

上一章:15 间隔重复的指数式普及
关于间隔重复研究的问题
关于间隔重复的研究历史一直受到以下因素的困扰:
- 用于代替数学优化的猜测和启发式
- 理论和实践的之间缺乏互动,科学侧重于简单的实验,实践侧重于简单的工具
- 术语不一致,导致遗忘和重新发现的循环
以上与我对失败因素的排名一致。在个人电脑和网络出现之前,人们很难逃脱这种恶性循环。
间隔重复直觉
当我们问青少年一组关于他们的记忆是如何工作的问题时,很大一部分人可以很好地猜测出重复间隔,而不做任何测量。特别是,他们经常正确地猜测第一个最佳间隔可能是 1-7 天,并且连续的间隔会增加。此外,许多人可能会猜测第二个间隔可能是一个月,而连续的间隔可能是两倍。换句话说,间隔重复是一种常见的直觉。
早期记忆研究
1885年,赫尔曼·艾宾浩斯对记忆科学做出了重大贡献。他在自己身上做了实验,提出了遗忘曲线的第一个轮廓。他也知道间隔效应。他从未研究过间隔重复。我不认为赫尔曼在我的间隔重复研究中给了我灵感,因为我根本不知道赫尔曼是谁,他完成了什么。我设计了自己的测量方法得出间隔重复。在一个无关的和被遗忘的练习中,我也产生了我自己的遗忘曲线,这可能影响了我的思考。赫尔曼的曲线要陡峭得多,实际上可能会阻碍进一步的研究(参见:艾宾浩斯遗忘曲线的错误)。我们亚当·米基维奇大学的图书馆里有大量二战前的“古代”德国文学,但我不懂德语。我是在不了解的情况下做出的努力。后来我读了关于艾宾浩斯的文章,并在我的硕士论文中提到了他的遗忘曲线。
到 1901 年,在威廉·詹姆斯所写的文章中,间隔复习的优越性显而易见,它将渗透到学习理论中,并将间隔优化作为下一步,似乎是迟早的事。但结果却并非如此。又过了 80 年。
1932 年出版的畅销书中,C.A.梅斯提出了一个简单的间隔重复时间表:1天,2天,4天,8天,等等。很好的猜测!然而,梅斯的努力被人遗忘了,因为在互联网时代到来之前,“口袋里的明信片”上的间隔重复肯定没什么吸引力。为了有一个好的开始,梅斯必须用自己的好榜样来鼓励别人。他把他关于有效学习的优秀思想描述为一种理论。他从未提及自己的经历。在那个时候推广一个新想法可能并不容易。希特勒成了新闻的主角。也许间隔重复记忆理论的进步是纳粹的又一个受害者?
20 世纪 60 年代:复兴
1966年,赫伯特·西蒙瞥见了1897年左右从艾宾浩斯的著作中衍生出来的约斯特定律。西蒙注意到,遗忘的指数性质必然存在一个记忆属性,今天我们称之为记忆稳定性。西蒙写了一篇简短的论文来解释他的想法,然后开始着手于他脑海中成百上千的其他项目。他的文章基本上被遗忘了。
大约在同一时期,罗伯特·比约克在学习和记忆方面有很多创新的想法。正如经常发生的那样,他走在了时代的前面。老师们几乎从不听心理学家的话。学生们甚至不知道他们的名字。如果比约克是一个程序员,我们可能早在十年前就有了第一个流行的间隔重复应用程序。我想他不会放过任何一个好主意。比约克似乎是第一个在一个类似于我们的记忆双变量模型的模型中明确区分检索强度和存储强度的人。
1967年,保罗·皮姆斯勒清楚地看到间隔重复可能是学习语言学习中单词对的一个伟大工具。就像 SuperMemo 一样,他在术语上遇到了困难,使用了“渐进间隔回忆”这个术语。在我们的“锯齿状遗忘曲线”挑战中,皮姆斯勒与图中所示的最早的锯齿曲线曲线最为接近:
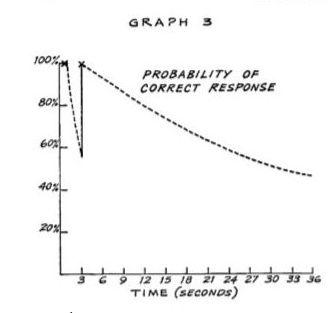
也许我们会发现这个想法的早期草图,然而,由于技术原因,打印的时间越早,图形的内容就越少,而我们今天在 Excel 中生成了大量图形。
皮姆斯勒的间隔时间延长到数小时、数分钟甚至数秒。这是直觉的反映,而不是衡量。他将他的推理从容易测量的陈述性知识(如单词对)扩展到程序性知识和声音模式识别,如学习发音。SuperMemo 解决了这个问题,它将单词对学习从发音、拼写、识别、同义词等方面分离出来。因此,在 Advanced English 中,我们从不需要减少超出用户标准启动稳定性的时间间隔,它很少下降到一天以下。由于实际原因和睡眠的作用, SuperMemo 从不使用短于 1 天的间隔。睡眠也是该算法在时间间隔长度上使用 1 天分辨率的主要原因。SuperMemo 可以让你在一天内复习很多次,但是这是一个子集复习的一部分。与梅斯和纸上的 SuperMemo(算法 SM-0)的推荐间隔不同。它们不是测量的结果,而是推测的结果,从可靠到不可靠。皮姆斯勒想确保 60% 的保留率,这在 SuperMemo 的标准下是非常低的。他打赌启动稳定性是 5 秒,而 SuperMemo 使用 1-15 天,这对于 90% 的良好的知识回忆来说是可以的。皮姆斯勒的区间指数基数(E-Factor)是5,在大多数情况下应该是1.4-2.5。因此,皮姆斯勒的间隔与 SuperMemo 的间隔有很大的不同,不应该用作算法度量的基准。在他的原始论文(1967)中,皮姆斯勒建议间隔 5 秒、25 秒、2 分钟、10 分钟、1 小时、5 小时、1 天、 5 天、25 天、4 个月和2 年。差异主要来自于基于不同性质材料的实践(相当于 SuperMemo 中的高复杂性)。秒、分和小时的使用相当于死记硬背,在 SuperMemo 中强烈不鼓励使用。相反,建议优化知识表示。
1969年,阿尔弗雷德·马克西莫维奇写了《阅读与思考》。你在你的图书馆里找不到他的书。这本书是用波兰语写的,面向的是一小部分技术大学的学生。它提到了间隔重复,遗忘曲线,甚至遗忘指数可能决定最佳间隔。马克西莫维奇提出的第一个最佳间隔为 3 天。就像之前和之后的许多努力一样,这个好建议在很大程度上仍然被忽视。学生们急于通过考试,然后就忘记了。临时抱佛脚是一个原则,学校的压力会通过这个原则毁掉长期良好学习的前景。我之所以知道马克西莫维奇的书,是因为我在波兰的一所技术大学学习过,而且我对自己的间隔重复方法很感兴趣。我只能想象,有几十个类似的文本中,直觉被表述为一个好建议,然后仍然被大众忽视。如果没有时间和空间的巧合,将来关于间隔重复的文章可能永远不会注意到马克西莫维奇曾经存在过。马克西莫维奇的灵感可能来自皮姆斯勒、梅斯、他自己的直觉,或者其他我不知道的潜在文本。马克西莫维奇给扎弗拉涅克的话以自信,对SuperMemo表示怀疑:"一切都发生过"。
1972 年:莱特纳盒子
在 SuperMemo 之前,在间隔复习领域最大的实践和算法上的成功要归功于塞巴斯蒂安·莱特纳。1972年,他提出了莱特纳盒子系统。在莱特纳系统中,抽认卡被按优先级排序,并被转储到对应不同稳定性级别的盒子中。与之前提出的理论建议相比,莱特纳系统有一个巨大的优势:它是实用的。这是一个任何人都可以使用的系统,几乎不需要介绍。即使是写在纸上的 SuperMemo(1985) 相比之下也显得复杂。

图片:一个错误的Leitner系统的突变,失败的答案只被移回一个方框(来源:Wikipedia)。这种变体在Duolingo中使用了一段时间
莱特纳盒子不是一个间隔重复工具。它是一个排序工具。没有间隔的概念,更不用说最优间隔。盒子的名称来源于最初的实现,以物理闪卡盒的形式出现,与时间无关。当莱特纳盒子定期用于一个小型的抽卡片集合时,它会模拟间隔重复的行为。如果间隔太短,就会导致死记硬背。如果太长,就会导致次优结果。然而,在SuperMemo,低优先级的材料也可能周期性推迟,并产生很长的间隔,这会降低预期的稳定性增长,但对于记忆时间较长的卡片,稳定性增长会变得较大。在 20 世纪 90 年代和新千年之初,莱特纳系统被用于许多成功的闪卡应用。随着他们不断修改和改进复习程序,这些应用程序实际上可能已经发展成为一个成熟的间隔重复系统。由于 SuperMemo 的 SM-2 算法的流行,他们的应用下降了,但结果证明该算法很容易实现,而且非常优秀。
莱特纳盒系统的较新的软件版本可能会将间隔附加到优先级盒上,例如第 5 盒需要 16 天,但是这种方法的缺陷无异于死记硬背:(1)失败仍会导致间隔的回归,但这应导致重新学习;(2)第一个月重复5次,不能很好地与组织良好的知识相配,组织良好的知识可以在第一个月减少 60-80% 的学习成本。(3)需要更多的盒子。在SuperMemo中,我们看到间隔时间远远超过了人类的最长寿命。对应用程序的使用寿命需求增加了 200%。这是永久记忆间隔与16天之间的差异。 需要额外的 11 个盒子来覆盖 EF 为 2 的使用寿命。
如今,最流行的语言学习系统之一是 Duolingo。很长一段时间,它都使用莱特纳系统。如今,他们采用了基于可提取性预测的新算法。然而,他们仍然使用莱特纳系统作为基准。更糟糕的是,他们的基准使用了优先级盒中的抽认卡的反向传输(在这里,遗忘后的稳定性被高估了)。归一化莱特纳可以作为一个基准,然而,简单的归一化相当于使用 EF 为 2,可能会产生与选择 EF 为 1.6 不同的结果。在未来,所有的算法都应该转换到一个由 SuperMemo 提出的通用度量,并且 SM-2 可能成为一个有用的度量基准,可以与专用解决方案并行实现。我希望用户在这方面要求清楚、统计、度量和完全开放。顺便说一句,如果您碰巧使用了SuperMemo 17 版本 17.4,您可以将 SM-17 与莱特纳系统、皮姆斯勒和 SM-2 进行比较。不用说,如果您的集合足够大,差异相当惊人。
在 20 世纪 70 年代,托尼·布赞通过思维导图创新专注于结构化知识。矛盾的是,思维导图和 SuperMemo 会因为缺乏统一的理论而产生冲突。简而言之,我们需要好的模型来理解这个世界,我们需要间隔重复来长期保留模型的组成部分。布赞也有他自己的想法,那就是如何将复习间隔开。当他在 20 世纪 90 年代初第一次见到 SuperMemo 时,他立刻同意了这个概念,然而,他总是更喜欢关注知识结构而不是简单的回顾。
1980 年代:SuperMemo
1982 年,我自己的作品进入了人们的视野,那时我真的受够了没完没了的遗忘过程。我想学生物化学和生理学。我会读书,做笔记,因为遗忘的过程,一切都是徒劳的。即使是最重要的事实也可能在最不幸的时刻(如考试)被遗忘。我决定采用主动回忆。我不只是做笔记,而是把笔记当成问题和答案。我可以覆盖答案,并使用主动回忆来回应。这将极大地改善学习。这就是 SuperMemo 直到今天的做法。这个新方法对我提高我对学习的热爱产生了很好的影响。
到 1984 年,我已经熟练地掌握了主动回忆法,知道复杂的问题是行不通的。如果你在答案中填了太多东西,例如,列一张长长的清单,你就会一直忘记。这将是徒劳的学习。我后来把这种对简单性的追求称为“最小信息原则”。今天,这一原则是最早提到的组织知识 20 条规则之一。
真正的突破出现在 1985 年,即艾宾浩斯关于记忆的论文发表 100 年后。我想检查一下间隔是如何影响回忆的。我需要找出重复之间的最佳间隔的长度。显然,这些间隔是存在的。我只需要测量它们。实验过程在这。这个实验简单、粗糙、懒惰、仓促。6 个月后,我制定了第一个 SuperMemo 算法,而不是花几年时间让耐心找出所有的细节。你可以称它为第一个有点科学的间隔重复。我的研究是基于个人和一种学习材料,但它足够普遍,多年后有许多忠实的用户。在 1985 年 7 月 31 日,我开始使用新的方法学习生物化学。这是使用计算机的间隔重复的生日。计算机程序 SuperMemo for DOS 出现于 1987 年,SuperMemo 这个名字提出于 1988 年。
在 20 世纪 80 年代,贾普·穆尔的记忆链模型是可能会得出一个固定的间隔重复算法的最早的记忆模型之一。它甚至有自己的早期应用——《尼莫船长》(Captain Mnemo)——可能与 SuperMemo 在这一领域展开竞争。Captain Mnemo 和 OptiLearn 就是这样的例子,它们说明了为什么在学术环境中,伟大的理论往往不能得到更广泛的应用。
在 1991 年,SuperMemo World 成立,并描述了它的起源。从那时起,间隔重复的发展已经呈指数级增长。到 1999 年,我们开始使用“间隔重复”这个术语来代替“SuperMemo 方法”。有关 SuperMemo World 的最新进展,请参见此处。
下一章:17 成败剖析