

起初缓慢推行的 SM-2 算法
SM-2 算法[1]在 1987 年 12 月 13 日首次被用于学习中,并在一些应用中稍作调整后存续至今。SuperMemo 在 1989 年[2]放弃了这个算法,然而,算法 SM-2 不断地在新的应用中出现,其频率至高,几乎每个月都有新的变体。我很久以前就数不清了。有些 SM-2 算法变体与 SuperMemo 的原则相矛盾,却仍然自称来自 SuperMemo。违背 SuperMemo 原则的最常见做法包括以分钟为单位的间隔,或在评分为失败时将间隔减半(莱特纳风格)。因为这些变体,冒出了不少 SuperMemo 的假新闻。请注意,假新闻是撰写本文的最大动力之一。
当 Duolingo 在他们的论文中说到参考 SuperMemo 的手选参数时,这一定是依靠一些过期文本的结果,也许是二手文本,也许是参考 SM-2 算法而写的文本。毕竟,截至 1989 年,SuperMemo 的适应性相当强,而 SM-17 算法[3]是现存的最具适应性的算法。
误导的部分责任在我身上,因为我不再关心同行评议,没下足功夫辟谣,而任由信息在网络上野蛮生长。
在 19 世纪 80 年代,SuperMemo 在 Atari 上发布的非盈利分支首先使用了 SM-2 算法 。后来,SuperMemo 的次要复制品们(例如用于手提电脑的)选择了 SM-2 算法的变种,并各有创新。很多算法变体都提供了不少惨痛经验,因为它们为了死记硬背而不尊重记忆。
到 2001 年,SuperMemo World 在算法上领先了整整五个大世代。所有主要的软件系列,包括在线 SuperMemo 和 SuperMemo for Windows 都采用了该算法的数据驱动变体。http://supermemo.net 成为次世代的电子学习平台之一,现在已经发展成为 supermemo.com。SuperMemo for Windows 开创了自学 的解决方案,如渐进阅读[4],睡眠和学习优化,或神经创造力。同时,SM-2 算法成为其他开发者低门槛的首选方案。
1998:发布和加速
1998 年 5 月 10 日,SM-2 算法向公众开放,并在网上公布。
Mnemosyne 是 2003 年诞生的 MemAid 的分支,也是第一个采用 SM-2 算法的应用,用其替代了 MemAid 的神经网络。截至 2006 年,Mnemosyne 一直在用“间隔重复历史”的数据来优化一个 SM-2 算法的变体。Mnemosyne 免费而且支持多平台,因而快速建立了庞大的用户群体,比如在 Linux 平台上的用户,或者有 Latex 需求的用户。
Anki 诞生于 2006 年 10 月 6 日。它以SM-2 算法为基础,在近十年的时间里最为广泛地普及了这个算法。Anki 仍然在不断发展壮大,并其算法中引入了大量创新,但拒绝超越其基本原则(见:对 SM3+ 的批评)。
2007 年,当我们与 Gary Wolf 见面时,SuperMemo 看起来就像一个悲伤的荒岛,其中的问题在于:如果它这么好,为什么其他人不尝试复制这个算法?当时,Anki 和 Mnemosyne 还鲜为人知,2008 年 Wolf 在《连线》杂志上发表的文章引起了教育方面的软件开发者一窝蜂涌入间隔重复[5],做出各种实现。算法 SM-2 像个低垂的果实一样任人采摘,并加速地扩散。许多 SuperMemo 的用户声称,如果没有 Wolf 在《连线》上的文章,他们永远不会发现这个程序。Krzysztof Biedalak 喜欢开玩笑称 Wolf 的文章确实是个突破。然而,这种突破不属于 SuperMemo 的突破。它只是打开了泄洪的闸门,让一堆竞争者冲入了间隔重复的领域。
2008:爆炸
Quizlet 2005 年开始开发,并发布于 2007 年。它最初是一个典型的死记硬背工具,然而到了 2015 年,在风险投资的支持下,Quizlet 宣布,该应用更加强调长期保留,于是采用了算法 SM-2 的变体。到了 2017 年,他们决定使用机器学习来部署新算法,这种新算法利用了收集到的数十亿条重复记录。SuperMemo 算法在 Quizlet 的采用时间虽短暂,但一定让 SM-2 算法的一种变体有机会接触到有史以来最大的用户群体。当时,Quizlet 报告说,在美国每两个高中生中就有一个人在使用 Quizlet。
Quizlet 采取的新方法是建立在强大的基础上的,这样便能制造出非常强大的工具,然而,非常令人失望的是,优化算法背后的动机却是:「死记硬背是许多学生的现实,我们希望帮助他们充分利用他们的学习时间,无论他们如何使用 Quizlet」。SM-17 算法为学生提供了更多的自由:(1)在需要时提前学习,或(2)推迟低优先级的材料。然而,我们始终不鼓励死记硬背[6]这种不良做法。是学校需要适应[7]人脑,而不是相反。看似是执着于学习效率的死记硬背伤害了 SuperMemo,但“对学习效率的追求”永远不会改变。
2017 年 Quizlet 停止使用简单的复习计划,也许也是久经考验的 SM-2 算法不再流行的兆头。新的竞争者需要采取智能工具,或者寻求 SM-17 算法授权。风向是利好的。
有多少人使用间隔重复?
1991 年中期,我的一个同学试图让我振作起来。他预言我们会成功,我们总能卖出 10-20 份 SuperMemo。我当时更乐观。1993 年,我预测 1996 年时 SuperMemo 能有 100 万用户。1994 年,波兰的 Enter 提到了Marczello Georgiew 也抱有这样的乐观态度:
在 SuperMemo World 收到的关于用户吸引点的调查问卷中,SuperMemo 用户认为它的有效性具有压倒性的吸引力。对一个软件来说,提供学习结果才是真正算数的点儿。那用户不喜欢哪点?用户会对这点或那点不满意,最常提的是 SuperMemo 总是先以英语发布,即使在波兰。但特别令人讨厌的地方则没有。当然,没有人质疑这样一个事实:有了 SuperMemo,人们可以更快地学习,而且永远不会担心遗忘。怀着这样一份美好的图景,人们可能会问为什么 SuperMemo 还没有在全世界卖出数百万份。Marczello Georgiew,SuperMemo World 的市场总监建议可以回想一下 Graham Bell 在试图推出他「可以通过电线说话」的有趣机器时遇到的问题,或者行业未来学家对推广轰隆隆会造成空气污染的「机器马」的悲观预测。然后他自信地补充:沃兹尼亚克花了 10 年时间将一种必要性变成发明的实现,给我们一半的时间,我们将把他的发明变成全球的必需品。
在我对“何时到达 100 万用户”的预测中,我猜早了 3 年,而且必须对短时用户和活跃用户进行区分。间隔重复的活跃用户的比例随着广泛的采用而不断下降。2007 年,我们估计 SuperMemo 的覆盖面为 500 万,其中大部分是免费版 SM 和分割版 SM 用户。在这 500 万中,只有 0.4-4.0% 是活跃用户。这可能只有 20,000 名学生。
在 2009 年,Gwern Branwen 估计 SuperMemo 活跃用户的数量约为 10 万,这个估计与我手上的数字差不多一致。对于 SuperMemo World 二十年来的努力工作来说,这个数字并不太乐观。
然后让我们仔细看看间隔重复今天的影响力。我在下面的估计遭到了大量的怀疑。我同意它们是基于大量的猜测。然而,一旦你处于一个指数增长的曲线上,即使是大的估计误差也没有什么区别。你可以高估 200%,但仍能在短时间内迅速赶上。
这就是为什么我毫不犹豫地说,间隔重复的普及范围会指数级增长到“大B”(译注:Billion,十亿),也就是 10 亿用户。亚马逊的 Kindle 在其词汇生成器的闪卡选项中加入了间隔重复。即使是使用 Kindle 的 SuperMemo 用户也可能对这个事实一无所知。如果我们能成功地说服风险投资,让他们相信这个想法是有意义的,那么早在 1996 年,“带抽认卡的书”就是将 SuperMemo 带进纳斯达克的入场券。
然而,要达到 10 亿用户,我们需要在其他的突破。我想到的第一个明显的候选者是 Facebook,Facebook 可能在嘈杂的社交互动中插入间隔重复,使自由学习变得无感,即用户会不自觉地学习。
如果你认为 Facebook 和间隔重复是不相容的世界,考虑一下广告的世界。这些天,我们都讨厌广告。不管它的目标有多好。然而,“广告”可以通过采用间隔重复,最大限度地提高记忆效果,并最大限度地减少烦扰(即可提取性)。即使是最吸引人的电视广告,在第三次接触时也会让你感到紧张。间隔重复可以确保可提取性低,保留率高。
最后但同样重要的是,间隔复习可能被坏人利用:假新闻的制造者或者其他更坏的人。宣传骗子可能会在世界领导人的背后肆意操纵。他可能会在更高伟的空间影响世界。这可能会使整个世界暴露在间隔重复中,以确保我们都记得。
“金字塔的顶点”非常糟糕,我甚至不会列出它。我不想给坏人任何主意。
我下面的估计包括几个相当确定的点。1985 年的第一个用户,1987 年的第二个用户,到 2000 年的一百万,以及我费尽心思估计的 2007 年的五百万。今天,Duolingo 声称有 20 万用户。Quizlet 的用户甚至更多。这种增长仍然没有显示出饱和的迹象。
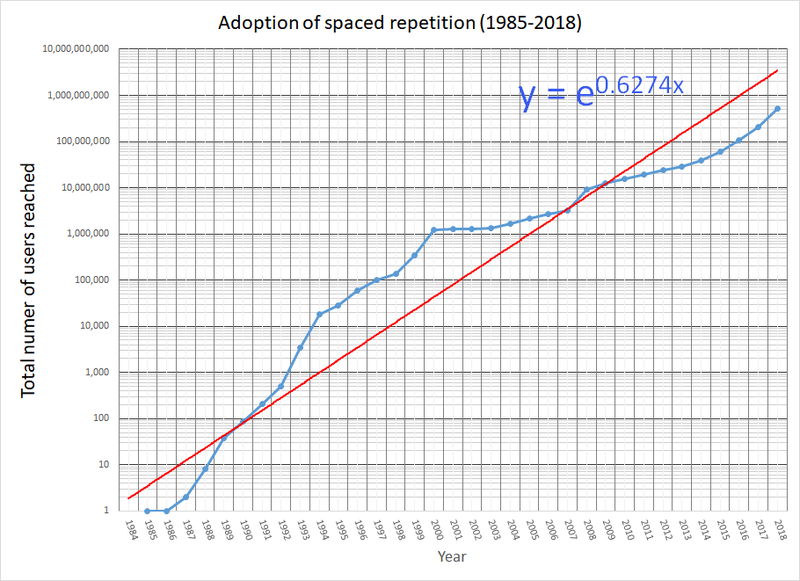
图:我们早就料到间隔重复会出现饱和的迹象。但是,它必定会在演变的某个时刻冲击到 10 亿用户。一旦它与人类的数字生活融为一体,它将影响到几乎所有人。如果我的估计是正确的,在网络的帮助下,它普及速度仍然领先于电话、汽车和广播,虽然我们从未想过有可能与口袋妖怪或愤怒的小鸟竞争。图中的指数回归公式是:Reach=exp((year-1984)*0.63),它确定的红线刚刚越过 10 亿。
今天,由于间隔重复几乎没有准入门槛,有许多学生在尝试使用几周甚至几天后就放弃了。活跃用户的比例可能非常低。即使用户量达到了 10 亿用户,若他们都不学习的话,仍然微不足道。下一步的工作是引发文化范式的转变,提高长期高效学习价值。我们需要从改变学校教育[8]的制度开始,并采用自由学习[9]的原则。
一旦间隔重复的用户达到 10 亿,很有必要转变文化范式,让软件的使用者更能享受长期优质学习[10]的实际利益。
前路漫漫。
总目录:0 目录《间隔重复的历史》
上一章:14 2014:SM-17 算法
下一章:16 记忆研究摘要
Thoughts Memo 汉化组译制
原文:Exponential adoption of spaced repetition
参考
1. 1987 SuperMemo 1.0: 日志 ./97887756.html2. 1989:SuperMemo 适应用户记忆 ./205600711.html
3. 2014:SM-17 算法 ./473482969.html
4. 渐进阅读 https://www.yuque.com/supermemo/wiki/incremental_reading
5. 间隔重复 (spaced repetition) ./305651556.html
6. 死记硬背(填鸭式学习) ./360416156.html
7. 教育改革 ./242815901.html
8. 被动的学校教育 ./359037513.html
9. 自由学习 ./272543239.html
10. 学习的乐趣 ./1578551193.html