

本文使用 Zhihu On VSCode 创作并发布
这里是好久没有写文章的学委叶哥,由于是个懒人(迫真),不爱写自己都很少用到的功能模块的相关教程。
不过群友经常问图表相关的问题,想着写篇文章应该能解答不少疑惑,于是开始码字(在动车上闲着也是闲着
由于各类图表已经有官方的介绍,本文不会进行一一介绍,只会涉及一些我认为比较重要的图表。
另外,图表数据主要分为使用相关和算法相关,大家可能更关心使用相关的内容,算法相关的图表算是我的一点私货。
废话不多说,让我们开始吧!
使用相关
Shift + Alt + A 打开统计分析
每日重复次数
Use - Work done - Item Repetitions
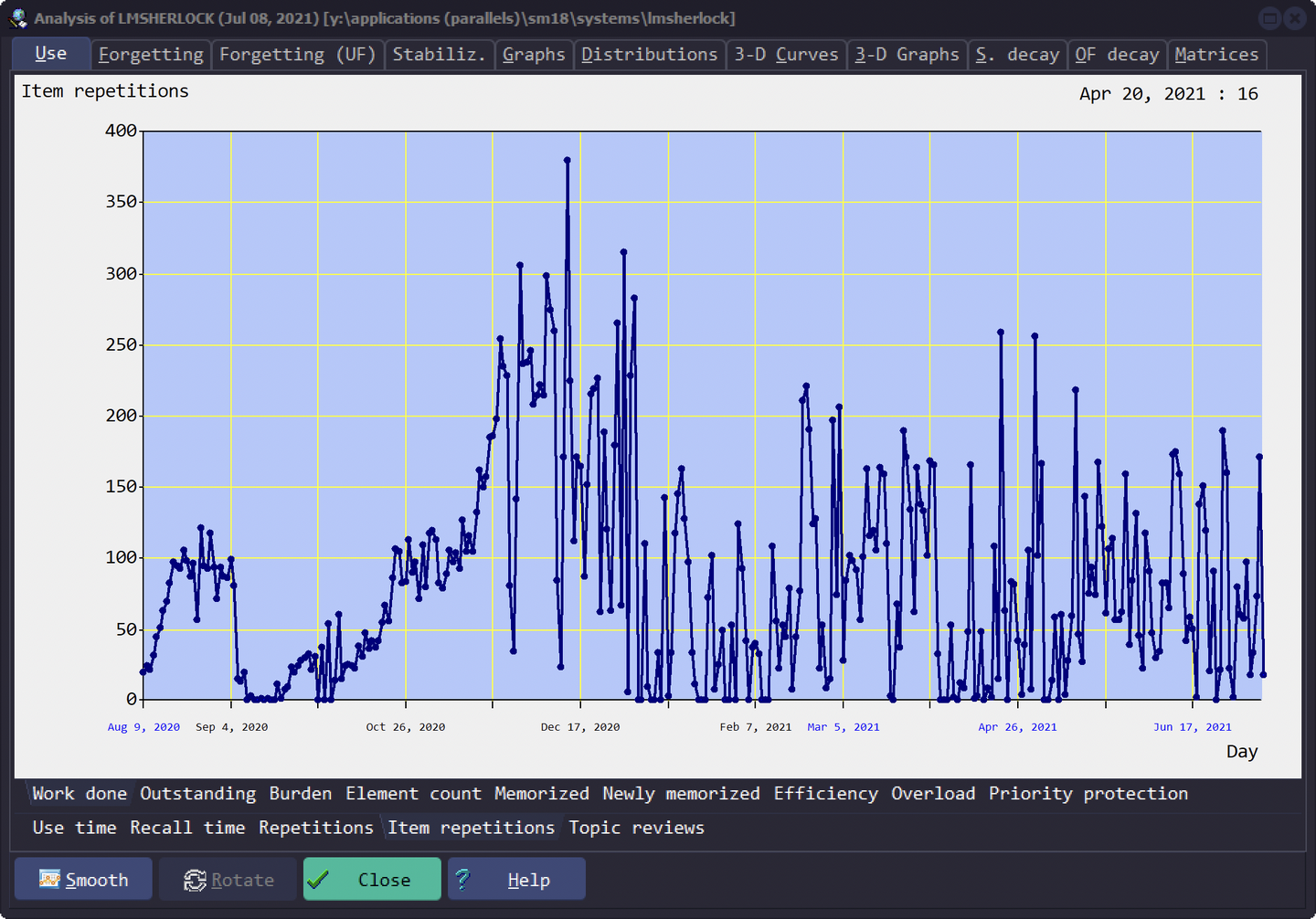
横轴是日期,纵轴是重复次数,不论是新学还是复习,只要进行一次评分,就会当做一次重复(包括在 Final Drill 中的重复)
点击 Smooth 可以平滑曲线,方便观察更大时间范围的趋势。
另外,Topic View 就是每日阅读的摘录卡片数量,Repetitions 就是 Item + Topic 的重复总和。Use Time 就是你花在这个 collection 上的时间,而 Recall time 是花在回忆答案的时间。
每日待办卡片数量
Use - Work done - Outstanding
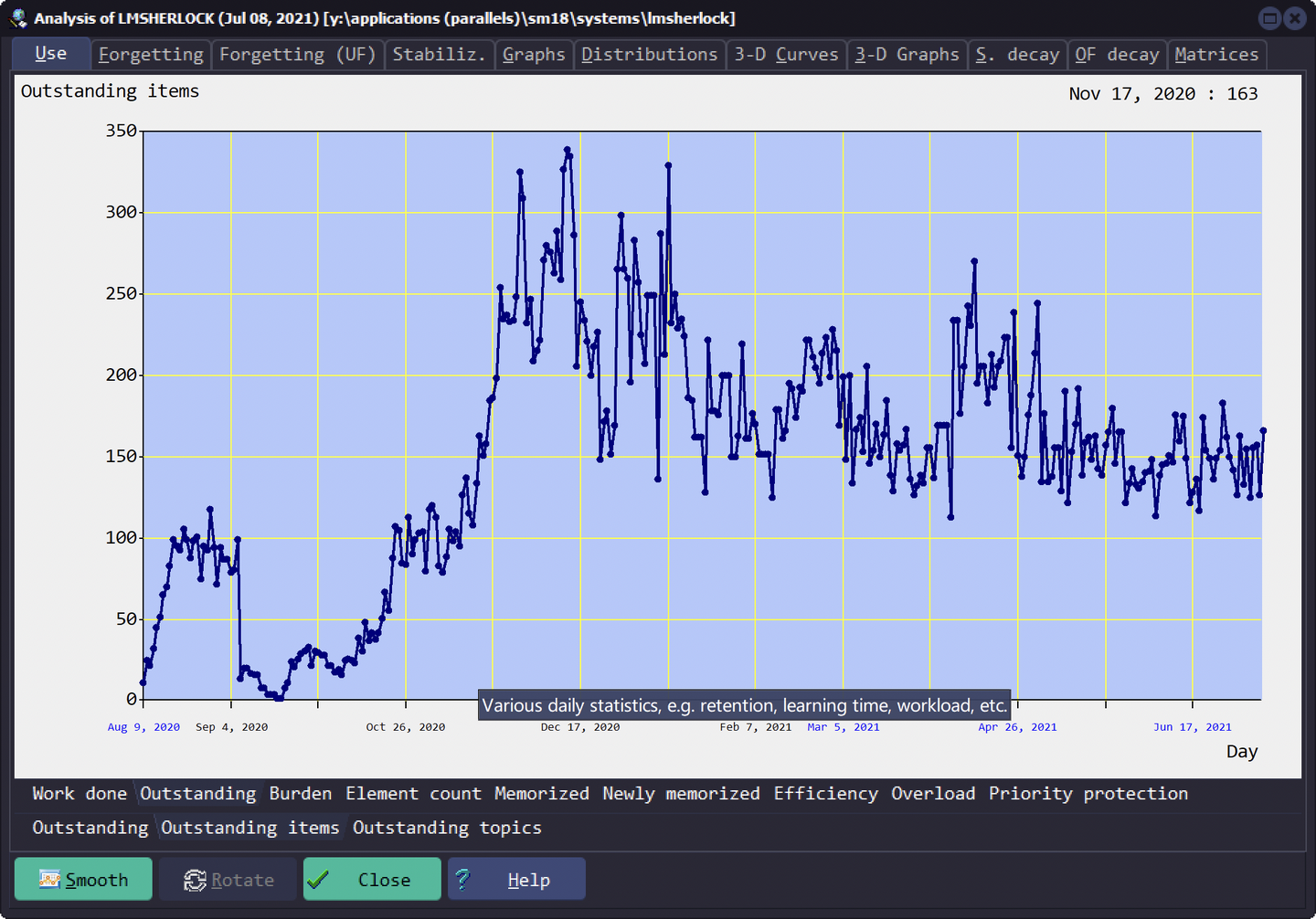
这个是 SuperMemo 算法每日安排的卡片数量,注意与前面的每日重复数量区分(一个是算法安排,一个是实际学习)。
Outstanding items 和 Outstanding topics 就是把问答卡片和摘录卡片分开统计。
卡片总数
Use - ELement count - Topic and tasks
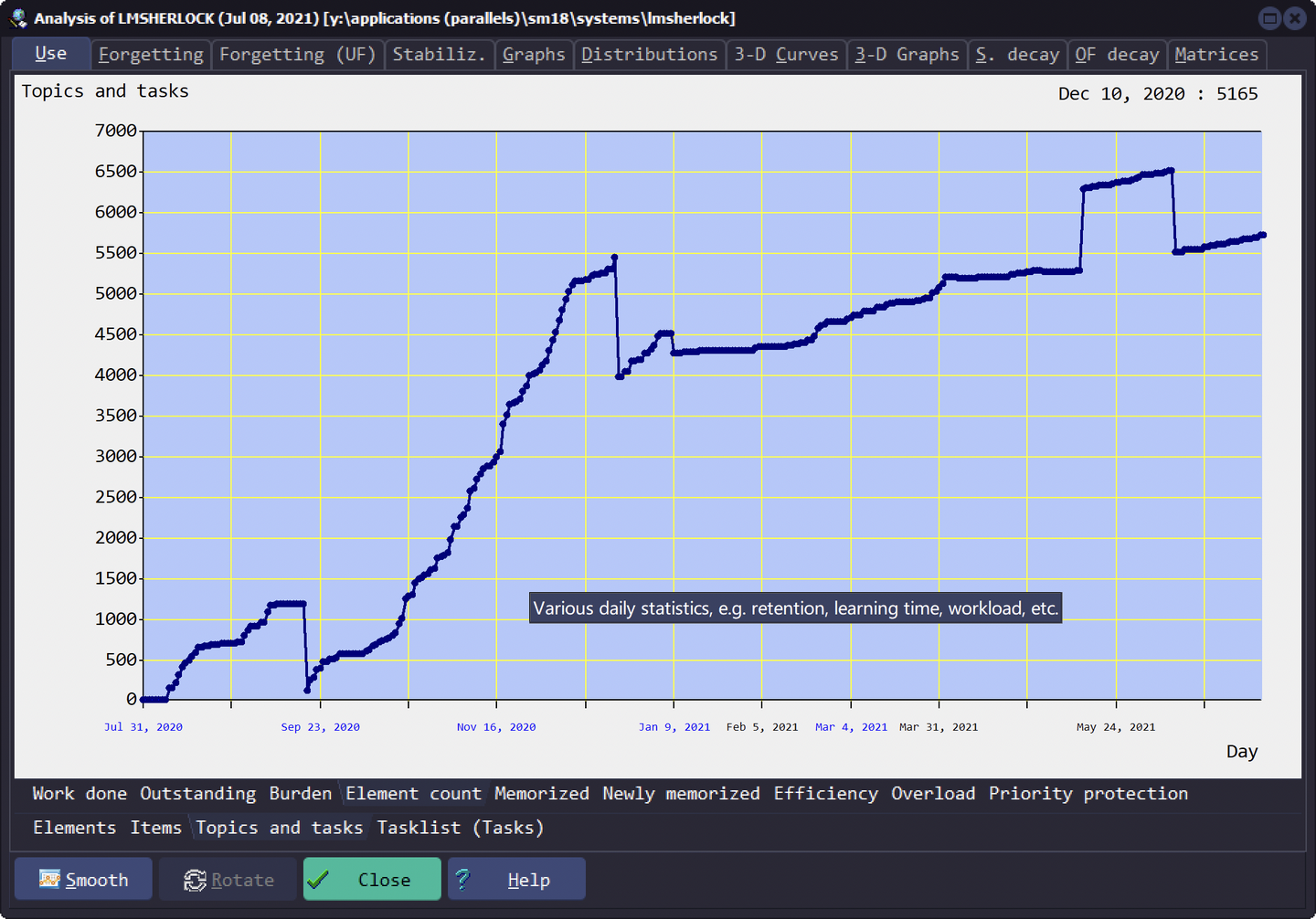
顾名思义,就是卡片总数,如果新增卡片,就会变大,删除卡片就会变小。
已记忆的卡片总数
Use - Memorized - Memorized items
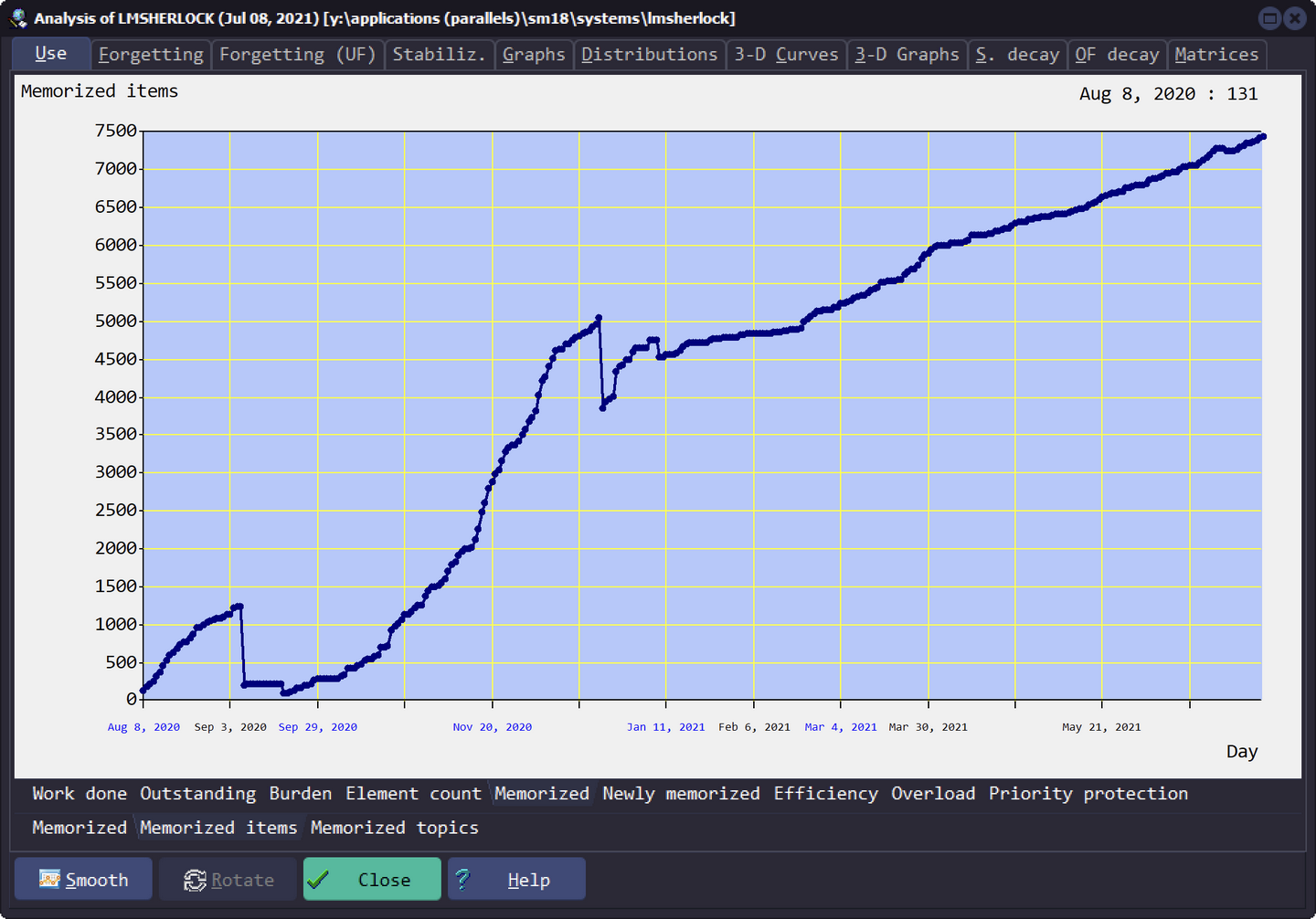
已记忆的卡片就是进入复习状态的卡片,不包括被 dismiss 或 forget 的卡片。
每日新记忆的卡片数
Use - Newly memorized - New items
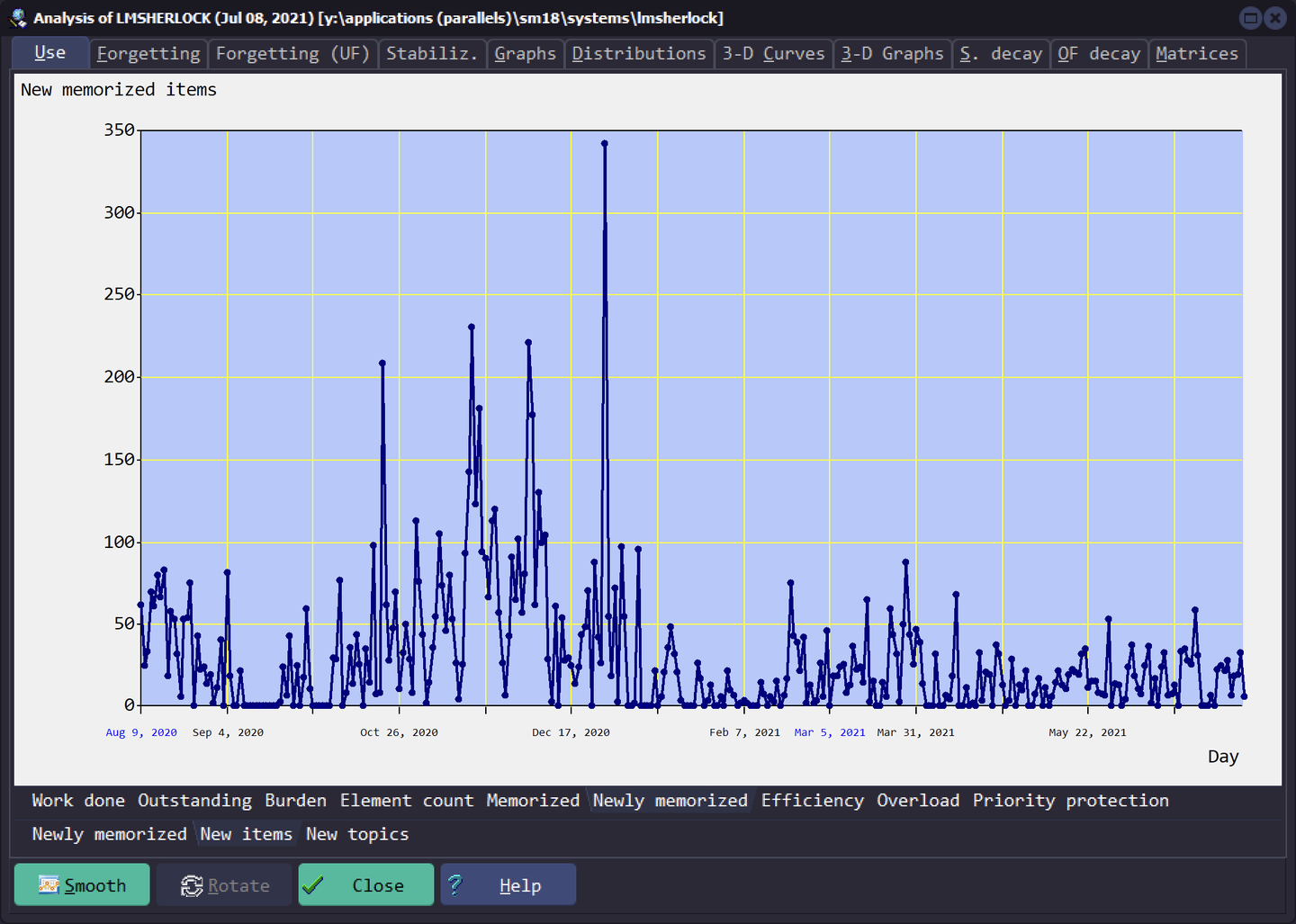
顾名思义,就是每天新学的卡片数量,这里要注意:新增、挖空和摘录都算作新记忆,而从外部导入到 pending 队列的卡片需要在 new material 里面学过后才当做新记忆。
每日遗忘指数
Use - Efficiency - Forgetting index
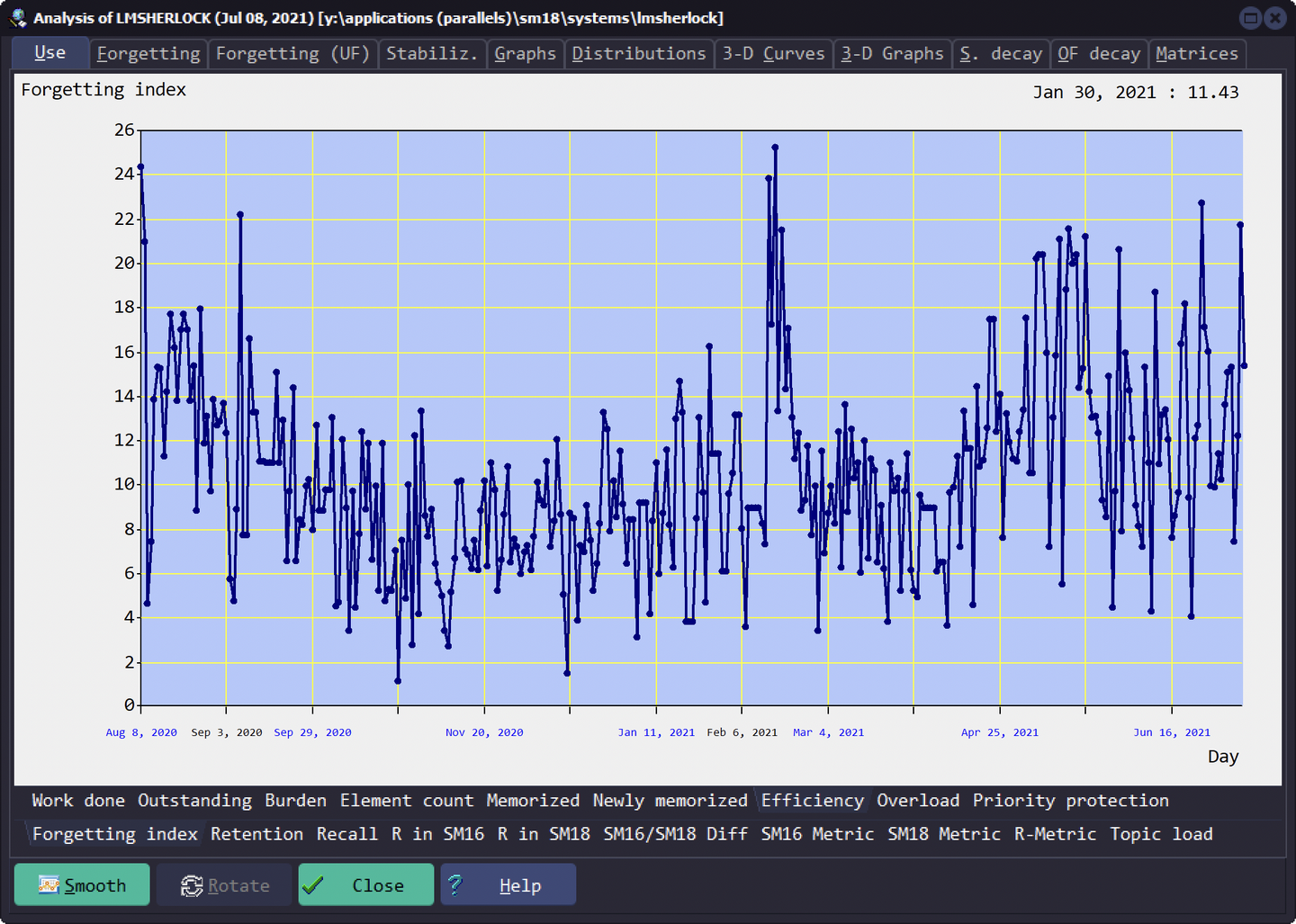
每日遗忘指数就是当天遗忘的卡片数量比去当天复习的卡片数量即 [forget / (forget + recall)]
每日超负荷
Use - Overload - Items
下图经过 smooth 处理
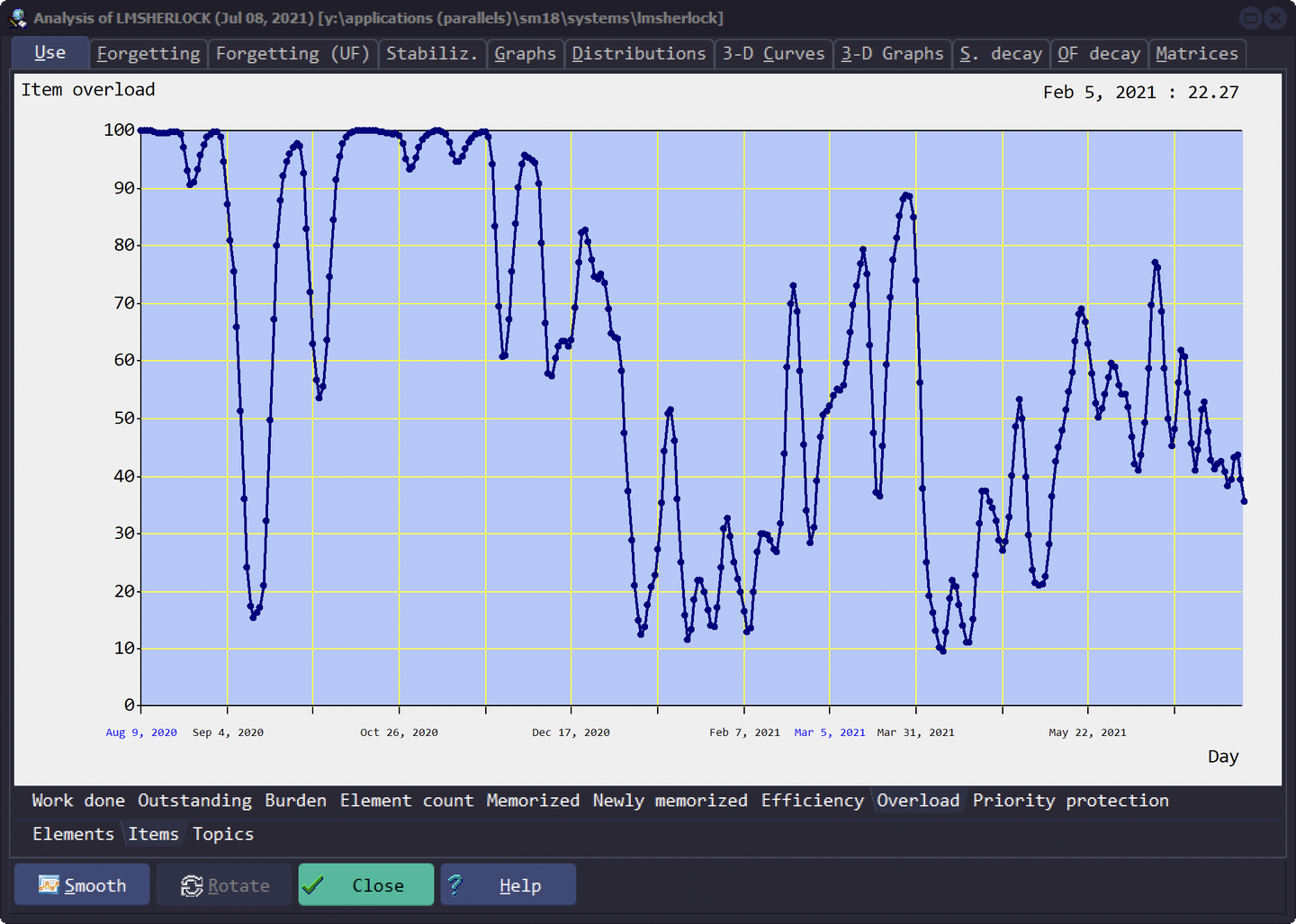
实际复习 / 算法安排,100% 就是完成当天算法安排的所有复习,如果当天的 Outstanding 中有 100 张卡片,而我只处理了 40 张,那么我当天的 overload 就是 40%
每日优先级保护
Use - Priority protection - Items
下图经过 smooth 处理
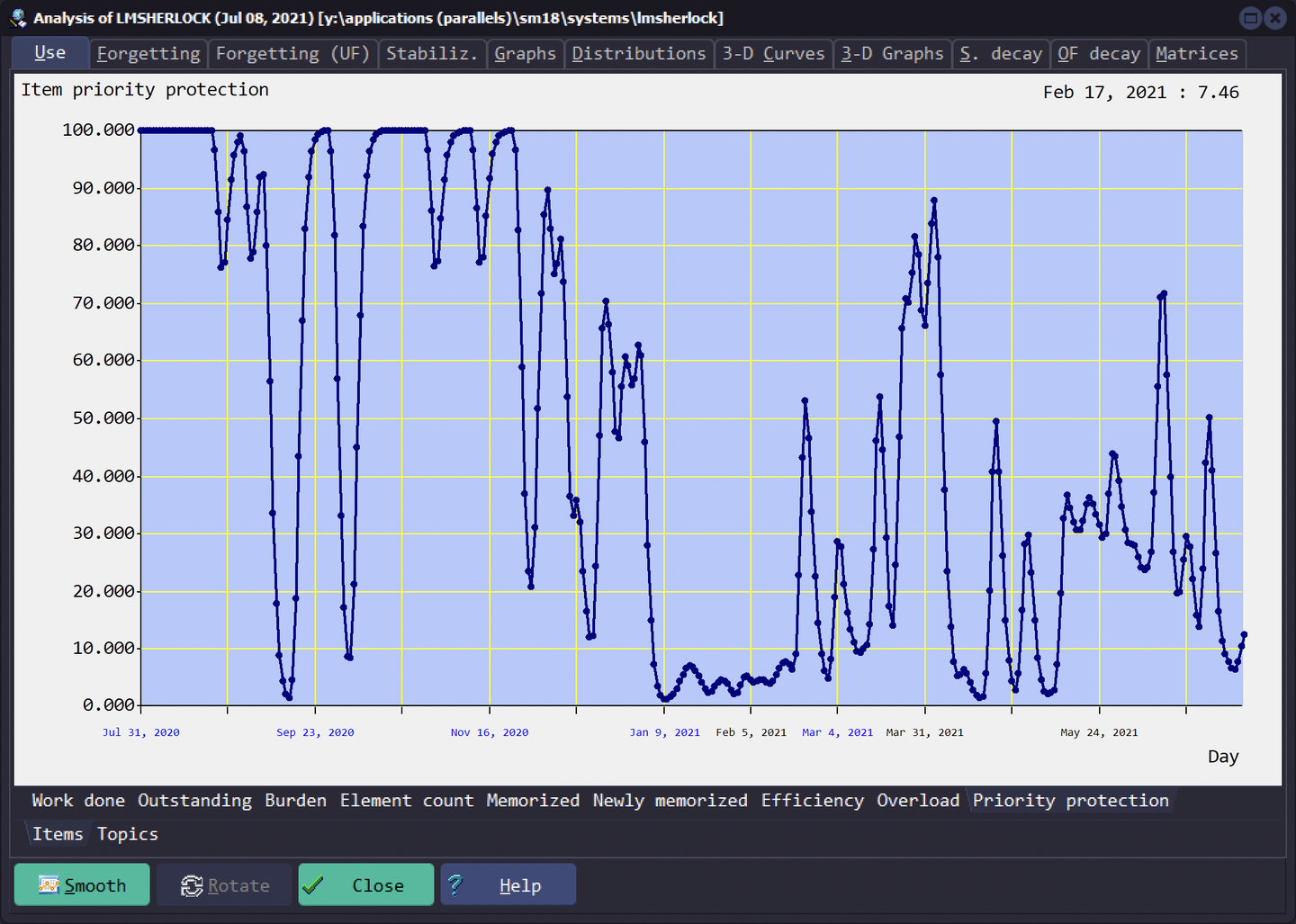
之前在《渐进阅读:卡片刷不完?拥抱优先级!》中介绍过了,此处不再赘述。
算法相关
第一次复习后的遗忘曲线
Forgetting - Stability: new
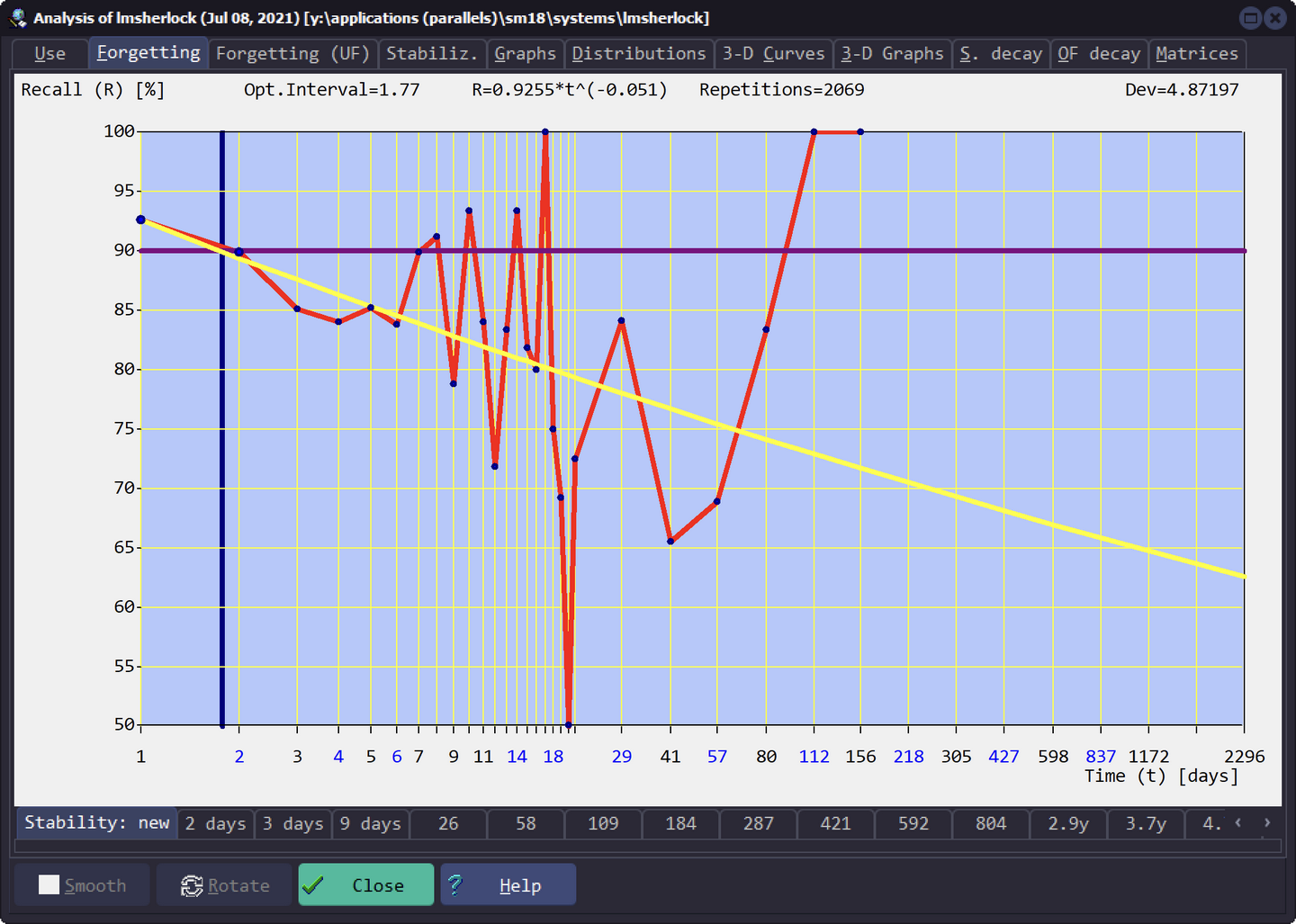
这条曲线表示的是,一张卡片被第一次记忆后的遗忘曲线。蓝色的点代表真实值,黄色的线代表拟合后的曲线。蓝色纵线表示的是保留率为 90% 所对应的间隔天数。
一般来说,如果应用良好的制卡原则,黄色线会更加平缓,蓝色纵向也会更靠近右侧。
第一个间隔与累积遗忘次数的关系
Graphs - First Interval
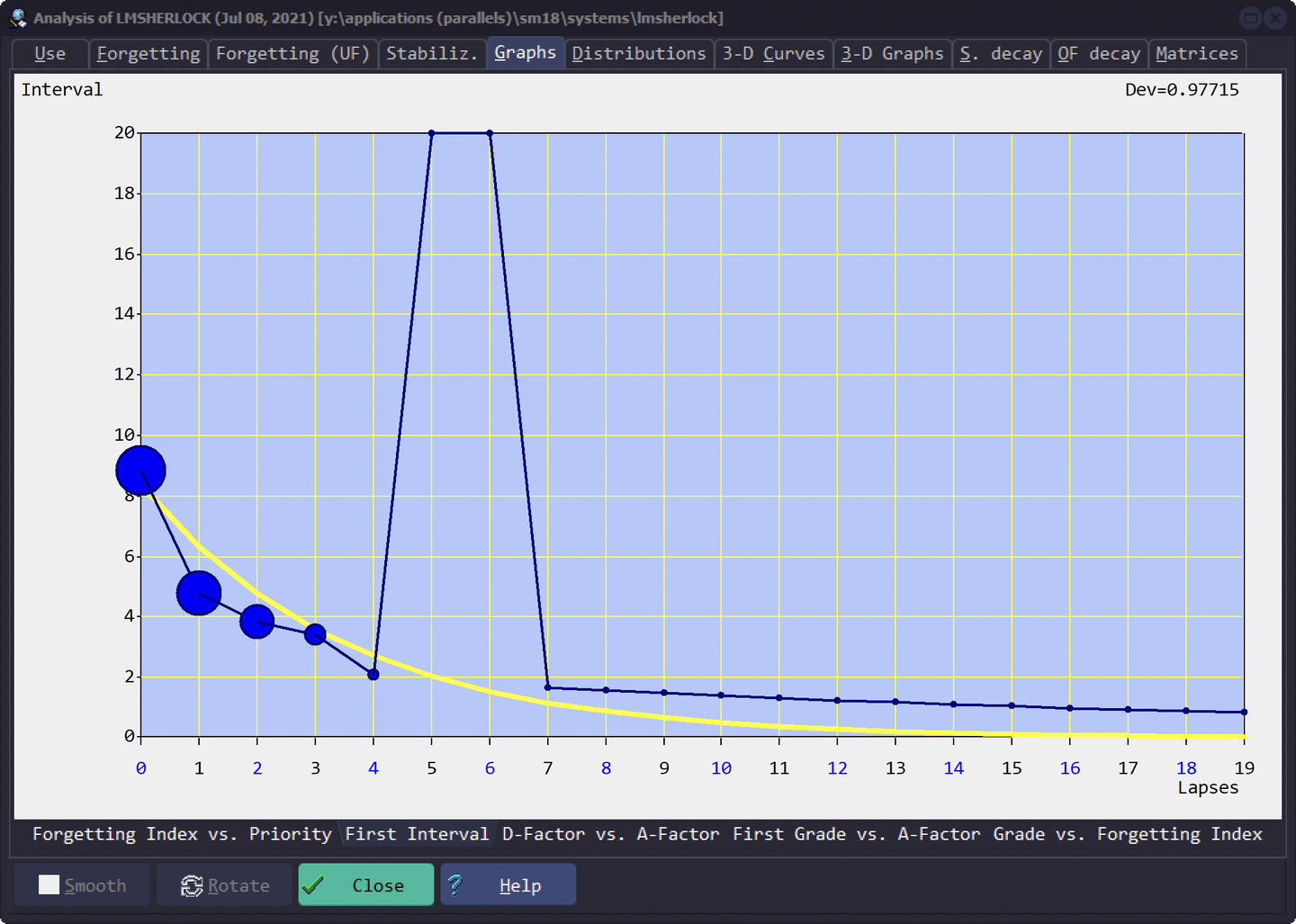
该曲线表示的是,不同累积遗忘次数的卡片,在被遗忘后(或者是第一次复习),最佳间隔天数与累积遗忘次数之间的关系。
蓝色的点即统计值,点的相对大小表示该点统计样例数量的相对多少,黄色线是拟合结果。
间隔矩阵
Matrices - Intervals
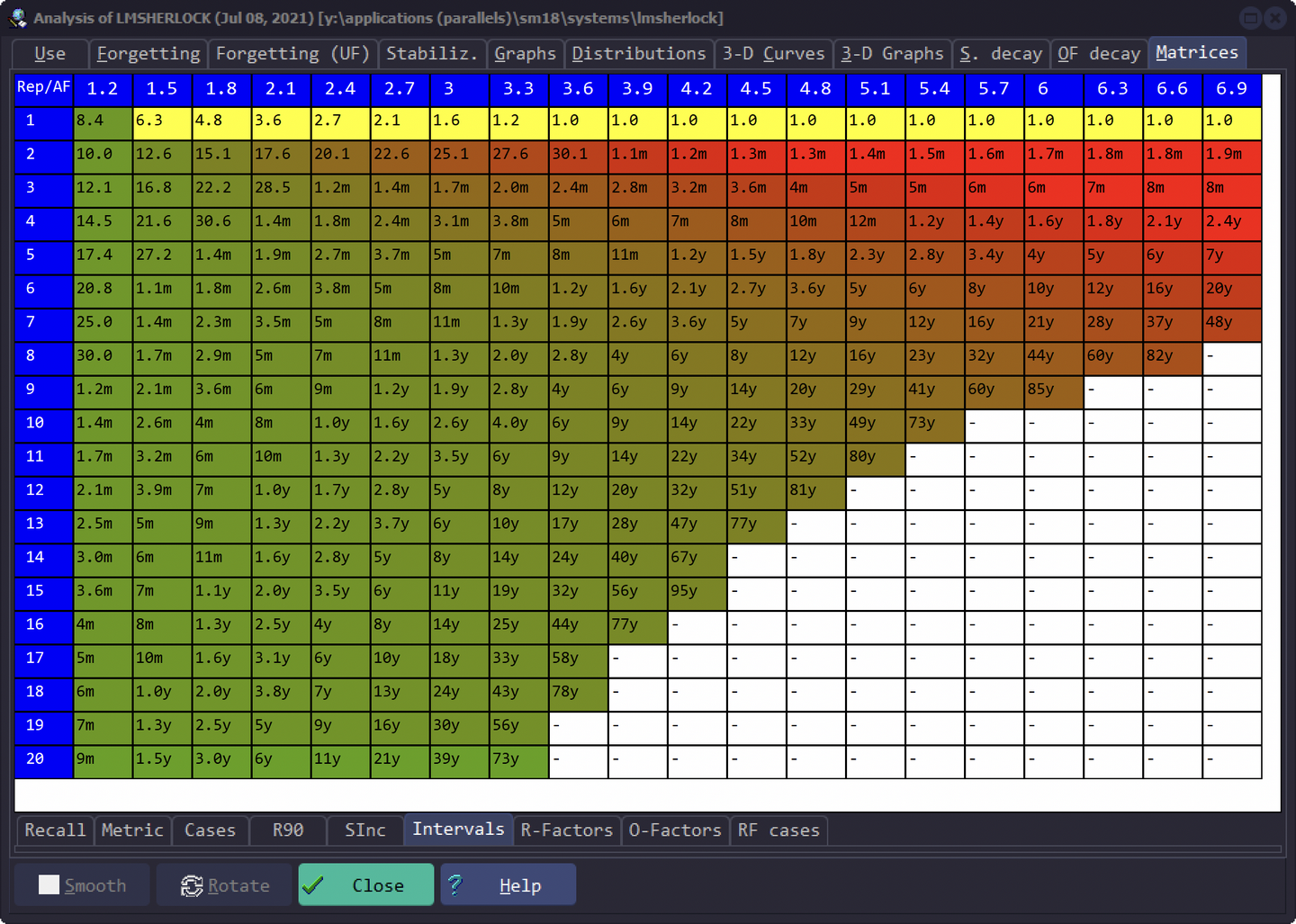
本矩阵是由 SM-15 算法按照用户复习数据拟合出的间隔矩阵,横索引代表卡片难度,越大越简单,纵索引表示连续记住次数。
本矩阵并未用于实际的复习安排,仅做参考。
结语
以上就是我认为值得了解的统计数据,更多数据的详细解释,可以参考官方文档:https://help.supermemo.org/wiki/Analysis
不建议 SuperMemo 新手对这些图表了解太多,原因有二:
其一,数据量太少偏差较大,没有参考价值;
其二,用好 SuperMemo 的基本功能更重要。
希望我的文章对大家有所帮助,谢谢!