
介绍
为了促进记忆领域研究的发展,我与 Anki 的开发者 Damien Elmes 合作,发布了原用于 FSRS Benchmark 项目的数据集。现在可以在 Hugging Face 上下载该数据集:
open-spaced-repetition/FSRS-Anki-20k · Datasets at Hugging Face
介绍
FSRS-Anki-20k 数据集包含 2 万份 Anki 用户的复习日志集合文件。这些数据是在复习超过 5000 次的用户中随机挑选的。总计可用的复习日志有 15 亿条。
这份数据集中一共包含两种数据格式:原始 revlog 文件,和预处理后的 csv 文件。前者大小约 50GB,后者约 20GB。
数据格式
Revlog
请参见 stats.proto 中的定义。对于命名不清晰的字段,请参考 Anki 数据库结构文档。
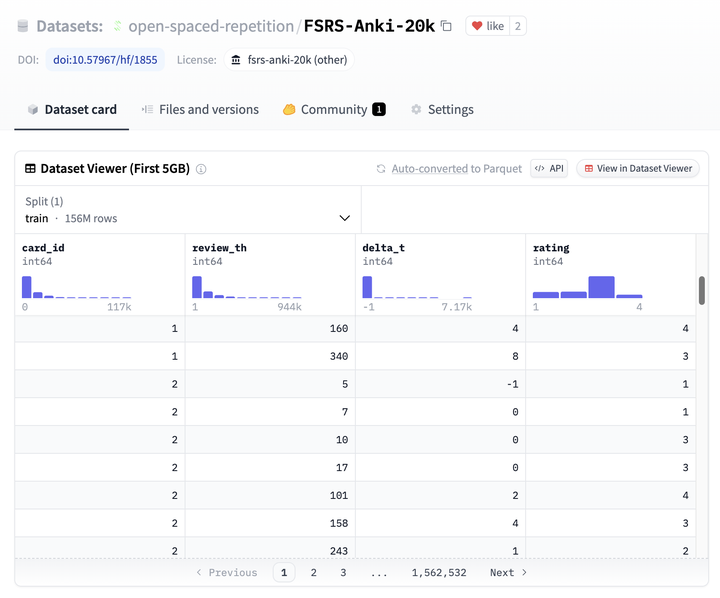
Dataset
数据集的列包括:
- card_id: 每张抽认卡的唯一标识。
- review_th: 这次复习是当前用户从使用 Anki 以来的第几次复习。
- delta_t: 这次复习距离上一次用户复习这张卡片过去的天数。-1 表示这是这张卡片的第一次复习。
- rating: 用户对这次复习的打分。1: again, 2: hard, 3: good, 4: easy。其中只有 again 表示回忆失败,其他分数都代表回忆成功。
预处理过程
- 从 revlog 文件中读取 revlog 条目。
- 过滤掉用户在不影响复习安排的筛选牌组中的复习。
- 过滤掉由手动重排操作产生的复习。
- 对于每一张卡片,如果卡片在复习后又进入新学状态,则过滤掉新学状态前的所有复习。
- 计算每张卡片中每次复习之间的时间间隔 delta_t、复习序数 review_th,以及用序数压缩原始的 card_id。
- 将预处理好的结果保存为 csv 文件。