

记得上次写原创……还是在上次?哈哈开个玩笑,不知道大家有没有注意到,我最近发布翻译文章的速度快了不少?质量还变高了?本文我就讲讲如何提高业余翻译效率。
面向读者:有一定编程基础、用爱发电的业余翻译者
更新
感谢 Shom 编写的翻译教程:
Shom:Thoughts Memo 汉化组 ParaTranz 翻译教程背景
在 18 年,我就用业余时间搞翻译了,虽然我英语不是很好,但还是做了几十万字的翻译。返回去看那些翻译,质量惨不忍睹。痛定思痛之后,我打算召集一些志愿者,一起翻译,互相校对,兼顾翻译质量和效率。
一开始我们采用 GitHub 作为协作平台,用 git 管理翻译项目,用 pull request 来合并翻译。不过由于 git 对非程序员朋友十分不友好,导致翻译《我们如何才能开发出变革性的思想工具? 》这篇长达 4 万字的文章,花了我们 3 个人将近 2.5 个月的时间。
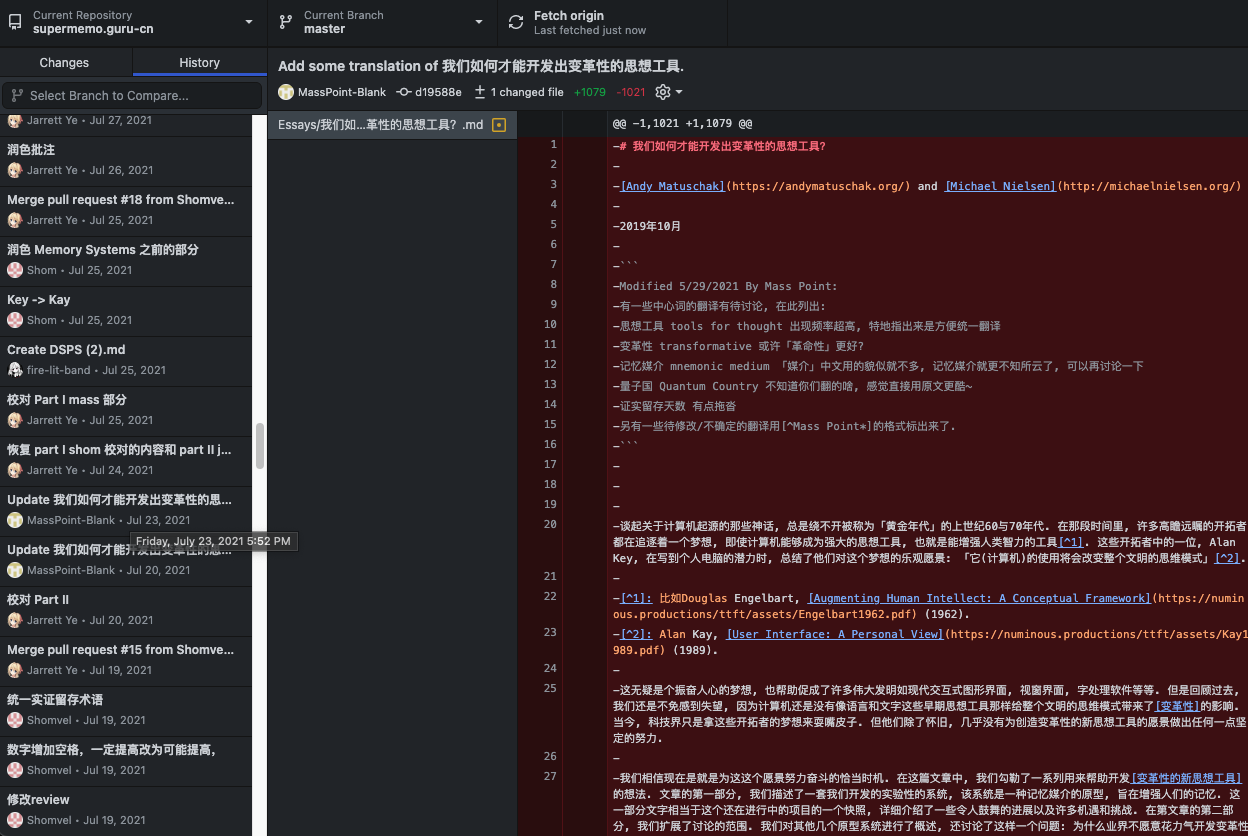
其中还不乏因为 git 比对差异不符预期,导致未翻译内容覆盖了已翻译的内容。
由于这些问题,协作翻译的摩擦太大,使协作带来的收益不足以覆盖协作的成本。最终使得翻译项目停滞。
起因
在群里抱怨翻译太慢之后,有群友向我推荐了 Paratranz 这个翻译平台
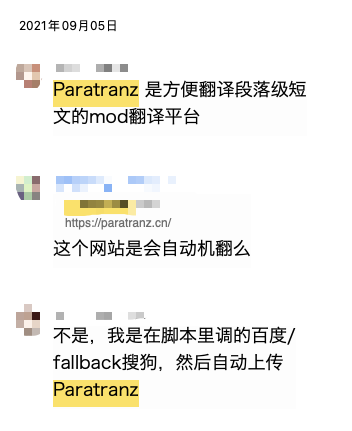
这个平台的翻译界面功能很全:
而且还是国人开发的,本来用于翻译 P 社 mod:
ParaTranz我一看,感觉针不戳,就开始上手了。
创建项目
首先,我们先按流程来,创建一个项目:
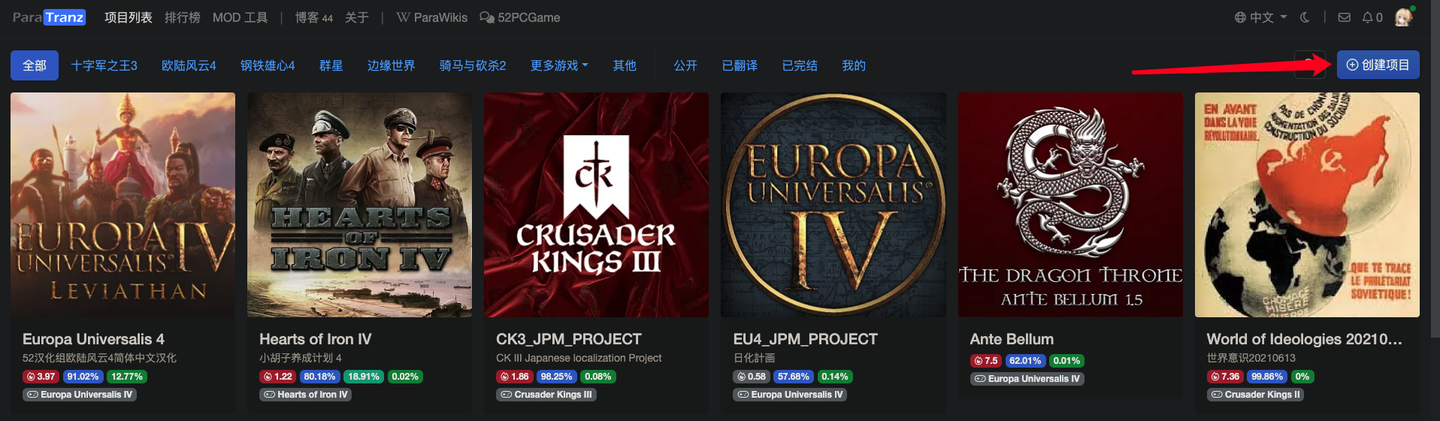
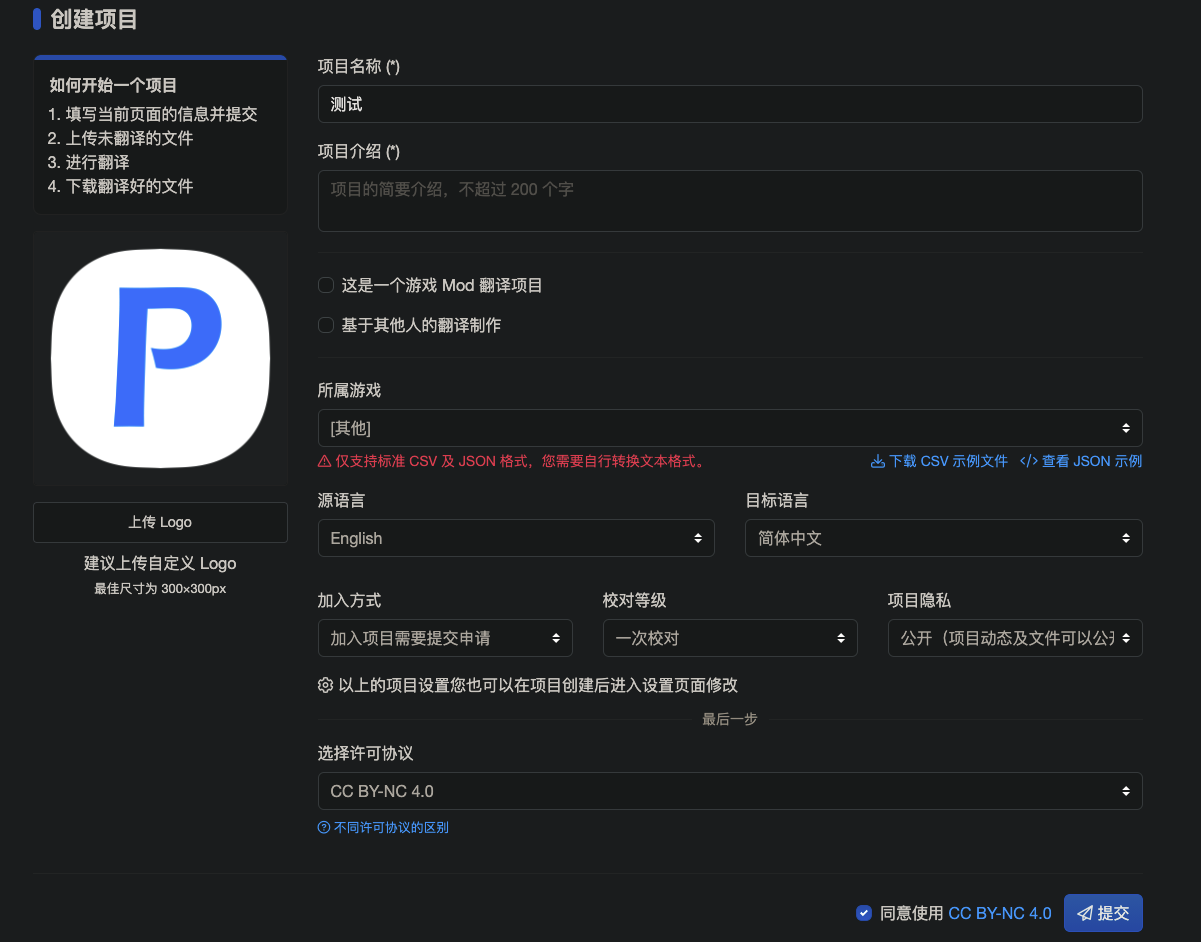
这些内容都按要求填写就行了,所属游戏填「其他」,至于选用什么许可协议,可以看这篇介绍:
漠伦:“知识共享”(CC协议)简单介绍建好了项目后,就可以在「我的」标签下面找到自己创建的项目了:
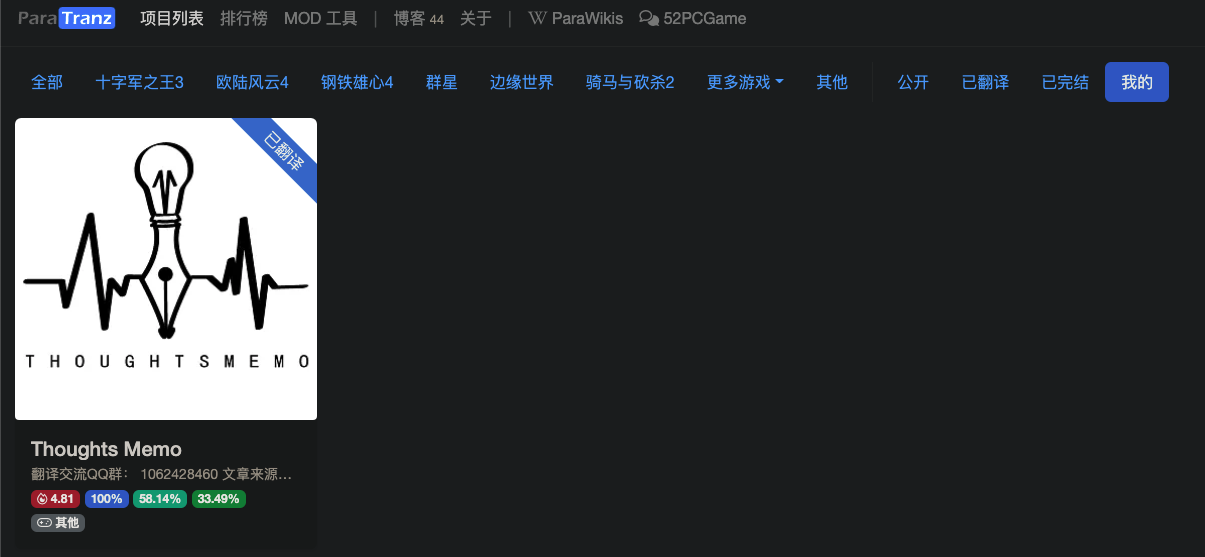
添加翻译
有了项目,没有待翻译的文本,我们还不能开始翻译。由于这个平台主要是用于翻译游戏 mod 内的描述文本,用来翻译文章属于歪门邪道的用法,这里我们就需要使用平台翻译的通用格式:.csv 文件

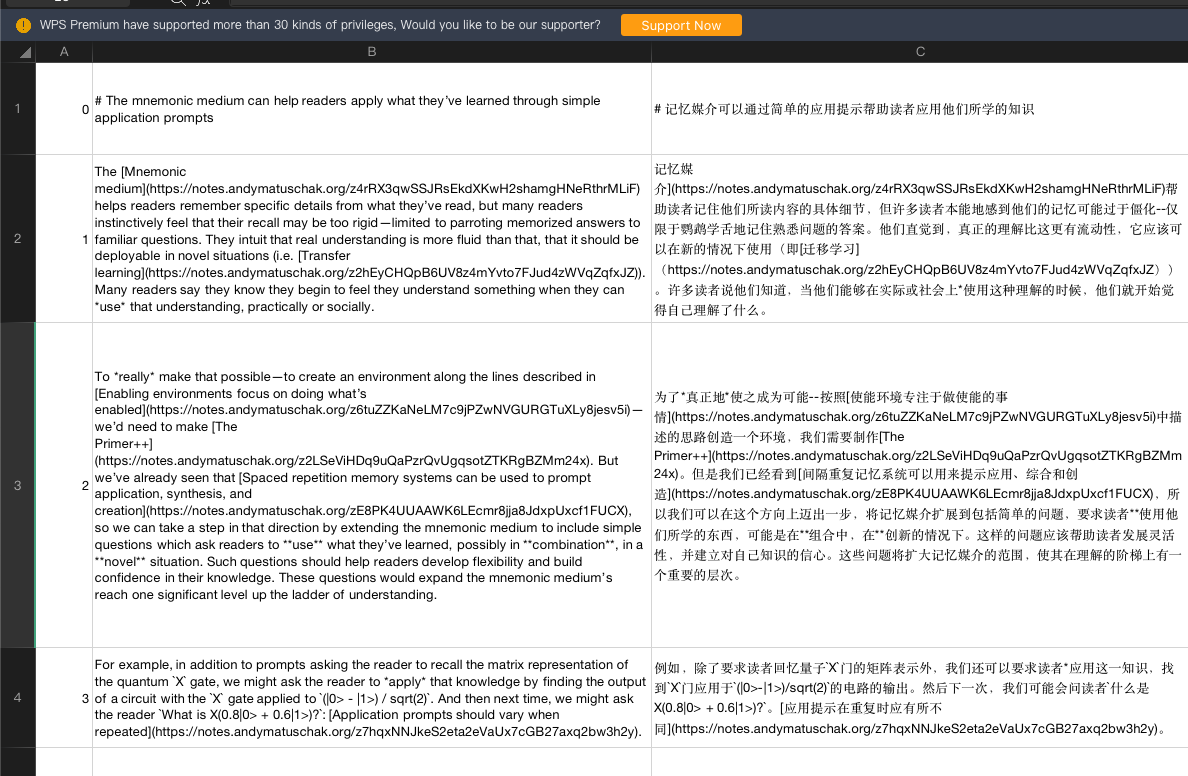
格式如图所示,第一列为索引值,第二列是原文,第三列是译文。
可能有人要问了,你不是搞翻译协作么?怎么上传的时候就有译文了?
别急,你可能还会问,把要翻译的文章搞成这种格式不累么?
没事儿,这些都可以自动化,为了提高翻译效率,我写了个 Python 脚本来实现格式转换和自动机翻:
import deepl
import os
import time
import pandas as pd
import shutil
from config import deepl_key
translator = deepl.Translator(deepl_key)
def countspaces(x):
for i, j in enumerate(x):
if j != ' ':
return i
def translate(file, filename):
save = pd.DataFrame(columns=['Source', 'Translation'])
queries = file.readlines()
for query in tqdm.tqdm(queries):
query = query.rstrip()
if query == '':
continue
space = ' ' * countspaces(query)
try:
result = translator.translate_text(query.lstrip(), target_lang='ZH')
trans = result.text
if trans == '':
trans = query
time.sleep(0.1)
save = pd.concat([save, pd.DataFrame({'Source': [query], 'Translation': [space + trans]})],
ignore_index=True)
except Exception as err:
print(err)
save.to_csv(f'./machine_tranz/{filename}.csv', header=False)
if __name__ == '__main__':
trans_files = os.listdir('source')
for filename in trans_files:
with open(f'source/{filename}', 'r', encoding="utf-8") as f:
translate(f, filename)
shutil.move(f'source/{filename}', f'./src_fin/{filename}')
思路很简单
- 先把想要翻译的文章贴到一个文本文件里面
- 再用 Python 脚本处理,遍历原文的所有段落
- 然后对每个段落调用 deepL 的翻译接口
- 将返回的译文和原文一起存到 pandas 的表中
- 按照平台要求的格式保存成 .csv 文件
- 上传至 Paratranz 平台
注:DeepL 也可以替换为其他机翻接口
这样讲有点抽象,下面拿一篇文章演示一下
图片演示
原文:
复制到 typora,并保存到待处理文件的目录下
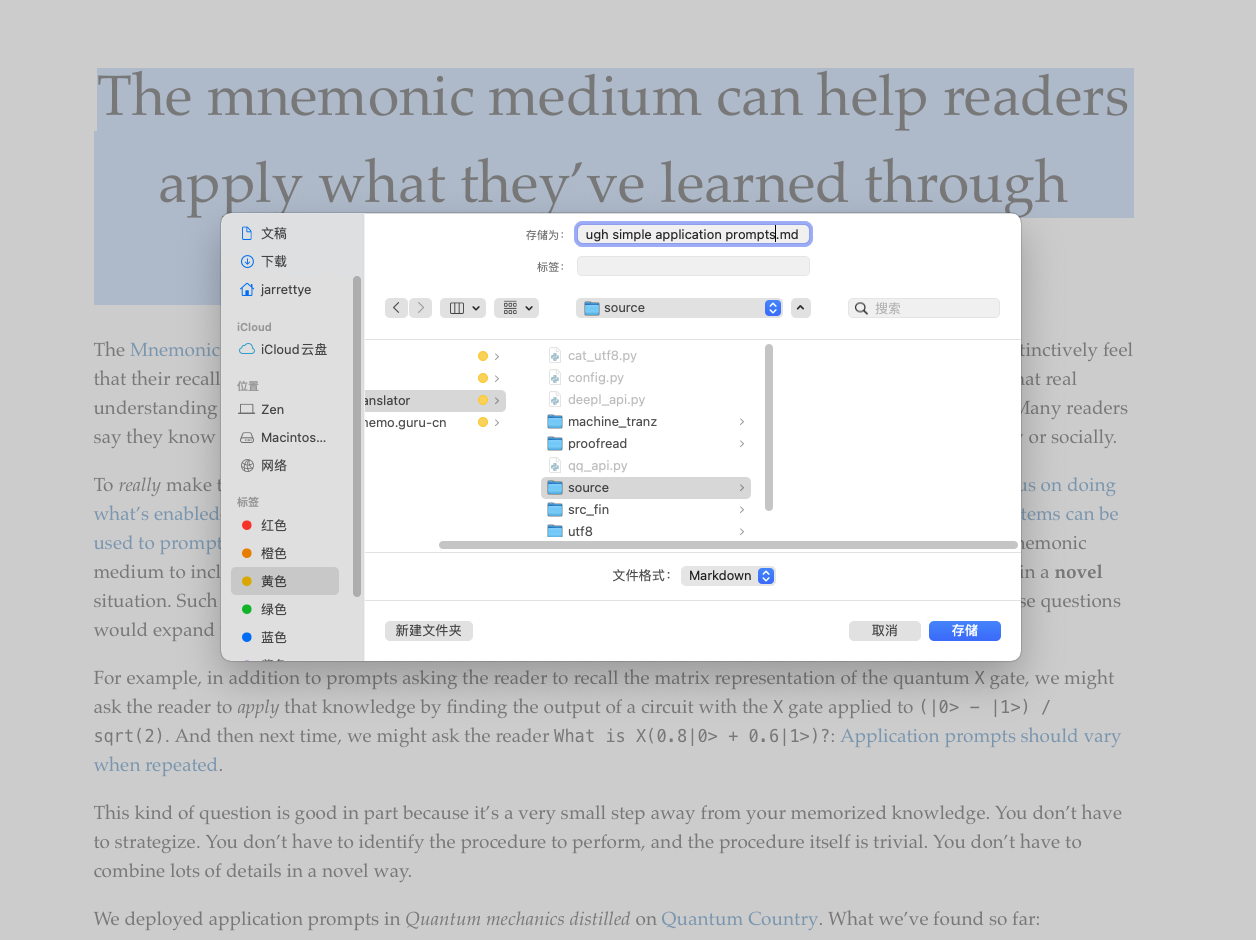
运行脚本:
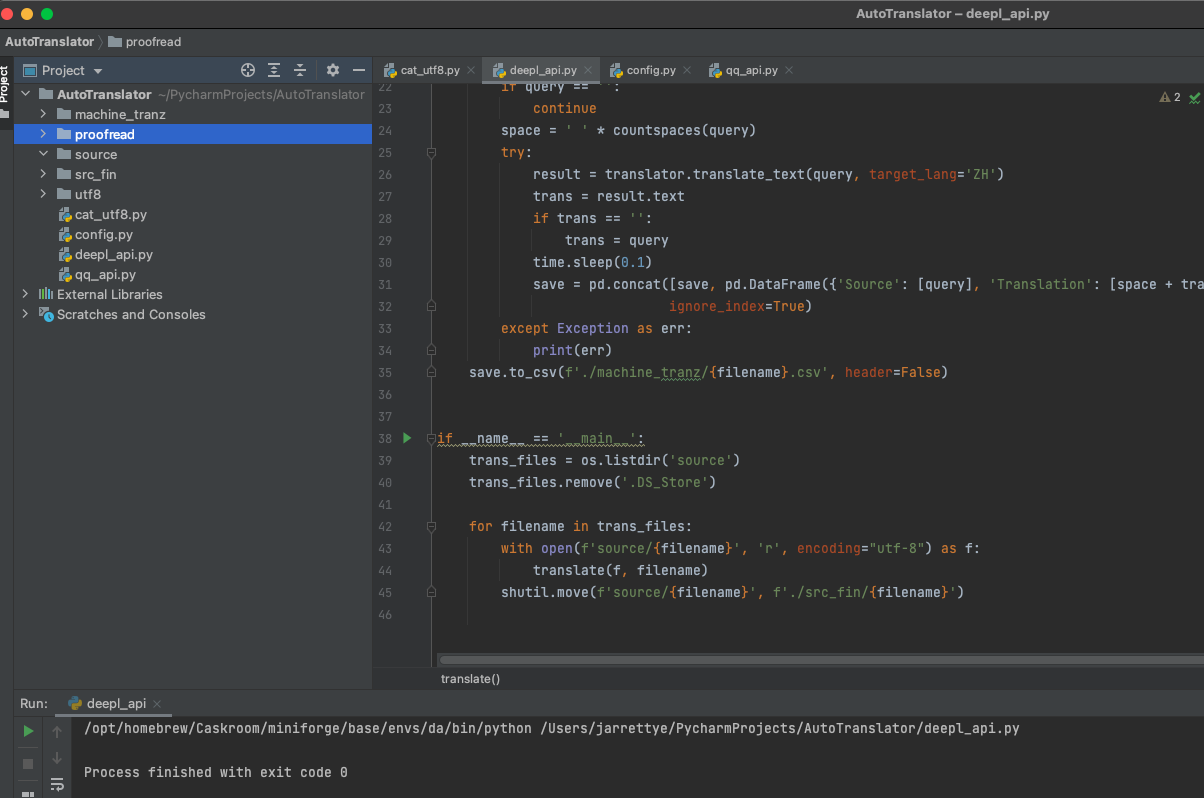
最终文件:
上传平台:
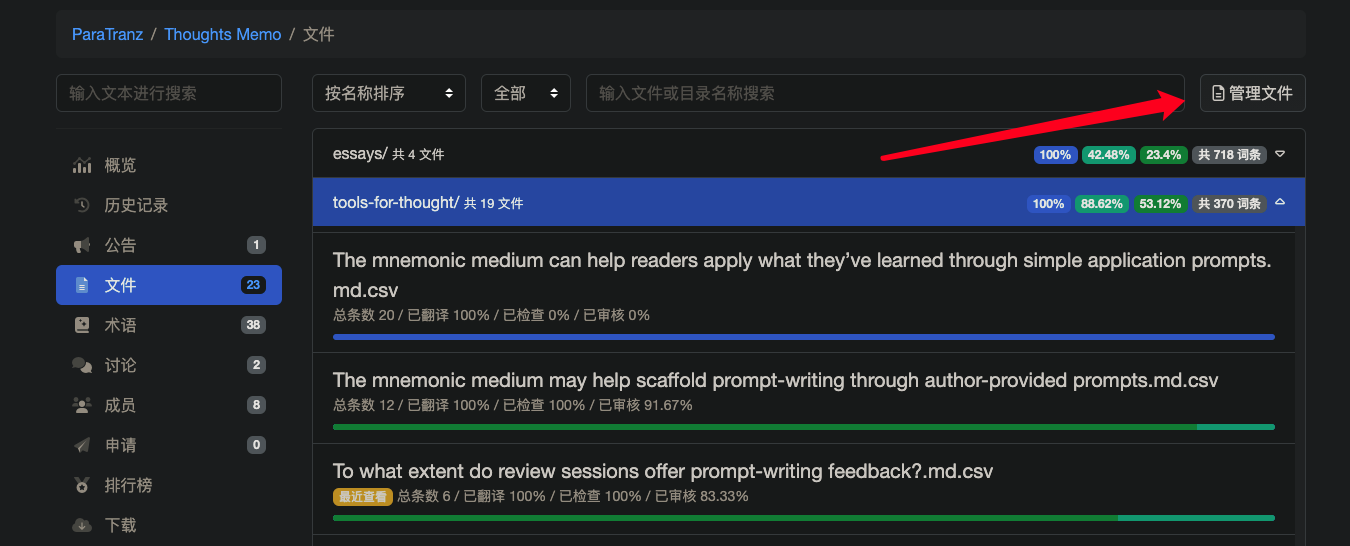
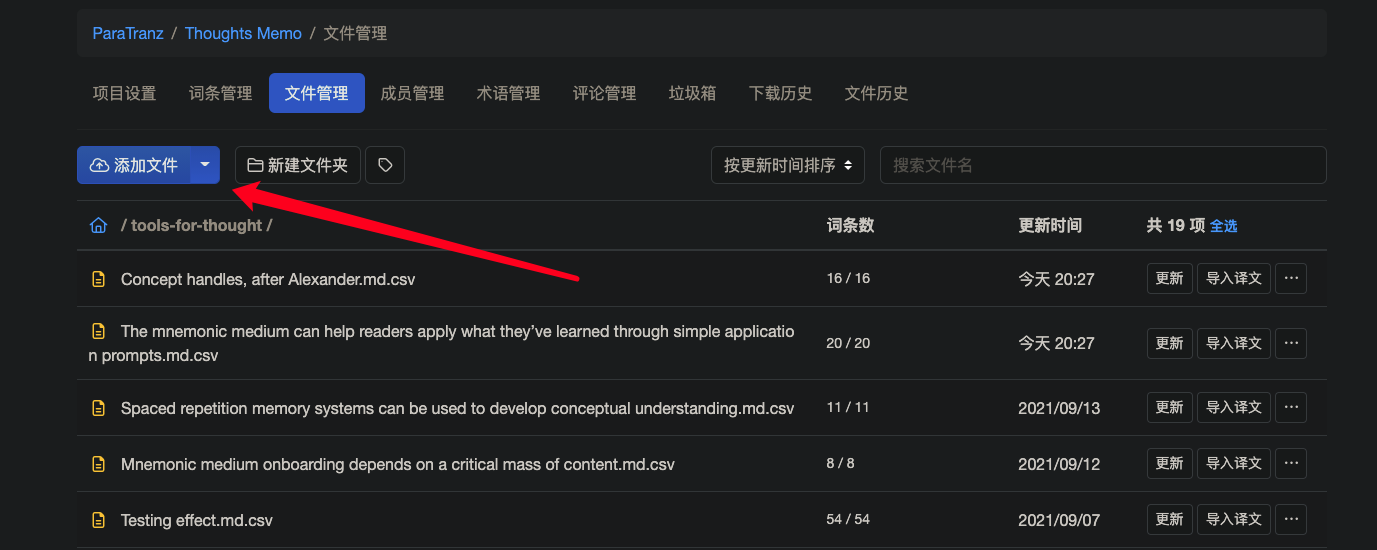
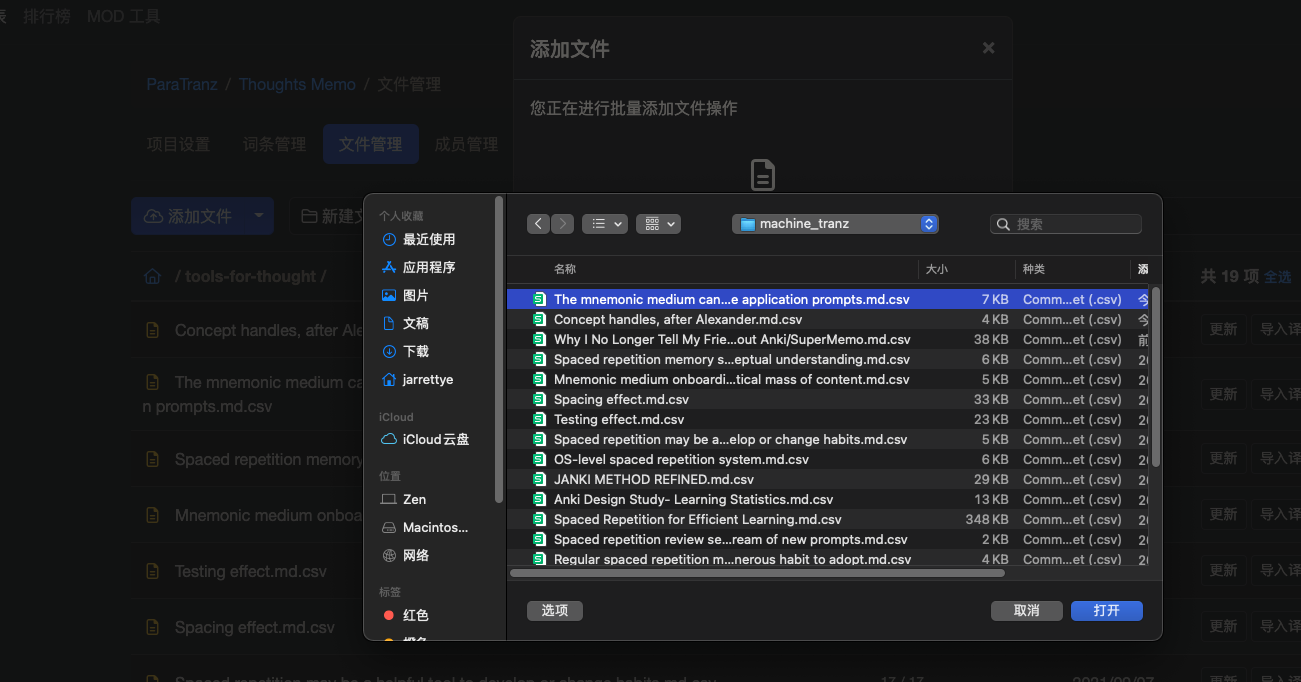
查看效果:
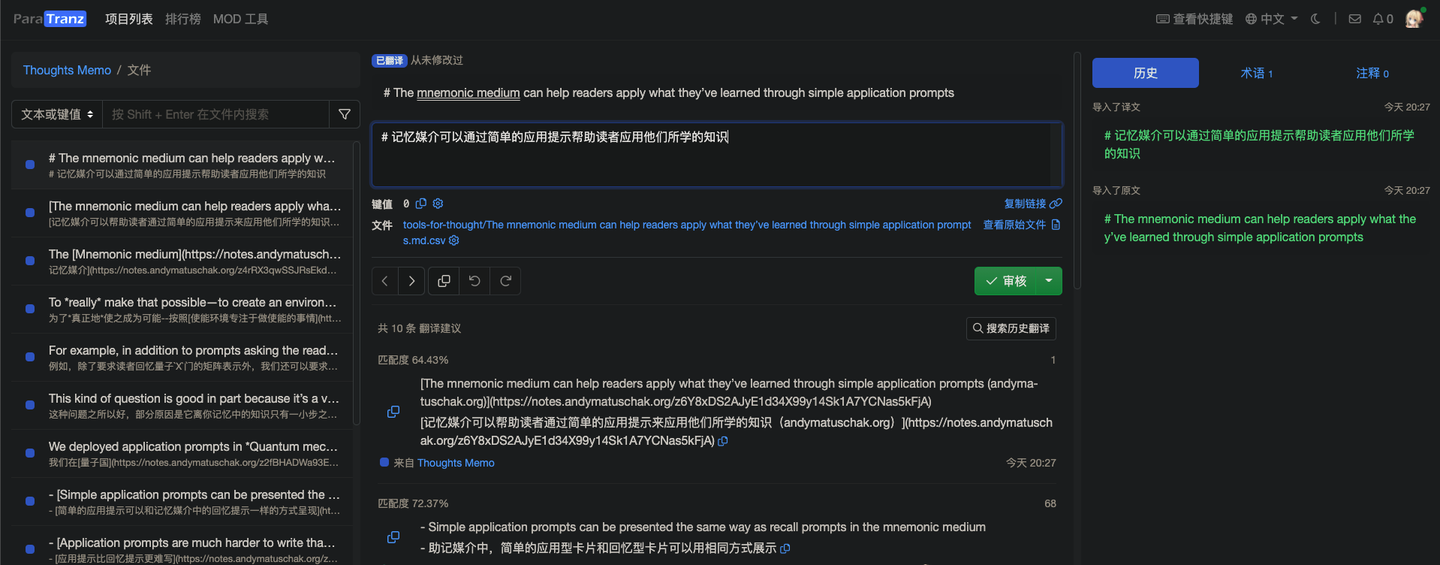
前前后后大概花不到一分钟就能搞定,如果同时添加多个文件,效率还能更高。
开始协作
有了待翻译的文本,还有已经预先上传的机器翻译,接下来只需要邀请你的朋友加入项目就能愉快地开始协作了~
具体的协作教程,已经有人写过了,这里就不赘述了:
ShirahaneSuoh:汉化组翻译指南节选 - 如何使用云平台发布译文
和朋友们吭哧吭哧翻译了好多文章,现在想把译文整合一下发布出去?总不能一段一段复制出来吧?这里简单说说怎么把翻译好的文章处理成易于阅读的格式。

首先需要到下载这里,将翻译成果下载下来,解压一下,会得到以下文件:
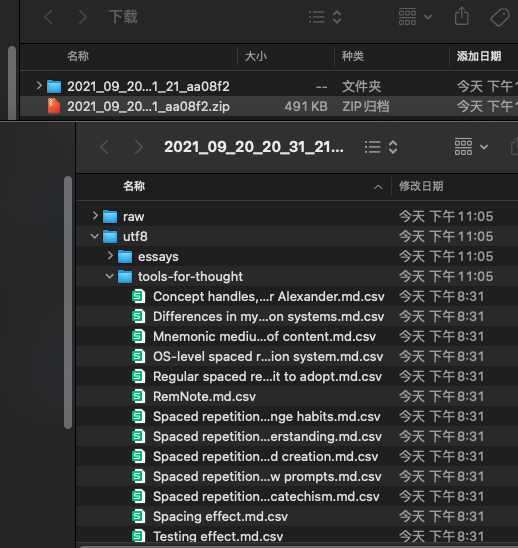
点开一看,和我们上传的格式一致,除了译文部分已经被更新成我们人工润色和校对后的内容

这里我也是写了一个脚本自动处理:
import pandas as pd
import os
if __name__ == '__main__':
trans_files = os.listdir('./utf8/tools-for-thought')
for filename in trans_files:
text = pd.read_csv(f'./utf8/tools-for-thought/{filename}', header=None, index_col=0)
text.columns = ['source', 'target']
text.dropna(inplace=True)
with open(f'./proofread/{filename[:-4]}', 'w', encoding='utf-8') as f:
f.writelines('\n\n'.join(text['target'].values))
最终处理的结果:

然后把这个文本贴到任何你想要发布的平台即可!
结语
本文初衷就是分享一下自己是如何用 Paratranz 和 DeepL 提高业余翻译效率的,如果能帮到各位,十分荣幸。
用 CAT 的专业翻译请轻喷,谢谢~
叶峻峣
2021 年 9 月 20 日