

2019 年,我曾论证过「书本不起作用」[1],理由是人们似乎会遗忘他们所阅读的绝大部分内容。难怪大家觉得学习复杂的知识非常困难。但在过去几个月里,我开始认为[2],在很多情况下,我们以为的「遗忘」,实际上往往是「一开始就没有真正理解」。当人们发现自己无法利用所学知识时,他们通常无法分辨自己是真的忘记了,还是根本就没理解过。如果真是这样,而我想要帮助人们更有效地学习复杂的知识,我就需要从遗忘的上游着手。这并不是说要忽视记忆——事实上,我们稍后还会讨论到,理解在很大程度上依赖记忆——但这意味着我们需要在更宏观的层面上考虑记忆。
所以,「理解」究竟是什么?当我们与(比如说)一篇文章进行交互时,产生理解的机制是怎样的?如果有人没能理解,那么到底是什么环节没有做好?又有哪些因素会影响这些过程呢?知道这些因素后,我们应该如何干预?在这封信里,我会对这些问题的认识做一个简单的分享。
我们是如何理解文字解释的呢?
「理解」究竟是什么呢?学习科学家从现实中的宏观行为开始讨论:「理解就是能够明智且有效地在各种上下文中使用——迁移——我们所学到的知识,在现实任务和环境中,能够有效地运用知识和技能。」[1] 他们由此向细微处钻研,探究哪些学习活动更可能产生这种宏观能力。同时,认知心理学家则从大脑的底层机制——感知,注意力,加工,记忆——开始探索,试图理解更宏观且更为复杂的现象。对于他们来说,「理解」并不是单一概念,而指代了许多机制协作的过程,是一个不准确的术语。
对于像我一样的设计师来说,问题在于这两个学科的发现还没有交汇。对「理解」的深入理解,有助于我们开发新方法来增进理解。没有这种理解,我们只能分别从两边尽可能探索,像钟乳石和石笋一样;对于中间的空白,我们要用想象力、直觉和猜测来弥补。
首先,我们要确定一下所探讨的理解是哪种类型。让我们专注于理解一篇文字解释。比如说你在读一篇关于人体循环系统的解释。最后,你可能想「理解循环系统」,但此刻我们只把目标定为「理解关于循环系统的一篇解释」。这个门槛虽然较低,但在很多情况下,这似乎就是制约我们的瓶颈。
具体来说,你得搞清楚作者句子的意思;你得能解释文本中描述和暗示的特性和关系;你得能基于这些细节和已有的相关知识,做出简单的推理。至于熟练度或长期记忆,我们暂不考虑。让我们假设你刚读完这篇解释,而且回答得慢点也没关系。
认知心理学家把这种理解称为「文本理解」。Walter Kintsch 提出了广受研究的构建-整合模型,该模型将这个过程分为两部分[2]。首先,你需要对页面上的文本构建内在表征:阅读单词,解析句法,理解名词的指代和动词的歧义等等。Kintsch 将这种心理表征称为文本基础。如果我们暂不考虑遗忘,那么,有了完整的文本基础,你就可以回答只需在文字上摆弄作者解释的问题了。如果你有一个关于「Bargleborp 如果不加控制会引发 hixitak」的解释的文本基础,那你就能回答「没人注意到 Bob 的 bargleborp ,直到为时已晚。会发生什么?」(「Hixitak。」)你知道这些词语是怎么说的,但对他们真正想表达的意思,你还是一知半解。
然后,你需要通过整合来理解含义,形成文章里没有直接描述的联系。你会把文章里的词语和观点,和你自己已经知道的东西联系起来,同时你会推断出作者意有所指但没有成文的细节。Kintsch 将将这种完整而联系丰富的心理表征称为情境模型。
比如,在一篇关于循环系统的解释中,假设你读到这么一段文字:「如果婴儿存在心房间隔缺损,血液无法通过肺部充分排出二氧化碳。因此,血液看起来呈紫色。」[3] 你光有这些句子的文本基础,是不足以理解这个解释的。血液为何呈现紫色?要回答这个问题,你需要将这一问题关联到你对血液流动的已有知识,来赋予它们意义,就像下图展示的那样:
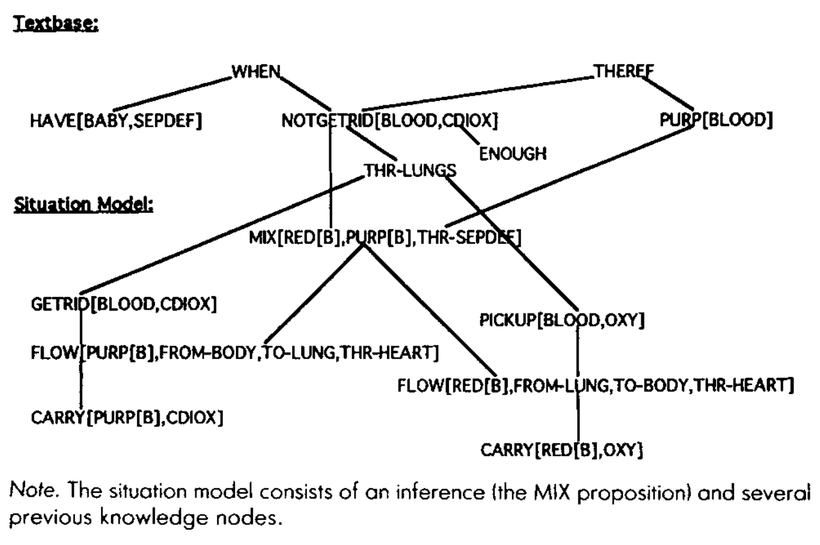
我们可以使用这个模型,为有关文本理解和学习的常见直觉,增添一点机械论的色彩:
更好的整合能够产生更好的记忆。文本基础和情境模型中的信息,都将储存在我们的长期记忆中。然而,回忆和记忆巩固在于关联。如果新的文本信息只能通过单一线索连接到你已有的知识,那你可能会很难回忆起来,而且在之后的认知过程中,这些信息也不太可能得到强化。根据 Kintsch 的研究,为了长久掌握知识,要将新的文本信息和你原有的知识钩连起来,形成更丰富的情境模型。钩连越多,记忆效果越好。学习文本越深入,或者既有知识越丰富,构建的联系也就更多。这也验证了我们的直觉,即在我们已经精通的领域,更容易记住新的信息。
更好的记忆能带来更好的整合。如同我们之前所见,文本基础中信息点之间的联系和推理,往往需要「通过」你已有知识节点间的路径。这暗示着记忆强化在机制中的角色:你无法通过你已经忘记的节点。如果第二章的内容依赖于第一章不太熟悉的信息,我们就需要确保在你需要理解第二章的内容之前,你能够记住第一章的信息。
「用你自己的话说出来。」这是给学生的常见建议。然而,我惊讶地发现,根据 Kintsch 的模型,在学习过程中,如果你不用自己的话来阐述文本(即使这可能在你的潜意识里进行),你基本学不到任何东西。想要形成一个整合良好的情境模型,你得把作者用词所指的概念,跟你已有知识中的概念关联起来。也就是说,你在此过程中处理的是概念,而不是语词。比如,一个作者说的「通过肺部排出二氧化碳」,另一个作者说的「呼出二氧化碳」,你通常需要把这两个短语解读为同一概念。否则你就无法把这两篇文本所形成的情境模型联系起来。
注意力影响理解程度。有一种显然的失败经历大家都很熟悉:有时候,某句话你看得太快了,甚至都没来得及解读它里面的词。或者,你读了句子里的词,但注意力太分散,无法解析其中复杂的句子结构。在这些情况下,你根本无法对文本形成文本理解。你可能只是处理了文本的「表面特征」,例如注意到这部分文字中出现了某个关键词,但你无法利用这些信息,即使是直接照搬都不行。文本的选取会影响这里的行为:在 Kintsch 的一个实验中,如果文本太啰嗦或太熟悉,参与者们会依赖他们已有的情境模型,并形成有损的文本基础表征。
整合程度控制知识迁移。如果你发现你能复述作者的话,但在用你自己的话阐述这些观点,或实践这些观点时,却颇感吃力,那么这说明你的情境模型过于依赖于你的文本基础。也就是说,构成你的心理表征的,主要是与作者的词汇和短语对应的节点。所以,当接收到与文本形状不完全一样的线索时,你无法将它们和你已经学到的东西联系起来。你需要多与文本打交道,把它与你已知的知识联系起来,提出问题,进行推理。
自我解释有助深化理解
Kintsch 的试验几乎没有涉及注意力、自我调控和反思等因素。他的研究通常会设定一个理想情况——学习者根据自身的既有知识,尽可能从文本中建立最优秀的模型,然后去探究这些模型的性质。但在实际中,我认为理解的问题往往源自读者没有根据自己已有的知识,构建出最好的理解模型。这种情况往往是合理的:仔细阅读需要时间和精力,而大部分书籍并不值得花费无尽的时间。理想的读者会根据自身的目标,构建出够用的理解程度。那么,我的「增强」工作,就是去拓宽这个帕累托最优边界。但实际上,正如我们在上月的文章中[2]所讨论的,读者们往往未能如预期般理解文本。他们未能察觉到对概念及其解释理解中的重大漏洞。
那么,我们应该如何应对呢?我们希望能辅助读者,比如帮他们建立联系、监控自我理解、修正理解中的缺漏或误区等等。最被广泛研究的干预方式就是自我解释。Michelene Chi 和她的同事要求一组学生在阅读时大声解释文本,控制组则要重读文章,以保持总学习时间一致。结果显示,解释组在后续测试中的表现优于控制组,尤其在需要进行陌生推理而更具挑战的迁移问题中。
在解释组中,有些人天生就比别人更能说会道。有趣的是,这些「高解释水平者」通常会学到更多东西,即使我们控制了初始的知识水平和口头表达能力差异。在开卷考试中,「高解释水平者」几乎从不参考材料,而「低解释水平者」(以及控制组)则经常参考材料,这暗示着「高解释水平者」更能把学到的东西内化。值得注意的是,这些组别的自我解释方式也不一样。「高解释水平者」的解释,更有可能在材料涉及的不同主题之间建立联系,而不只是局限于某个主题。他们在解释中会做出更多推理,这可能解释为什么他们在后续测试中能更好解释材料中隐含的细节。
Chi 和她的团队提出,由于「低解释水平者」和「高解释水平者」在预先测试中得分相同,他们之间的差异可能源于自我解释的技巧和习惯。例如,「高解释水平者」可能已经习惯于在主题间建立联系,他们也更倾向于相信多解释一些总是好的。这种看法催生了一系列关于如何教学生有效进行自我解释的研究。
教授这类学习策略后,人们或许更可能理解概念解释。就我个人而言,随着阅读技巧的丰富,我成为了更高效的学习者。然而,我觉得这还不够。大约十年前,我就阅读了这些关于自我解释的论文。但我并没有切实去实施——有时候是因为感觉这像个苦力活,有时候只是因为我想都没想到。我总是很容易陷入「仅仅阅读」的模式,自我安慰说我已经理解得很好了。但往往,我并没有真正搞懂!
一些原型
我对此的理解是,文本解释这种媒介并没有真正鼓励我需要的那种方式。文本解释的默认行为就是不断阅读。文本不会帮助我检查理解程度,或完成恰当的推理;我需要时刻留意自己,何时开始感到困惑。即使我花更多的时间去深入理解一些事物,文本也不会有所反馈。反观对话就不同了。在谈话中,对话的伙伴会留意我是否感到困惑。他们会提出一些关于他们的解释的问题,并解答我们的问题。如果我努力理解,他们会给我鼓励。

过去这一年,我展示过很多文本+链接记忆系统的结合媒介,现在我发现它们更接近于我所期望的行为方式。我常常用一个基本的系统阅读,这个系统里可以高亮任何文字,并为其添加相关的记忆卡片。这些卡片会悬浮在相应文字旁边,相应的文字部分则会加深颜色,表明有卡片存在。这种空间标记使我一目了然,知道我在哪些地方投入了大量精力,哪些地方还没看。而有趣的是,这些颜色看起来非常舒心!把侧边栏「塞满」,或者把所有「精华」部分「涂满」颜色,我会有种莫名的满足感。当然,这有可能会带来误导,高亮文字似乎是很有帮助的,但不应该把整篇文章都涂满高亮。然而,我仍想强调与传统文字的区别:这种媒介自然而然地让我注意到哪些地方我「深入」了解,鼓励我更进一步。相比阅读普通的书本,这种媒介的「默认路径」是更深入的。
写记忆卡片比撰写自我解释难得多。这种额外的困难可能让理解更深刻,但我感觉很多困难其实是无用功,因为写卡片实际上是将解释改写为产生目标提取的任务,而这个过程有很多特殊的要求。因此,我从文本+有链接记忆系统媒介中获得启发,构建了一个阅读体验原型,其中以类似的方式在「被动地奖励」自我解释。阅读时,我可以高亮重要的段落,并用自己的话解释这些文字,而且可以在适当的时候添加颜色和练习。如果我愿意,我甚至可以用口头解释并使用语音输入。这些段落的文字会被着色,让我清楚哪些部分我已经解释过了。另外,我把解释发送给 GPT-4,并且在我出错或者忽略重要的东西时,系统会显示反馈。
我录了个不到一分钟的小短片,展示了我在一份线性代数教材中编写「成功」和「错误」的自我解释。(抱歉,Patreon 不支持内嵌视频。)
在这个主题上迭代了几轮后,我做出的原型还挺有意思,不过我并不打算就此深入下去。好的一面是,如果我用这个工具看书,感觉自己对材料的理解很不错。但这个过程也相当不爽。很多时候,把作者的观点打成字(或者念出来),感觉就是无聊的繁琐活,不管它有没有助于我理解。有趣的是,我并不总是这么想:当我对作者的观点一头雾水时,这个练习自然就变得有趣了。
写记忆卡片也许困难得多,但跟书面/口头的自我解释相比,我觉得这个活动更有价值。我想那是因为记忆卡片并不是阅完既弃的边角料。我写它们不是为了写而写,而是为了将其加入记忆练习。当我读完书后,这些卡片还会跟着我,而我能确信我能长久记住这些卡片中的细节。
所以,我尝试了另一种方式,将自我解释重构为做笔记。如果我在阅读过程中写下的所有自我解释,都会被一个 Markdown 文件所收集,存入我的笔记系统呢?那么,我并不是为了写而写,我还能将它们收入笔记,随时查阅。但是,遗憾的是,我的实验结果并不如人意。我最终得到的笔记文件,只是用我自己的话对原文的总结,不成体系而又冗长难读。但它并不是当我想对原文做些有用的笔记时,会写的那种总结。我并不会想去编写这种笔记。
然而,我觉得我讨论过的两种办法是有价值的。首先,阅读媒介应该能够自然地向你「提示」专家策略。其次,完成那些「额外」的阅读活动后,其结果应该能让你由衷感觉有价值,而非似乎有用的繁琐工作。
这与我对自己在这个领域所处的生态位的思考有关:我非常在意阅读的感觉如何。教育心理学文献充斥着各种干预措施和阅读增强系统,但这些东西对于读者来说体验都很糟糕,而研究人员似乎对此毫不关心。我希望的是,如果我能深入了解这些系统背后的原则,我就可以重新组织这些原则,得到令人愉快且增强人们能力的系统。
————————
[1] Grant Wiggins and Jay McTighe, Understanding by Design (2005), page 7.
[2] 见 Kintsch’s monograph, Comprehension: A Paradigm for Cognition (1998). 我在这可能有些过于简化:构建不仅限于文本基础,整合也不仅限于情境模型;要形成连贯的文本基础,整合也是需要的(例如,厘清含糊的理解)。但对我们的目标来说,这样简化就足够了。
[3] 这个例子取自 Kintsch, W. (1994). Text comprehension, memory, and learning. American Psychologist, 49(4), 294–303. 遗憾的是,我认为这个例子可能对血液流动有些误解:据我理解,流向肺部的血液应该是深红色的,而非紫色,这是因为这些血液氧气含量较低,而不是因为其中含有二氧化碳。但这个图很不错,所以我们用来讨论。
Thoughts Memo汉化组译制
感谢主要译者 GPT-4、JarrettYe,校对 Shom
原文:Initial experiments in self-explanation support
作者:Andy Matuschak
参考
1. 为什么书本不起作用? ./390507468.html2. 阅读理解与记忆系统 ./653174197.html