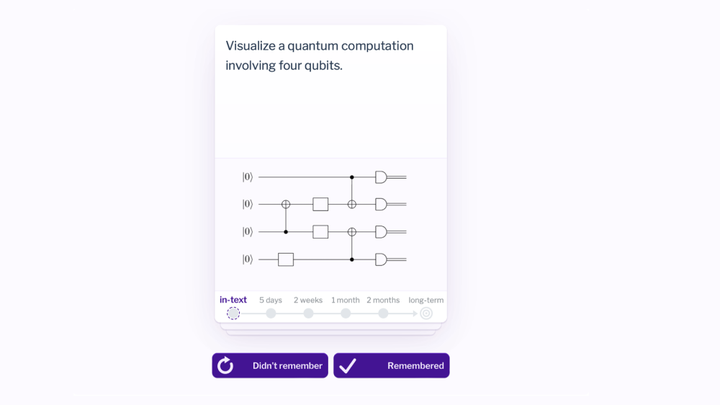
你可能以前见过类似的系统。语言学习者和医学生经常使用一种叫做间隔重复记忆系统的工具来记忆单词和基础知识。但同样的认知机制也适用于更复杂的概念性知识。基于这个原理,书的第一章里分布了 112 个这样的问题。
《量子国度》是一种新型媒介——一种助记媒介——它将间隔重复记忆系统与解释性文本结合起来,使人们更容易可靠地吸收复杂的内容。
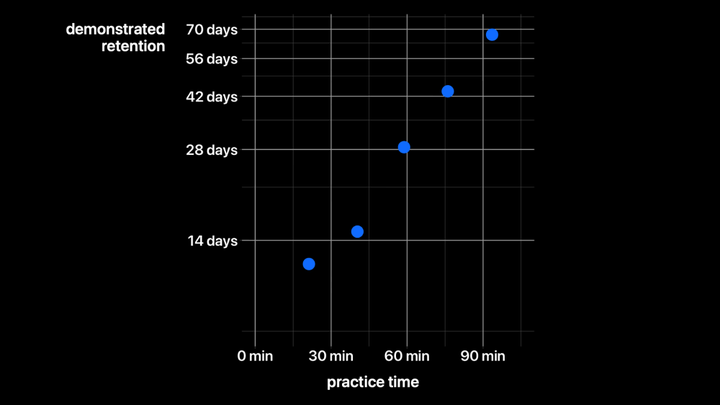
我们现在有数百万条练习数据,可以开始看到它的效果。这张图展示了练习所花的时间(x 轴)与读者的展示记忆保持(y 轴)之间的关系。展示记忆保持指的是读者在不练习的情况下,能正确回答至少 90% 问题的时间长度。这五个点代表了中位用户在第一章中的前五次重复练习。注意,y 轴是对数刻度,所以我们看到的是一个漂亮的指数增长。每次额外的重复练习——持续的额外投入——会带来越来越多的产出——也就是展示记忆保持的提高。
总共花大约一个半小时的练习时间,中位读者在两个月没有练习后,仍能正确回答第一章中的一百多个详细问题。现在,第一章大多数读者初次阅读需要大约四个小时,所以这张图表明,额外不到 50% 的时间投入可以带来几个月甚至几年的详细记忆保持。
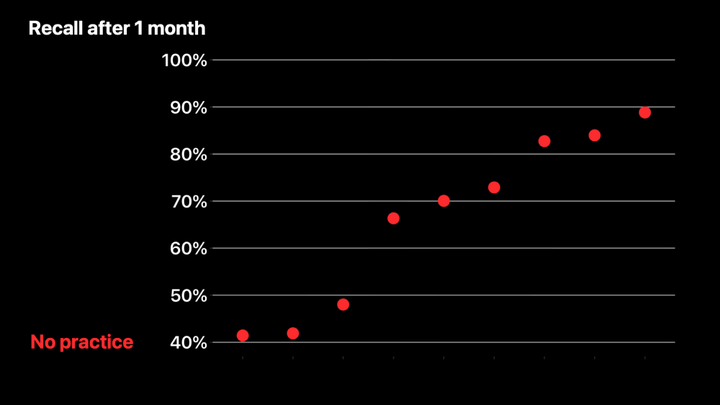
探索反事实也很有趣:如果没有额外的强化,人们会忘记多少?作为实验,我们从一些读者的第一章中移除了九个问题,然后一个月后在他们的练习中偷偷重新加入这些问题。这个图表展示了结果。
这九个点代表那九个问题。y 轴显示的是一个月后,读者在没有任何帮助的情况下,能够正确回答该问题的百分比。你可以看到,有些问题比其他问题更难。一个月后,大多数读者答错了最左边最难的三个问题,大约 30% 的读者答错了中间三个问题,而大约 15% 的读者答错了最容易的三个问题。
另一组用户在阅读文章时进行了练习,就像我们刚才在视频中看到的那样。对于他们忘记的问题,第二天还有一次额外的练习。然后这些问题消失了一个月,再进行测试。这些读者表现明显更好,尽管仍有一部分人答错了一些问题。
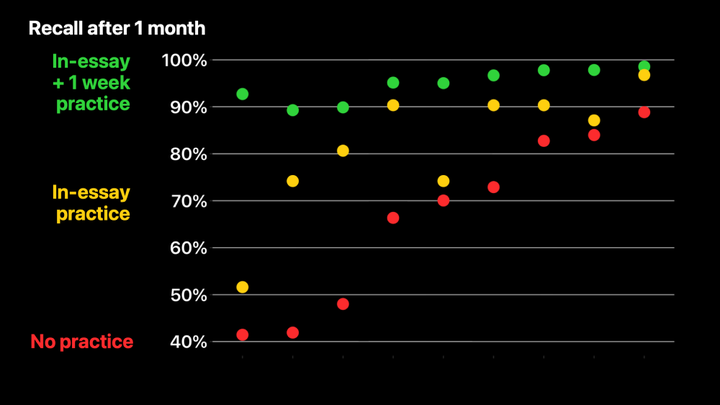
这里还有最后一组,和前一组类似,但他们在完成阅读一周后额外进行了一轮练习。然后我们在一个月的标记处再次测试了他们,这就是你现在看到的结果。每个问题平均需要六秒钟回答,所以这九个问题的额外练习时间总共不到一分钟。但现在,对于所有这些问题,至少 90% 的读者能够正确回答。
当然,有些读者比其他人更轻松。左边的这张图表关注的是底部四分位数的用户——那些在第一次阅读文章时答错最多问题的读者。注意,我不得不将 y 轴向下延长。我们可以看到,如果没有进行任何练习,他们大多数人会忘记三分之二的这些保留问题。仅靠文章中的练习,仍有大约一半的人忘记了大约一半的问题。但通过额外的一轮练习,即使是底部四分位数的读者表现也相当不错。
像《量子国度》这样的系统不仅对量子计算有用。在我的个人实践中,我积累了成千上万的问题。我为科学论文、对话、讲座、难忘的饭菜写下问题。所有这些都让我的日常生活更加充实,因为我知道,只要我投入注意力,我就能长久地内化这些知识。
这个系统的核心是日常仪式的概念,一个练习的载体。就像冥想和锻炼一样,我每天花大约十分钟使用我的记忆系统。因为这些指数型调度非常高效,这十分钟足以维持我对数千个问题的记忆,并允许我每天增加大约四十个新问题。
但我想提一下这些记忆系统存在的一些问题。
其一是模式匹配:一旦一个问题出现几次,我可能会识别出问题的文本,而没有真正思考它。这会产生一种令人不快的鹦鹉学舌的感觉,但我怀疑它经常让我的记忆变得脆弱:我会记住答案,但只有在练习时完全按照提示的情况下才会记住。我希望问题能有更多的变化。
同样,问题必然在某种程度上是抽象的。当我面对该领域的一个实际问题时,我不总是能识别出我应该使用哪些知识,或者如何将其适应到情况中。认知科学家会说,我需要习得图式(schemas)。
除非我干预,否则问题会在几年内保持不变。它们在维持记忆——但理想情况下,它们应该推动进一步的加工——随着时间的推移增加深度。
最后,回到这次演讲的主题:记忆系统通常与我真正的实践脱节太多。比如说,我正在为一个创意项目学习信号处理的一个主题。除非我很细心,否则那些问题可能不会与我的项目感觉很相关——它们会感觉像是信号处理的普通教材习题。
演示
5. 动态练习
现在让我们回到 Sam,看看能否应用一些关于练习和记忆的想法。Sam 已经学习了那些信号处理的材料,因此他希望确保真正记住这些知识。
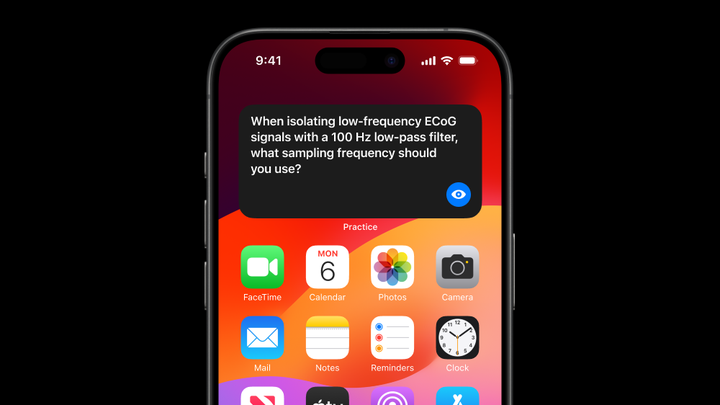
他安装了一个屏幕小组件,这个小组件会随机展示练习卡片,这些卡片来自于他的高亮标记、提问和 AI 能访问的其他活动。Sam 可以在排队或乘车时翻阅这些问题。注意,这些问题不是泛泛的信号处理问题,而是基于 Sam 的脑机接口项目的具体细节,因此理想情况下,练习会感觉更连贯,更接近他真正要做的事情。
这些合成的卡片每次都会有所不同,这样 Sam 可以从不同角度练习同一个概念。随着 Sam 对材料的熟悉程度增加,卡片会变得更深入、更复杂。还要注意,这些问题并不抽象,而是与如何应用 Sam 学到的知识息息相关,并以适合一口吃下的形式呈现。
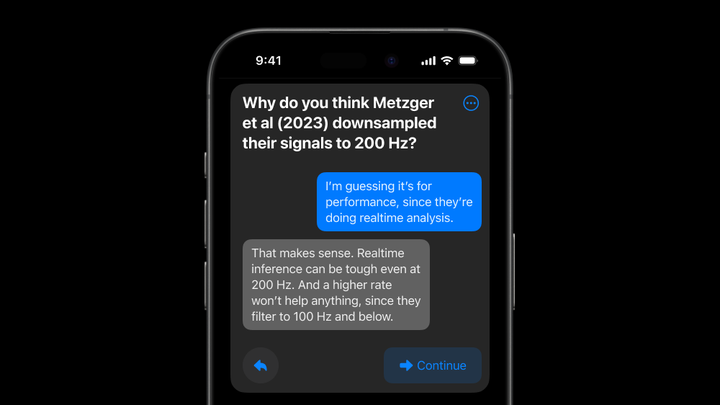
小组件还可以包含开放式讨论题。在这里,Sam 会得到详细的反馈——一个额外的细节来考虑他的答案。
当问题以这种方式合成时,重要的是 Sam 可以通过反馈来引导这些问题。未来的问题在合成时将根据反馈进行调整。
到目前为止,我们看到的是 Sam 可以在外出时回答的一口大小的问题,但如果他腾出时间进行更长时间的专门练习,我们可以推荐更有分量的任务,比如这个。更重要的是,我们可以将这些任务从虚拟的练习环境转移到 Sam 的实际环境中——Jupyter 笔记本。注意,这些任务仍然是围绕 Sam 的具体目标,而不是一些泛泛的信号处理问题。
6. 社交联系
现在,Sam 加入这个项目并非仅仅作为「学习练习」,而是作为一种开始合法参与的方式。在发挥现有优势的同时,开始在脑机接口方向工作。
正如我们的 AI 能帮助 Sam 找到进入这一领域的可行途径,它也能促进与实践社区的联系——这里推荐了一个当地的神经科技聚会。于是,Sam 参加了神经科技活动,结识了一位当地的科学家,并约定了咖啡会面。在获得许可后,Sam 记录了这次会面,预感到这些笔记日后可能会有用。
当然,在这场对话中,Sam 经历了许多惊喜和好奇的时刻。我们的 AI 能够察觉这些时刻,并帮助 Sam 消化它们。这里,那个洞察转化为一张反思实践的卡片。
讨论
设计原则
Sam 的故事中贯穿了四大设计原则。现在,我想回顾这些原则,并针对每一条,指出我认为 AI 能提供的帮助。
首先,我们将引导式学习融入真实情境,而非将其视为一项独立活动。我们能做到这一点,是因为设想了一种能在 Sam 电脑上跨应用程序感知和行动的 AI。正如最后的音频转录所示,这种能力甚至可以延伸到电脑之外的活动。这种 AI 之所以能提供恰当的指导,部分原因在于——在获得许可并在本地运行的情况下——它能从所有曾出现在 Sam 屏幕上的文本、所有他在电脑上的行动中学习。它能合成动态媒体支架,使 Sam 能在指导下通过实践学习。
接着,当有必要进行外显学习活动时,我们将其融入真实情境。AI 将 Sam 的所有阅读和实践活动与他的真实目标相结合。它帮助 Sam 将学习活动与他的兴趣深度相匹配。它利用 Sam 实践中的重要时刻,比如咖啡会面结束时的洞察,或项目实施过程中提出的问题,并将这些时刻融入学习活动中。
除了连接这两个领域,我们还能加强它们各自的力量。我们的 AI 为 Sam 提供了「全身心投入」新兴趣的可行方法,并帮助 Sam 建立与实践社区的联系。
最后,在外显学习活动中,我们要确保学习真正奏效。我们的 AI 创造了一个动态的学习载体,它随时间变化,以确保知识能顺利迁移到实际情境中。而且,它不仅仅维持记忆,还能随着时间的推移加深理解。
为聊天机器人导师喝彩两声
当前关于 AI 与教育的讨论大多围绕聊天机器人导师这一视角展开。
我认为,这一视角正确地捕捉到了语言模型的一个真正美妙之处:它们擅长回答长尾问题……前提是用户能够清晰地表述问题。如果用户试图完成一项常规任务,聊天机器人导师通常能诊断出问题所在,并找到方法让用户摆脱困境。这确实很棒。
然而,当我以我们一直在探讨的更宽广的视角审视他人对聊天机器人导师的愿景时——显然,他们忽略了许多我所期望的要素。我认为,这些愿景往往未能认真对待真正的导师能做的巨大贡献。很大程度上,我认为这是因为这些愿景的提出者通常在思考教育(他们想对他人做的事情)而非学习(他们自己想要的事情)。
现在,这个世界上一个可悲的事实是,博士后和研究生的薪酬极低,因此,聘请一位我关心的技术领域的专家导师,其费用竟然出乎意料地可承受。
但若我聘请一位真人导师,以成人身份学习信号处理,我会告诉他们我对脑机接口的兴趣,并期望他们的每次交流都围绕这一目标展开。我的目标并非单纯的「学习信号处理」,而是「参与脑机接口的创造」。聊天机器人导师并不关心我的实际目标;它们有一套认为我应该知道或能够做到的事情,直到我说出正确的话前,它们认为我有缺陷。
若我聘请真人导师,我可能会请求他们在我尝试实际应用这些知识时坐在我身旁。他们能观察到我的一切操作,理解我所指之处。若情况适宜,我可以稍作让位,让他们短暂主导。相比之下,典型的聊天机器人导师概念如同生活在一个无窗的盒子中,仅能看见门缝下递进的零星纸片上的信息,对外界毫无影响能力。我的目标是深入其中,全身心投入,开始实践。然而,这些聊天机器人导师无法与我一同置身于真正的行动现场。因此,与它们的互动产生了距离,将我从沉浸状态中拉扯出来。
若我聘请真人导师,我们将建立起一种关系。每节课后,他们都会更了解我——我的兴趣、我的优势、我的困惑。通常设想的聊天机器人导师则是交易性的,健忘的。尽管随着上下文窗口的延长,这一点可以得到改善。但这种关系对我情感投入同样至关重要。如果我将与导师的对话视为一种边缘性参与我所期望加入的社群的方式——一种在学科内的新手与导师的互动——那么辅导将成为实践的一部分。但如果我与导师的互动是交易性的,那么这往往会使我的辅导课程感觉像是「学习时间」,与实践相隔离。
最后,人们常提及亚里士多德曾是亚历山大大帝的导师。然而,拥有亚里士多德作为导师的最大价值并非在于「纠正误解」,而在于他展示了真诚、全身心投入智力的成年人的实践与价值观。他示范了思考问题的方式及其原因,他在学科中的品味。我们珍视的高速成长期改变了我们看待世界的方式,重塑了我们的身份。
在我之前的演示中,我展示了一个聊天机器人,但它并不像我看到的许多「聊天机器人导师」那样运作。它将所有行动聚焦于用户的兴趣,而非自带议程。它并未局限于狭小的文本框内——它能在真实使用的情境中观察并采取行动,能通过动态媒体进行交流。它拥有深刻的记忆,汲取了你曾写过或见过的所有内容。
因此,在某种程度上,我所展示的系统更像一位真人导师。但在我理想的世界里,我并不想要一个导师;我渴望合法地参与某个新领域,并尽可能通过与实际从业者的互动来学习所需知识。
我认为增强学习系统的角色是帮助我实现创意兴趣,理想情况下,让我尽可能直接全身心投入并开始实践。这往往意味着搭建与实践社区的联系和互动的桥梁。
关于伦理的说明
本系列 Design@Large 的一个主题是 AI 伦理及其可能产生的巨大社会影响。请允许我说:我对这些影响深感忧虑,尤其是在普遍情况下。我担心独裁者巩固权力、降低生物武器门槛、引发经济混乱。在伦理上,我无法安心研究更强大的前沿模型。
但在学习的较窄领域内,我最主要的道德关切是我们可能陷入一条悲哀而狭窄的道路。一种居高临下、权威主义的视角主导了未来学习的叙事。我将对此进行夸张描述以阐明观点:借助 AI,我们可以让所有这些有缺陷的孩子——那些不知道他们应该知道的东西的孩子——最终掌握这些知识!你知道的:个性化学习!AI 将使我们能精确识别孩子们的错误或无知之处,并修正他们。然后,我们可以将有益于他们的知识填满他们的头脑。
我认为著名的「思维自行车」比喻更好,因为它除了你带来的目标外没有其他议程。它只是让你能到达比步行更广阔的目标范围。而且,如果与朋友一同骑行,这段旅程也会变得有趣。自行车询问:你想去哪里?
当然,这个问题假设你的目的地已为人所熟知,并在某张地图上清晰标出。但那些最令人满足的高速成长经历往往围绕一个创意项目展开。你正试图前往一个无人涉足之地——抵达前沿,然后开始绘制通往未知的链接。服务于创造的学习。这是一种动态、充满情境的学习。它关乎的不仅仅是效率和正确性,更不仅仅是自行车上更快的齿轮。正是这种学习,让我感到几乎有一种道德上的迫切性去助力其诞生。
我是一名独立研究员,我的工作由我的 Patreon 社区众筹支持。如果你觉得这项研究有趣,你可以成为会员,帮助实现更多这样的研究。你将得到深入的月度文章,原型预览,以及研讨会和非会议等活动。
现在,我要表达一些感谢。这次演讲中的想法得益于多年来与 Alec Resnick、Bret Victor、Dan Meyer、Joe Edelman、May-Li Khoe 和 Michael Nielsen 的交流。还要感谢 Ben Reinhardt、Catherine Olsson、Elliott Jin、Laura Deming、Rob Ochshorn、Sara LaHue 和 Taylor Rogalski 在我准备演讲时的有益对话。我感谢这次演讲的主办方,UCSD 设计实验室的 Jim Hollan和 Haijun Xia。
特别感谢截至发布时的赞助级别支持者:Adam Marblestone、Adam Wiggins、Andrew Sutherland、Andy Schriner、Ben Springwater、Bert MuthalalyBoris Verbitsky、Calvin French-Owen、Dan Romero、David Wilkinson、fnnch、Greg Vardy、Heptabase、James Hill-Khurana、James Lindenbaum、Jesse Andrews、Kevin Lynagh、Kinnu、Lambda AI Hardware、Ludwig Petersson、Maksim Stepanenko、Matt Knox、Michael Slade、Mickey McManus、Mintter、Peter Hartree、Ross Boucher、Russel Simmons、Salem Al-Mansoori Sana Labs、Thomas Honeyman、Todor Markov、Tooz Wu、William Clausen、William Laitinen、Yaniv Tal。
在学术工作中引用该演讲请遵循以下格式:Matuschak, A. (2024, May 8). How might we learn?. UCSD Design@Large. https://andymatuschak.org/hmwl
Thoughts Memo 汉化组译制
感谢主要译者 DeepSeek-V2、校对 Jarrett Ye
原文:How Might We Learn? (andymatuschak.org)
Andy Matuschak · 2024 年 5 月 8 日