
如果你还没有读过上篇,我建议你先读一读:
叶峻峣:解释 FSRS(上篇):算法描述与运作原理注:我并不是 FSRS 的开发者。我只是一个在 GitHub 上经常提交错误报告和功能请求的普通人。但我对 FSRS 非常了解,特别是新版本的很多改动,都是我一手提议的。(校对:这人提了几十个 issue,累死我了)
很多人都对 FSRS 的复杂性抱有疑虑,质疑它是否真的能比 Anki 的简易算法更准确。许多人觉得 Anki 设置的复习间隔已经够好了(但这纯粹是个神话)。要想公正比较,我们得有个合适的指标。你脑海中最先浮现的是什么指标?
我猜你会说是每天的复习量。但其实,这指标一点都不靠谱。它并不能真实反映间隔时间是否合理,而且太容易被操纵了。想降低复习量?那就随便设计一个算法,比如直接将前一个间隔乘以 100。如果之前间隔是 1 天,那你下次复习就得等 100 天。如果上次是 100 天,那下次你就得等 10,000 天后。与 Anki 比,复习量自然是减少了。但对于真正学习效果来说?那肯定是大打折扣的。
这意味着我们需要一个不同的指标。
首先,你得知道这一点:每一个诚实的间隔重复算法,必须能够根据一张卡片的复习历史,预测在特定时刻,回忆起它的概率(R)。但 Anki 的算法并不具备这功能。它不进行概率预测,无法评估哪个间隔是最优的,哪个不是。因为在没有计算回忆概率的方法时,你无法确定什么是「最优间隔」。如果一个算法不能预测 R,那么我们根本无法评估它的准确度。
因此,乍一看,似乎很难在 Anki 和 FSRS 之间进行有意义的比较,因为后者预测了 R,而前者没有。但其实,有个巧妙的方法可以将 Anki 给出的间隔(实际上,我们比较的是 SM2,而不是 Anki)转化为 R 值。具体结果会取决于你如何调整它。
如果你此刻在想:「肯定有一种直白的方法来比较这两种算法,而不需要一篇该死的 3000 字的长文来解释吧?」那我很抱歉,答案是「没有」。
不过,现在是时候介绍一个非常有用的工具了,它被广泛用于评估二分类器的性能:校准图。二分类器是一类算法,它输出一个介于 0 到 1 之间的数字,可以解释为某物属于两个可能类别中的一个的概率。例如,垃圾邮件/正常邮件、生病/健康、回忆成功/回忆失败。
以下是从 u/LMSherlock 集合中得出的校准图(FSRS v4),包含 83,598 条复习记录:
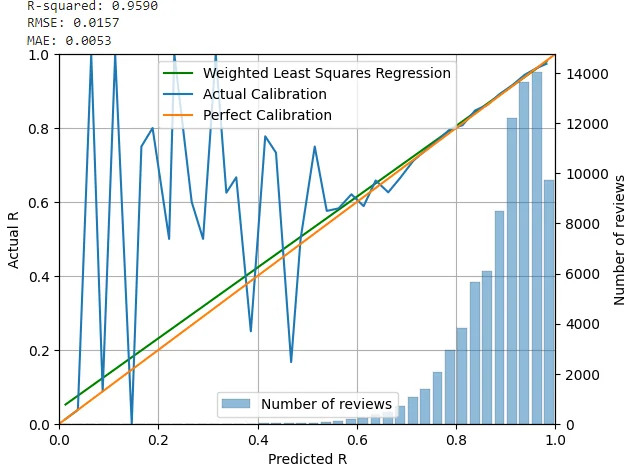
x 轴表示理论预测的回忆概率,y 轴表示实际测量的回忆概率。橙线代表一个完美算法。蓝线代表 FSRS。绿线只是一个趋势线,不必过于关注。
以下是其计算方法:
1) 将所有复习记录按预测值分组。例如,从 1.0 到 0.95,从 0.95 到 0.90 等。
以下面的例子为例,我们把所有 0.8 到 0.9 之间的预测值放在一个组:
第一组(预测):[0.81, 0.85, 0.87, 0.87, 0.89]
2) 对于每个组,测量复习记录的实际结果,是 1 还是 0。「重来」= 0。「困难/良好/容易」 = 1。别担心,这并不意味着你选择的「困难」、「良好」或「容易」没有任何影响。评分依然重要,只是在这里没那么重要。
第一组(实际):[0, 1, 1, 1, 1, 1, 1]
3) 计算每个组内所有预测值的平均值。
第一组平均值(预测) = mean([0.81, 0.85, 0.87, 0.87, 0.89]) = 0.86
4) 计算每个组内所有实际结果的平均值。
第一组平均值(实际) = mean([0, 1, 1, 1, 1, 1, 1]) = 0.86
对所有组重复上述步骤。组数的选择是任意的;上图用的是 40 组。
5) 以预测的 R 值为 x 轴,测量的 R 值为 y 轴,绘制校准图。
橙线代表一个完美算法。如果某个事件发生的概率是 x%,而算法预测的概率也是 x%,那么这就是一个完美算法。预测的概率应该与实际(观察到)的概率相匹配。
蓝线代表 FSRS。蓝线与橙线越接近越好。换句话说,预测的 R 值与测量的 R 值越接近越好。
图表上方写着 MAE=0.53%。MAE 是平均绝对误差的英文缩写。可以理解为「预测误差的平均幅度」。0.53% 的 MAE 意味着 FSRS 的平均预测与实际情况只有 0.53% 的偏差。当然,MAE 越低越好。
简单地说,我们取预测结果,取实际结果,各自取均值,然后看两者之间的差异。
你可能会想:「等一下,当预测的 R 值小于 0.5 时,蓝线看起来就像垃圾!」但那是因为那个区域的数据实在太少了。这并不是 FSRS 的一个小缺点。事实上,几乎所有的间隔重复算法都会有这种表现,因为用户希望有较高的记忆保留率,于是开发者就制定了能产生较高保留率的算法。计算 MAE 时,需要根据各组内的复习数量对预测值进行加权,这就是尽管图表左下方部分看起来表现不太好,但 MAE 仍然很低的原因。
如果你对校准图仍然有些困惑,这里有一个简单的例子:假设天气预报说今天下雨的概率是 80%;如果今天没下雨,这并不意味着预测是错误的——他们并没有说他们有 100% 的把握。相反,这意味着在平均情况下,每当天气预报说下雨的概率是 80% 时,你应该预期这些日子里有大约 80% 会下雨。如果天气预报说「80%」的概率时,实际上只有 30% 的日子下雨,那就意味着他们的预测结果和实际结果之间校准得很差。
现在,我们得到了一个数字,告诉我们 FSRS 的准确度如何,我们可以对 SM2(Anki 所基于的算法)进行同样的操作。
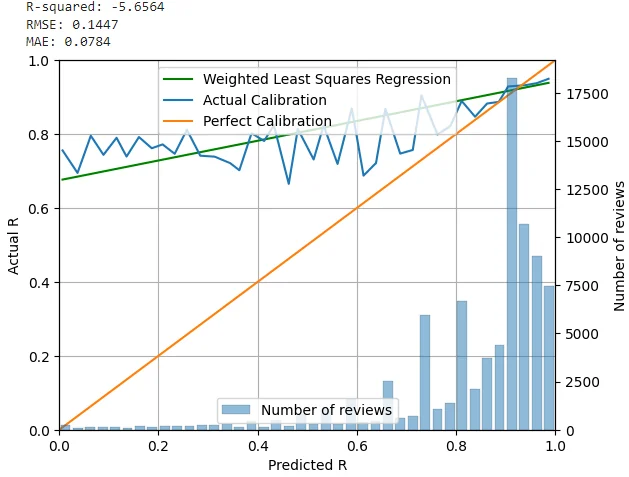
蓝线代表 SM-2 算法,橙线代表完美算法。再次强调,不必关注绿线,它其实不太重要。
胜负已分。
为了比较,这里有一个 SM-17 的校准图(SM-18 是最新版本),来源于:https://supermemo.guru/wiki/Universal_metric_for_cross-comparison_of_spaced_repetition_algorithms
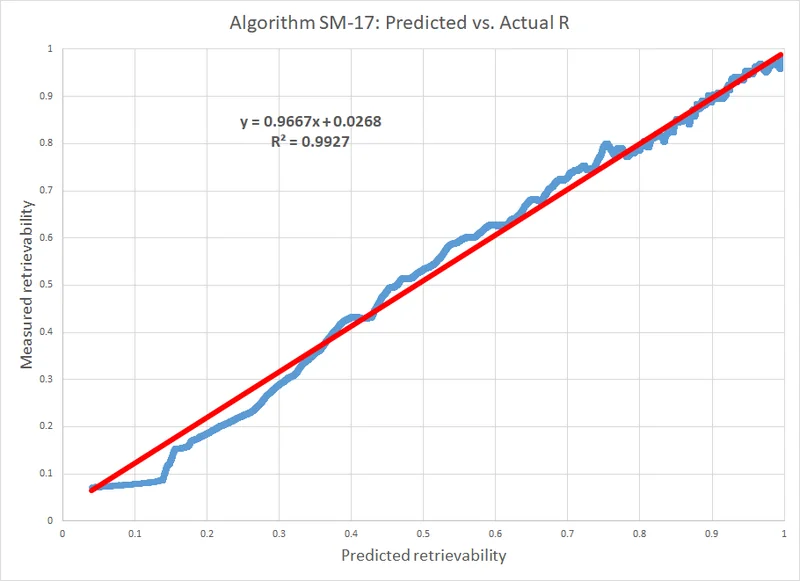
请注意,Wozniak 使用了不同的方法来绘制他的图,他并没有使用分组。而且,他称 R 为「可提取性」,而不是「回忆概率」,但这无关紧要。红线只是一个趋势线,并不代表「完美算法」。尽管在这种情况下,二者非常接近。
我听说很多人要求对 FSRS 和 Anki 进行随机对照试验(RCTs)。虽然随机对照试验非常适合药物和临床治疗的测试,但在间隔重复的背景下,它们并不是必需的。首先,要执行这样的试验难度极大,因为你需要组织数百乃至数千人参加。如果没有真正的研究机构协助,祝你好运。其次,这并不是适合这项工作的正确工具。这就像用冰淇淋勺子吃披萨。

你不需要数千人;相反,你需要数千条复习记录。如果你的集合至少有一千条复习记录(1000 是最基本的数量),那么你应该能够得到一个不错的 MAE 估计。这一过程在优化器中会自动完成;优化完成后,你可以在优化器的 4.2 节查看自己的校准图。
我们决定比较 5 种算法:FSRS v4、FSRS v3、LSTM、SM2(Anki 基于该算法)以及 Memrise 的「算法」(我简称其为 Memrise)。
Sherlock 实现了一个基于 LSTM 的算法(长短期记忆),这是一种常用于时间序列预测的神经网络,如预测股市价格、语音识别、视频处理等;实现的版本包含 489 个参数。实际上,你不能真正地在实践中使用它;它纯粹是为了基准测试而实现的。
下面的表格基于 FSRS wiki 的这一页。所有 5 种算法都在大约包含三百万条复习记录的 59 个集合上运行,结果基于每个集合中的复习记录数进行加权平均。
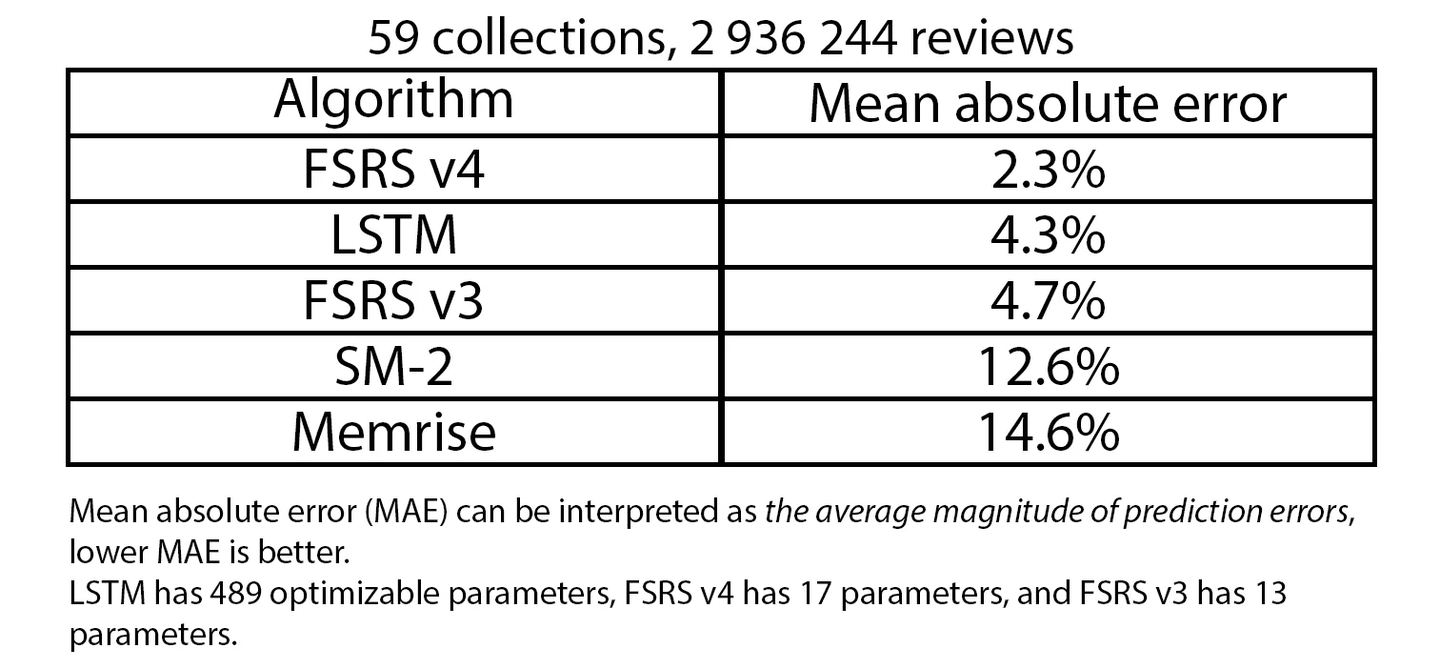
我很惊讶 SM-2 的表现只略微超过了 Memrise。至少 SM2 尝试自适应,而 Memrise 甚至没有尝试,只是给每个人相同的间隔。而且,FSRS v4 只有 17 个参数,但其表现却超过了具有 489 个参数的神经网络。尽管这里值得一提的是,我们正在比较一个经过精细调整的单一目的算法和一个根本没有经过精细调整的通用算法。
虽然还有改进的空间,但是很明显 FSRS v4 是所有选项中最好的。基于神经网络的算法不一定更准确。这并非不可能,但你显然无法用开箱即用的设置超越 FSRS,所以在特征工程和神经网络的架构上,你必须聪明点。那些不使用机器学习的算法,如 SM2 和 Memrise,在准确度上根本无法与使用机器学习的算法抗衡,它们唯一的优势是简单。说点题外话,Dekki 是一个使用神经网络的机器学习项目,尽管我告诉开发者参与我们的「算法竞赛」会很酷,但他要么是对此不感兴趣,要么只是忘记了。
PS:如果你目前正在使用 FSRS v3,我建议你切换到 v4 版本。如何安装,请在此处查阅。
@Thoughts Memo 汉化组译制
感谢主要译者 GPT-4,校对 Jarrett Ye
原文:FSRS explained, part 2: Accuracy : Anki (reddit.com)
作者:ClarityInMadness
专栏:AnkiX高考
围绕「Anki」和高考备考,面向广大高中生,交流作者们对「Anki」和高考的认识与见解,分享同学们整理的高中知识牌组,带每个考生高效学习!