
问题描述
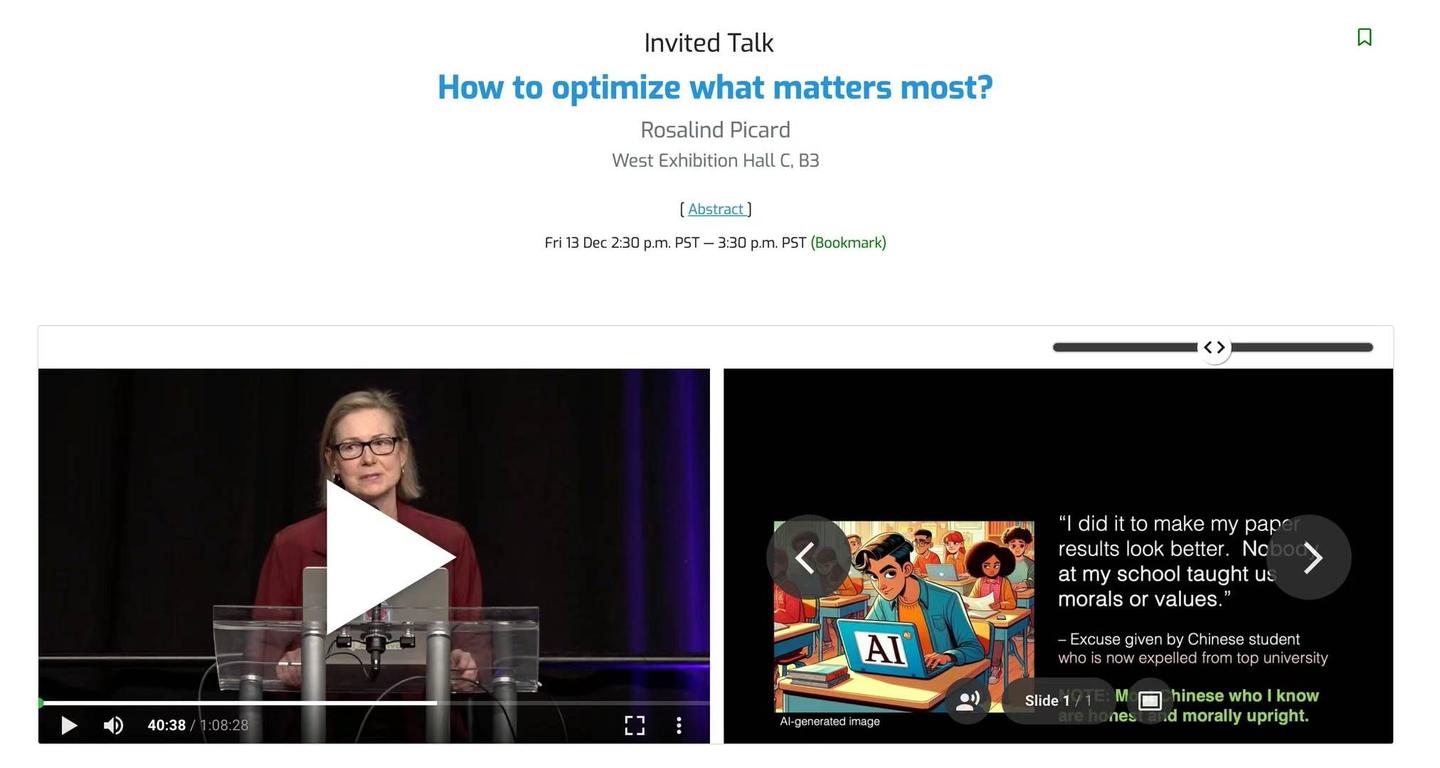


因为这事我还和互关的一个 2 万 fo 的英文推主聊起来了。
事先声明:我反对任何歧视行为
起因:我看到了 NIPS 的官方声明
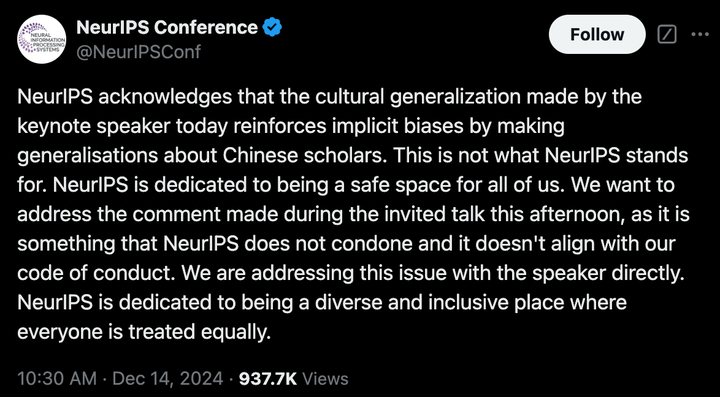
结果下面的高赞评论说中国人发表的论文撤稿率很高,对来自中国的研究更加怀疑是完全公平的。
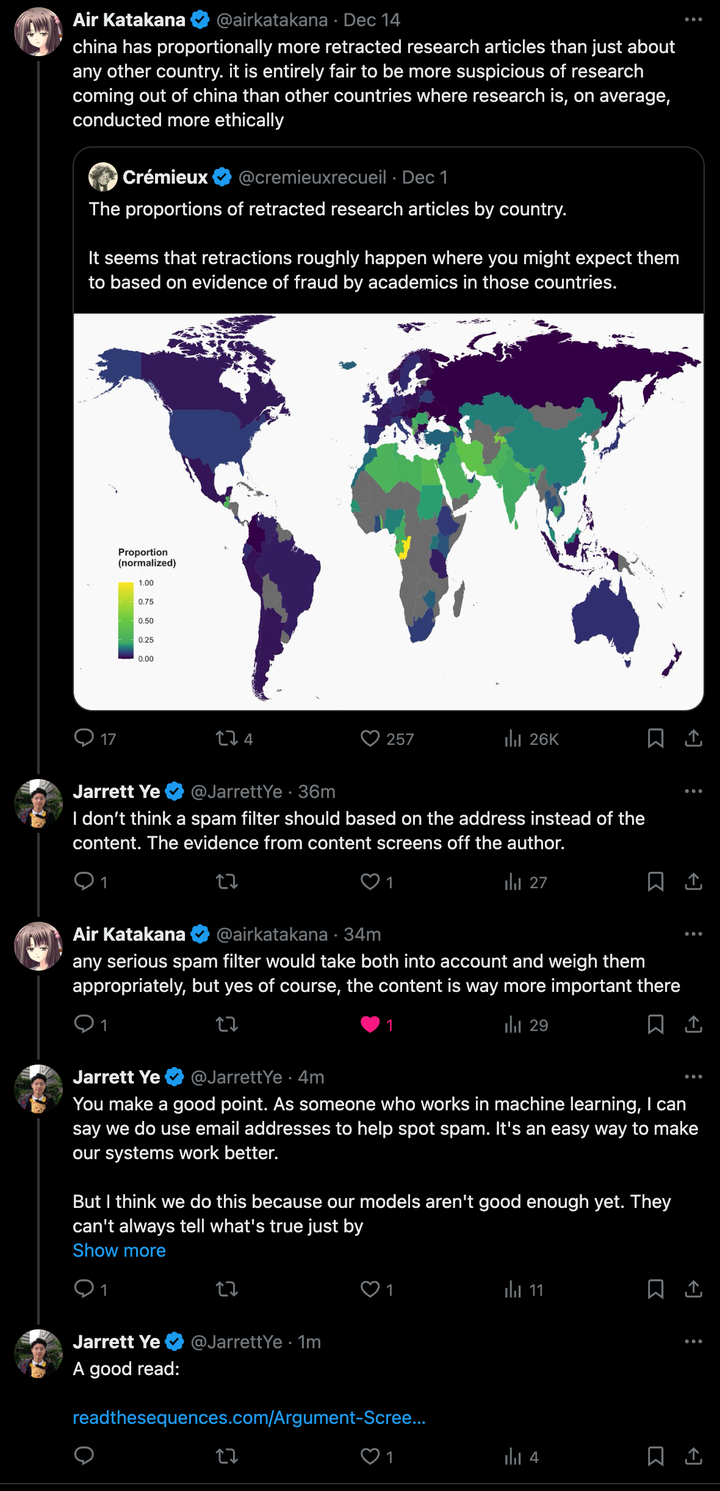
看到这我有点没绷住,于是和 TA 理论起来,下面是我们之间的对话:
@JarrettYe
I don’t think a spam filter should based on the address instead of the content. The evidence from content screens off the author.
我认为垃圾邮件过滤器应该基于内容而非地址。来自内容的证据可以屏蔽作者的影响。
@airkatakana
any serious spam filter would take both into account and weigh them appropriately, but yes of course, the content is way more important there
任何严肃的垃圾邮件过滤器都会同时考虑这两者,并适当加权,但当然,内容在那里的重要性要大得多
@JarrettYe
You make a good point. As someone who works in machine learning, I can say we do use email addresses to help spot spam. It's an easy way to make our systems work better. But I think we do this because our models aren't good enough yet. They can't always tell what's true just by looking at the words. In a perfect world, a true statement should be true no matter who says it. This is part of a bigger issue in AI. More data usually helps our algorithms work better. But most people don't want apps to collect lots of data about them. There are different things that matter here - like getting the right answer, keeping information private, and being fair to everyone. That's why we're working on new ways to do this, like federated learning. It tries to balance these different needs. In the end, I think we should try to judge things by what they say, not who says them. But for now, sometimes we have to use other information too because our technology isn't perfect yet.
你说得很有道理。作为机器学习的从业者,我可以肯定地说,我们确实利用电子邮件地址来帮助识别垃圾邮件。这是一种让我们的系统更高效运作的简便方法。 但我认为我们这样做是因为我们的模型还不够好。它们不能仅凭词语就总是判断出什么是真实的。在一个理想的世界里,一个真实的陈述无论谁说出来都应该是真实的。这是人工智能领域更大问题的一部分。通常,更多的数据有助于我们的算法更好地工作。但大多数人并不希望应用程序收集大量关于他们的数据。这里涉及不同的重要因素——比如得到正确的答案、保护信息隐私以及对每个人都公平。 这就是为什么我们正在探索新的方法,比如联邦学习。它试图平衡这些不同的需求。我认为最终我们应该根据言论本身来判断事物,而不是看是谁说的。但就目前而言,由于我们的技术尚未完美,有时也不得不借助其他信息。
推荐阅读:
Thoughts Memo:论证对权威的屏蔽效应