
问题描述
7月4日,界面新闻获悉,商汤发布首个“可控”人物视频生成大模型Vimi,该模型主要面向C端用户,支持聊天、唱歌、舞动等多种娱乐互动场景。商汤方面称,Vimi可生成长达1分钟的单镜头人物类视频,画面效果不会随着时间的变化而劣化或失真,Vimi基于商汤日日新大模型,通过一张任意风格的照片就能生成和目标动作一致的人物类视频,可通过已有人物视频、动画、声音、文字等多种元素进行驱动。
商汤发布首个“可控”人物视频生成大模型Vimi首个?我同学上个月就开源了他们的可控视频生成模型 ControlNeXt:
dvlab-research/ControlNeXt: Controllable video and image Generation, SVD, Animate Anyone, ControlNet, LoRA (github.com) https://www.zhihu.com/video/1793672973791678464
https://www.zhihu.com/video/1793672973791678464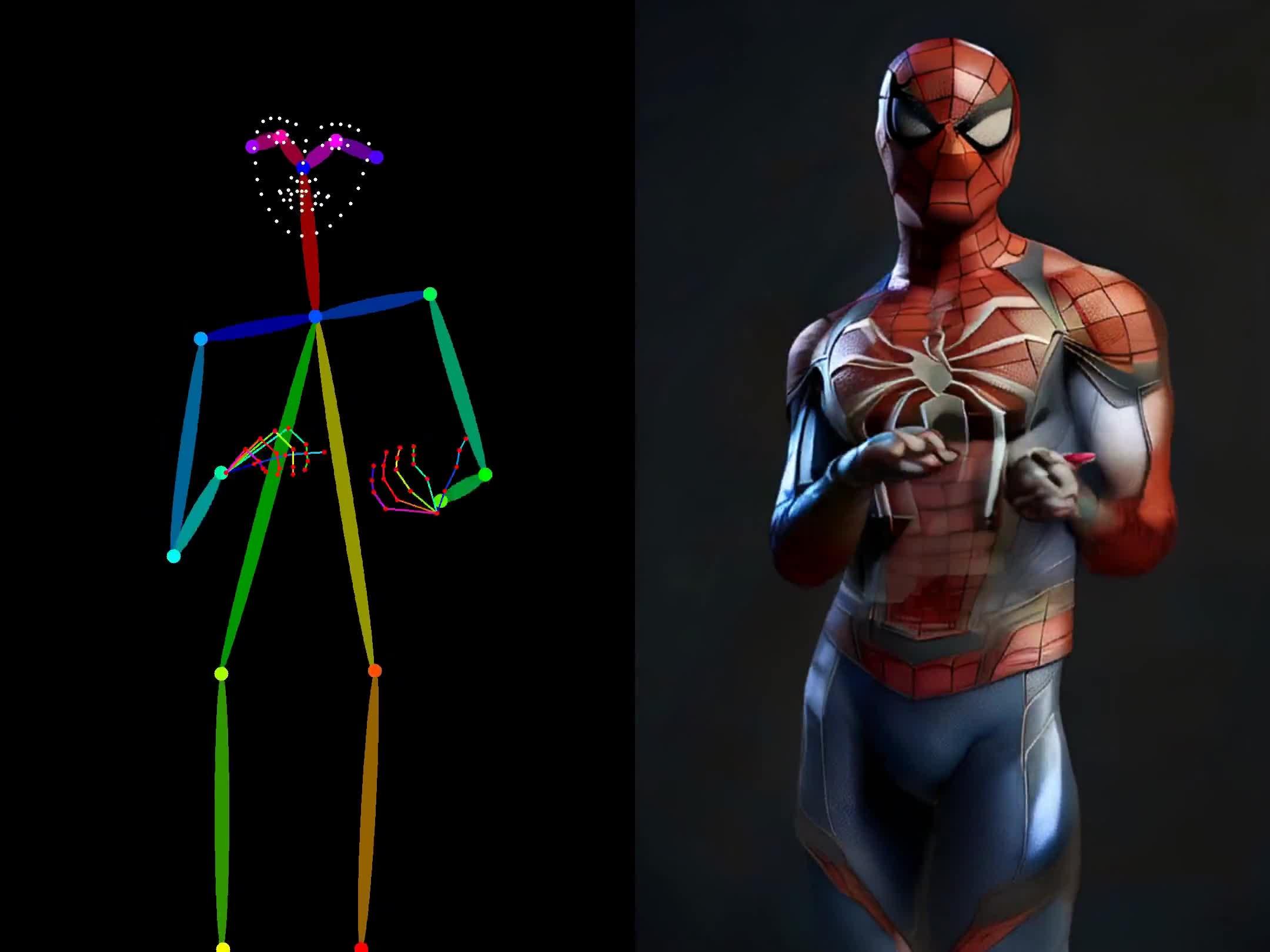 https://www.zhihu.com/video/1793673014547705859
https://www.zhihu.com/video/1793673014547705859这下又新闻学魅力时刻了。
具体的技术介绍还在待发表的论文中,敬请期待。