

译者:FSRS 是基于墨墨背单词的论文《优化间隔重复调度的随机最短路径算法 | 墨墨百科》衍生出的开源项目。
本文取代了我之前关于基准测试的旧帖,并已将其加入到我关于 FSRS 的文章合集中。你无需阅读旧帖,我也不会再链接到那篇文章。
首先,任何「诚实」的间隔重复算法都必须能够预测在特定时间点回忆一张卡片的概率,这取决于卡片的复习历史。在下文中,我会用 R 来指代这个概率。
如果一个「不诚实」的算法不计算概率,只输出一个时间间隔,我们仍然可以在某些假设下将这个间隔转换为概率。虽然不是最理想,但总好过没有,因为这至少允许我们进行某种比较。这就是我们对 SM-2 算法所做的,它是基准测试中唯一的「不诚实」算法。我们决定不加入 Memrise,因为我们不确定所需的假设是否适用于将其间隔转换为概率。不过,即使加入了,它的表现也不会太好,它的灵活性极差,几乎不配被称为算法。
一旦我们有了能预测 R 的算法,我们就可以在一些用户的复习历史上运行它,看看预测的 R 与实测的 R 偏差有多大。如果我们使用数亿次复习来做这种测试,我们将能很好地了解哪种算法的平均表现更佳。RMSE(均方根误差)可以理解为「预测与实测回忆概率之间的平均差异」。它与你熟悉的算术平均值不完全相同。MAE(平均绝对误差)有一些不理想的特性,因此选择使用 RMSE。RMSE 总是大于或等于 MAE。
为了防止作弊,RMSE 的计算方法最近已经重新设计。如果你想了解这些数学细节,可以阅读我和 LMSherlock 撰写的这篇文章。简而言之:有一种特定的方法可以降低 RMSE,而实际上并没有提高算法预测R的能力,这就是为什么我们改变了计算方法。新方法是我们自己发明的,你在任何论文中都找不到。Anki 的最新版本 24.04 也采用了这种新方法。
现在,让我们介绍一下参赛者。这次的名单比之前要长得多。
算法介绍
FSRS 系列
(1)FSRS v3。这是第一个真正被人们使用的 FSRS 版本,发布于 2022 年 10 月。虽然它不算糟糕,但存在一些问题。我、LMSherlock 和其他几位用户提出并测试了许多改进算法的想法(只有少数被证实有效)。
(2)FSRS v4。该版本于 2023 年 7 月发布,到了 11 月初,它被整合进了 Anki。相比 v3,这是一个显著的进步。
(3)FSRS-4.5。这是 FSRS v4 的一个略有改进的版本,遗忘曲线的形状发生了变化。现在,它被用于 Anki 的所有最新版本:桌面版、AnkiDroid、AnkiMobile 和 AnkiWeb。
通用深度学习算法系列
(4)Transformer。这种神经网络架构近年来因其在自然语言处理中的卓越性能而流行起来。ChatGPT 采用了这种架构。
(5)GRU(门控循环单元)。这种神经网络架构通常用于时间序列分析,如预测股市趋势或识别人类语音。最初,我们使用了一种更复杂的架构,名为 LSTM,但 GRU 在参数更少的情况下表现更佳。
下面简单解释一下 GRU 和 Transformer 之间的区别。

我将用自然语言处理的例子来说明,因为这更直观。
GRU 从左到右「阅读」句子,并根据单词的最近出现时间,对每个单词给予一定程度的「注意力」(颜色越深表示关注越多)。到了最后一个词时,它可能已经忘记了第一个词。当然,这是一个夸张的例子,但它确实展示了一个真实的问题。
Transformer 则是一次性「阅读」整个句子,所有词汇并行处理,而不是顺序处理。这使得 Transformer 能够对句中任何位置的任何单词给予任意程度的「注意力」。ChatGPT 就是基于这种架构的。
DASH 系列
(6)DASH(难度、能力与学习历史)。这是一个基于神经科学的真正的人类记忆模型。嗯,可以这么说。但它的问题在于,遗忘曲线看起来像一个台阶,也就是阶梯函数。
(7)DASH[MCM]。这是一个混合模型,解决了 DASH 遗忘曲线的一些问题。
(8)DASH[ACT-R]。另一个混合模型,最终实现了一个外观优美的遗忘曲线。
这里还有一篇相关的论文。抱歉,没有通俗解释。
其他算法
(9)ACT-R(Adaptive Control of Thought - Rational,在某些论文中也见过用 Character 替代 Control)。这是一个人类记忆模型,。它有一个非常奇怪的假设:无论你是否成功回忆起材料,并不影响间隔效应的大小,只有间隔长度重要。简单来说,这个算法不区分「重来」、「困难」、「良好」、「简单」。
(10)HLR(Half-Life Regression)。这是由 Duolingo 为 Duolingo 开发的算法。HLR 中的记忆半衰期与 FSRS 中的记忆稳定性在概念上非常相似,但其计算公式过于简化。
(11)SM-2。这是一个超过 35 年历史的算法,仍被 Anki、Mnemosyne 及可能的其他应用使用。它的主要优点是简单。请注意,在我们的基准测试中,它是按照最初的设计实现的。这不是 Anki 版的 SM-2,而是原版 SM-2。
我们原本以为 SuperMemo API 会在今年发布,这将让 LMSherlock 能够在 Anki 数据上对 SuperMemo 进行基准测试,虽然需要付费。但看起来 SuperMemo World 的 CEO 改变了主意。我们可能永远也不会知道 FSRS 还是 SM-17/18/未来某个版本哪个更好。所以作为安慰奖,我们加入了某种类似于 SM-17 的东西。
(12)NN-17。这是一个神经网络对 SM-17 的近似。SuperMemo 关于 SM-17 的维基页面上的信息乍看之下非常详尽,实际上却隐藏了实施 SM-17 所必需的所有重要细节。它告诉你算法在做什么,却没有说明怎么做。我们的近似依赖于关于 SM-17 公式的有限信息,同时利用神经网络来填补任何缺口。
详细介绍
这里有一个图解(好吧,是 7 个图解加上一个图表),它将帮助你理解这些算法在根本上有何不同。别担心,没有复杂的数学。
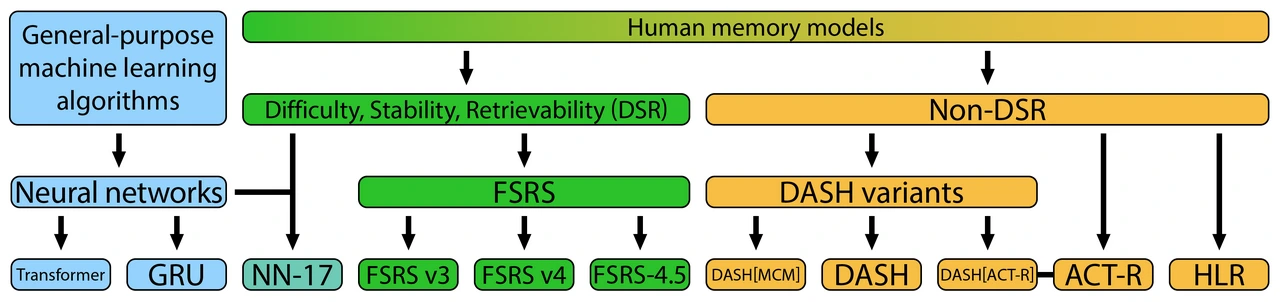

为了计算下一个间隔的长度,FSRS(间隔重复算法)需要前一个间隔的长度、评分(重来/困难/良好/简单)以及其自身之前的状态,后者用三个数字表示:难度、稳定性和可提取性(DSR)。
请注意,水平箭头始终指向右侧,表明过去的状态可以影响未来的状态,但未来的状态无法影响过去的状态。
SM-17/18 算法具有相同的架构,但增加了一个额外的状态变量:记忆失误次数。
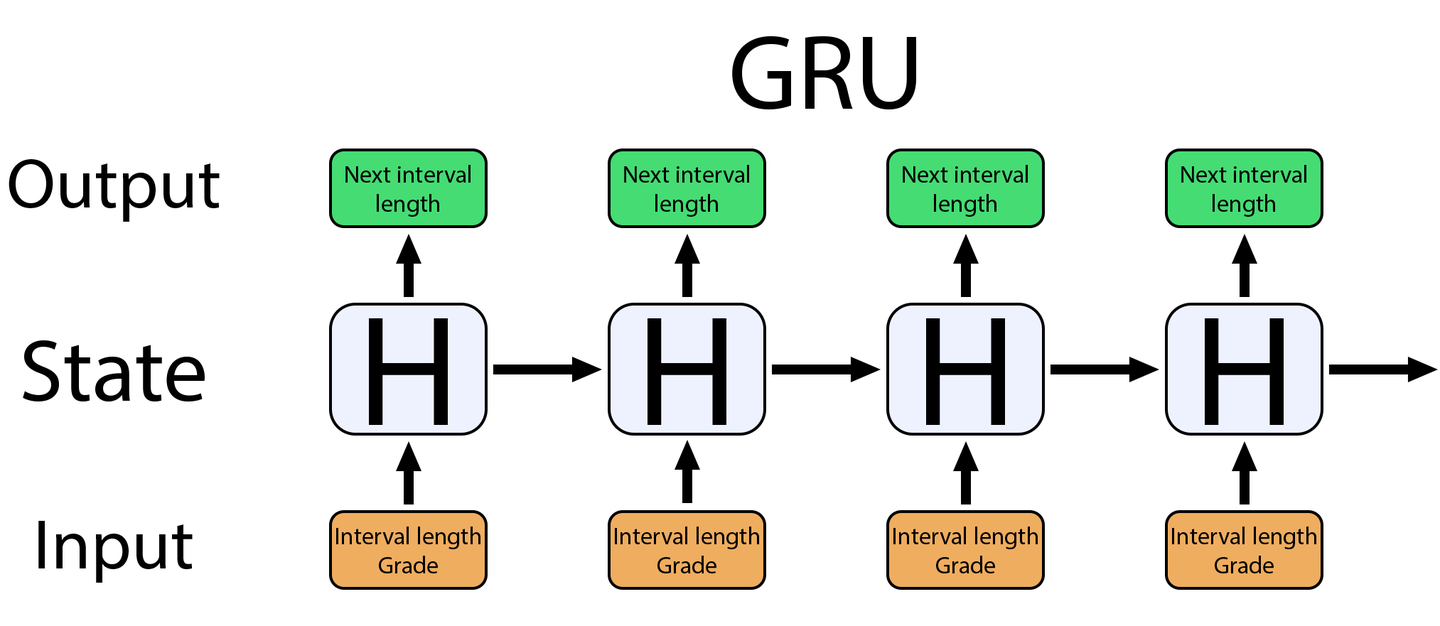
GRU 也是一种循环算法,与 FSRS 类似,尽管数学公式完全不同。它的状态用 2 个数字表示(隐藏层大小为 2)。

HLR 技术上也是一种循环算法,但相对较为原始。复习的顺序不重要,因为它只需要关于整个复习历史的汇总统计数据。无论你如何重新排列复习,总的复习次数、通过的复习和未通过的复习(失误)的数量都将保持不变。

为了计算下一个间隔的长度,NN-17 需要前一个间隔的长度、评分(重来/困难/良好/简单)以及它自己之前的状态。这个状态用四个数字表示:难度、稳定性、可提取性和失误次数。
其目标并非开发出最终的算法,而是通过使用已知的公式并用神经网络替代未知的公式,来模仿 SM-17。
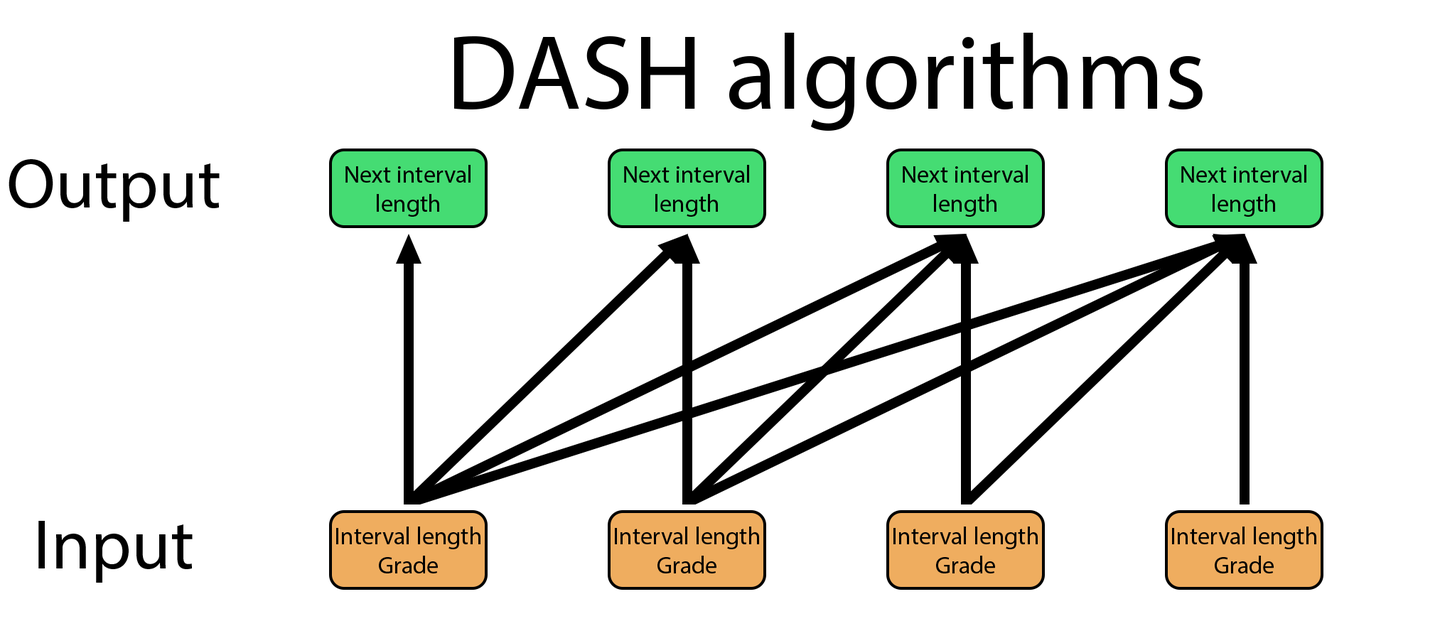
DASH、DASH[MCM] 和 DASH[ACT-R] 没有状态变量,它们不像 SM-17/18 或 FSRS 那样按顺序处理复习。它们更像 Transformer 模型:必须处理所有过去的复习,才能计算出下一个间隔的长度。这使得当复习数量很大时,它们的处理速度比 FSRS 慢得多。在 FSRS 中,处理每次复习所需的时间是恒定的。如果一张卡片有 100 次复习,处理第一次复习的时间和处理第 100 次复习的时间是一样的。而在 DASH 中,处理单次复习的时间取决于过去的复习数量。因此,处理第 100 次复习的时间将比第一次复习长得多。
此外,尽管图表显示「下一个间隔长度」作为输出,但实际上,由于它们遗忘曲线的特性,使用 DASH 算法计算下一个间隔将非常困难。对于 FSRS 和 HLR,计算与特定间隔长度相对应的回忆概率,以及计算与特定回忆概率相对应的间隔长度都同样容易,但使用 DASH 算法则不然。
*如果我要非常精确地说,在 FSRS 中,处理第一次复习实际上比处理后续复习所需的时间略微短一些,因为第一次复习的数学计算更简单。我们谈论的是以微秒计的时间差异。

ACT-R 与 DASH 算法类似,这就是为什么存在一个混合模型 DASH[ACT-R]:它们可以有意义地结合在一起。然而,ACT-R 并不考虑评分。
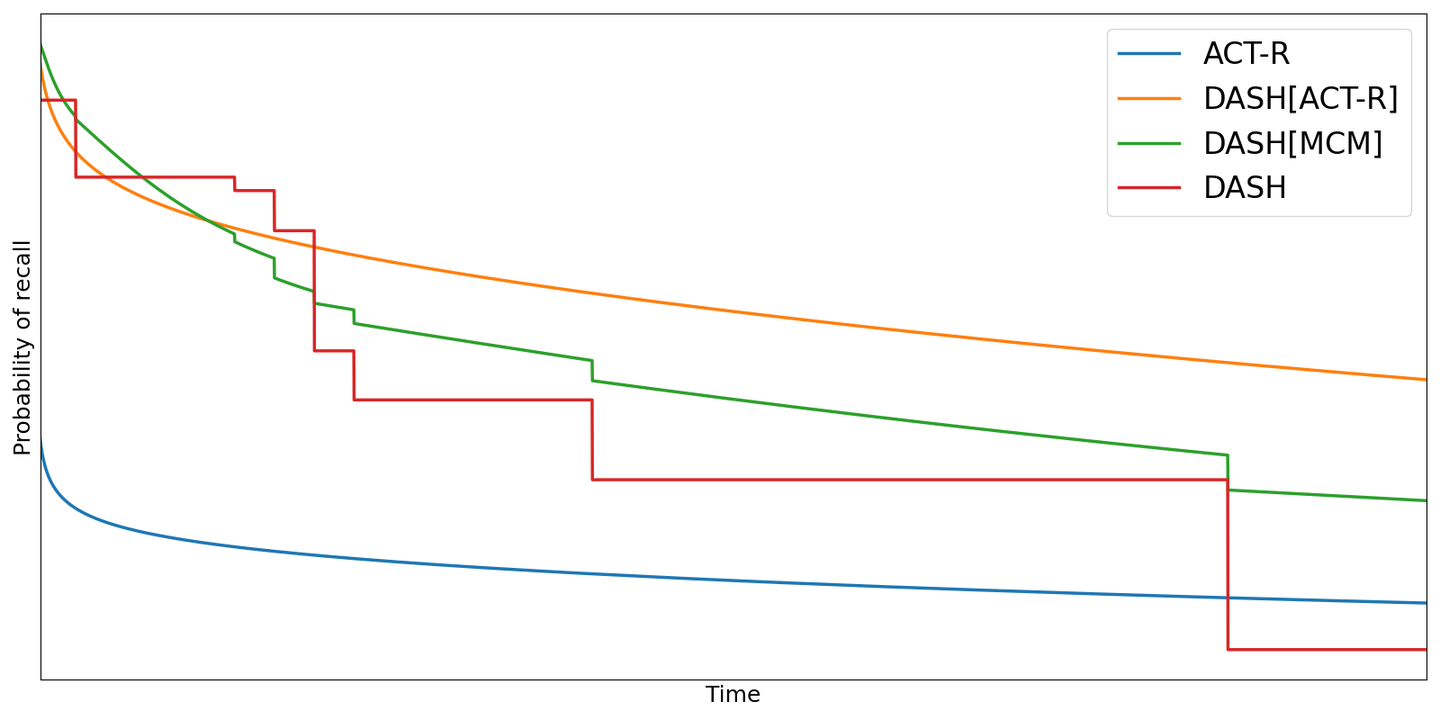
这些曲线是使用默认参数绘制的,这些参数是通过在 2 万个 Anki 用户的集合上运行每个算法获得的。因此,你看到的是「平均」或「典型」的曲线。
DASH 的曲线比较奇怪,不平滑,这与我们的直觉和常识相悖。DASH[MCM] 试图使其平滑,但你可以看到它并不完美。DASH[ACT-R] 则实现了平滑的曲线。
测试结果
现在是展示基准测试结果的时候了。下面的表格显示了每个算法的平均 RMSE(均方根误差):
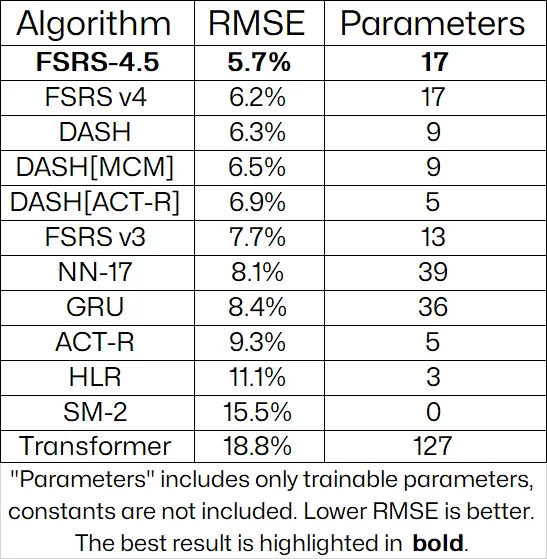
我没有包括置信区间,因为这会使表格过于复杂。如果你想了解更多细节,比如置信区间和 p 值,可以访问该基准测试的 Github 仓库。
平均值是按每个用户收集的复习数量加权的,这意味着复习更多的用户对平均值的影响更大。例如,如果某人有 10 万条复习,他们将对平均值的影响是只有 1 千条复习的用户的 100 倍。这个基准测试基于 19,993 个集合和 7.28 亿条复习,不包括天内的多次复习;每个算法每天只使用一条复习。表格还显示了每个算法的可优化参数数量。
这里有一个条形图:
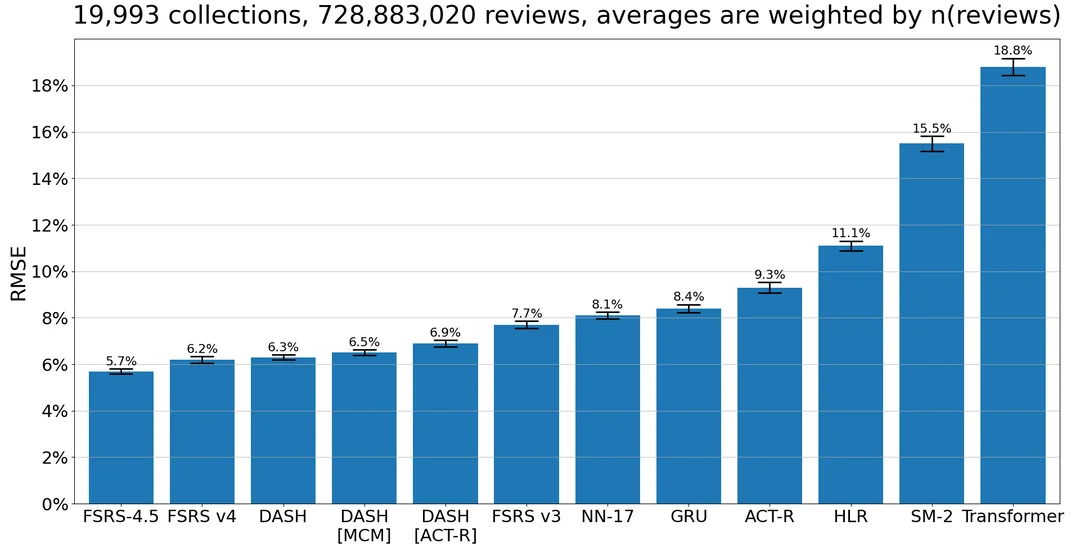
黑色条形代表 99% 的置信区间,显示了这些平均值周围的不确定性水平。条形越高,不确定性越大。
不出所料,HLR 表现不佳。公平地说,HLR 有几种变体,其他变体使用了只有 Duolingo 拥有的信息(词元标签),这些变体无法在此数据集上使用。也许这些变体会更精确一些。但正如我之前提到的,HLR 使用了一种非常原始的公式来计算记忆半衰期。对于 HLR 来说,无论你是昨天选择了「重来」今天选择了「良好」,还是反过来,它都会预测出相同的记忆半衰期。
Transformer 似乎不太适合这项任务,因为它需要的参数远比 GRU 或 NN-17 多,但表现却更差。尽管可能有某些修改过的 Transformer 架构更适合间隔重复学习。此外,LMSherlock 对 Transformer 放弃得也许太快了,因此我们没有对其进行细致调整。神经网络的问题在于,参数/层的数量选择是任意的。此基准测试中的其他模型在参数数量上有限制。
FSRS-4.5 表现优于 NN-17 并不是 FSRS 优于 SM-17 的决定性证据。加入 NN-17 只是因为看到类似于 SM-17 的东西会表现如何很有趣。不幸的是,FSRS 和 SuperMemo 算法之间的竞争可能永远不会有结论。这需要成百上千的 SuperMemo 用户分享他们的数据,或者 SuperMemo 的开发者提供一个 API;这两种情况都不太可能发生。
注意事项
我们无法对诸如 SuperMemo 算法这类专有算法进行基准测试。
有些算法需要额外的特征,例如结合了 Duolingo 的词元标签的 HLR 或是 KAR3L。据相关论文描述,KAR3L 不仅考虑间隔长度和评分,还考虑了卡片的文本内容,并且略微优于 FSRS v4(尽管尚不清楚是否优于 FSRS-4.5)。在提供必要信息的情况下,这类算法可能比 FSRS 更准确,但我们的数据集无法对其进行基准测试。由于没有其他特征可用,只有使用间隔长度和评分的算法可以进行基准测试。
参考的学术论文
- https://scholar.colorado.edu/concern/graduate_thesis_or_dissertations/zp38wc97m (DASH 首次提及于第68页)
- https://www.politesi.polimi.it/retrieve/b39227dd-0963-40f2-a44b-624f205cb224/2022_4_Randazzo_01.pdf
- http://act-r.psy.cmu.edu/wordpress/wp-content/themes/ACT-R/workshops/2003/proceedings/46.pdf
- https://github.com/duolingo/halflife-regression/blob/master/settles.acl16.pdf
- https://arxiv.org/pdf/2402.12291.pdf
参考的非学术论文
- https://github.com/open-spaced-repetition/srs-benchmark?tab=readme-ov-file#srs-benchmark
- https://github.com/open-spaced-repetition/fsrs4anki/wiki/The-Metric
- https://supermemo.guru/wiki/Algorithm_SM-17
Thoughts Memo 汉化组译制
感谢主要译者 GPT-4,校对 Jarrett Ye
原文:FSRS is one of the most accurate spaced repetition algorithms in the world (updated benchmark)
作者:ClarityInMadness
专栏:AnkiX高考
围绕「Anki」和高考备考,面向广大高中生,交流作者们对「Anki」和高考的认识与见解,分享同学们整理的高中知识牌组,带每个考生高效学习!