
「如果一棵树在森林里倒下,而周围没有一个人听到,它会发出声音吗?」我记得曾经看到过一场关于这个话题的真实争论——一场完全天真、跟贝克莱主观唯心主义(Berkeleian subjectivism)沾不上半点边的争论。对话仅仅是这样:
「它当然会发出声音,就像任何其他倒下的树一样!」
「但要是都没人听到,怎么能叫有声音呢?」
标准的理性主义观点会认为,第一个人的意思是把「声音」等同于空气中的声波振动;而第二个人是把「声音」等同于大脑中的听觉体验。如果你问「有声波振动吗?」或者问「有听觉体验吗?」,答案立刻就显而易见了。所以这场争论的实质,其实是在争论「声音」这个词的定义。
我认为这个标准分析在本质上是正确的。所以让我们先接受它作为一个前提,然后问问:为什么人们会卷入这样的争论?其潜在的心理机制是什么?
启发式与偏见项目(heuristics and biases program)的一个核心理念是:人类犯的错误,往往比正确的答案更能揭示认知的运作机制。为了「一棵倒在荒无人烟的森林里的树究竟有没有发出声音」而争得面红耳赤,传统上被认为是个错误。
那么,究竟是怎样的心智架构,才会对应于这种错误呢?
在伪装的查询[1]一文中,我介绍了一项关于「蓝蛋(bleggs)」和「红方(rubes)」的分类任务。高级分拣员 Susan 解释说,你的工作是对传送带上下来的物体进行分类:把蓝色的蛋形物体(蓝蛋)放进一个箱子里,把红色的立方体(红方)放进另一个箱子里。原来,这是因为蓝蛋含有小块的钒矿石,而红方含有少量的钯,这两种物质在工业上都有用处。
然而,大约有 2% 的蓝色蛋形物体反而含有钯。那么,如果你发现了一个含有钯的蓝色蛋形物体,你应该把它叫做「红方」吗?毕竟你要把它扔进红方箱子里——为什么不干脆叫它「红方」呢?
但是,当你关掉灯时,几乎所有的蓝蛋都会在黑暗中发出微弱的光。
而且,含有钯的蓝色蛋形物体,其在黑暗中发光的概率和任何其他普通的蓝色蛋形物体是一样的。
所以,如果你发现了一个含有钯的蓝色蛋形物体,然后你问:「它是一个蓝蛋吗?」,答案取决于你要拿这个答案来做什么。如果你问的是「这个物体该放进哪个箱子?」,那么你做出的选择就好像这个物体是个红方一样。但如果你问的是「如果我关掉灯,它会发光吗?」,你的预测就好像这个物体是个蓝蛋一样。在第一种情况下,「它是一个蓝蛋吗?」这个问题代表了被伪装的查询:「它该放进哪个箱子?」而在另一种情况下,它代表的则是另一个被伪装的查询:「它会在黑暗中发光吗?」
现在,假设你面前有一个物体,它是蓝色的、蛋形的,并且含有钯;而且你已经观察到它长有绒毛、有弹性、不透明,且在黑暗中发光。
这已经回答了每一个查询,你已经观察了每一个被引入的可观察特征。再也没有留下任何东西,可以供那个伪装的查询去代表了。
那么,为什么还会有人忍不住想要继续争论这个物体到底是不是一个蓝蛋呢?
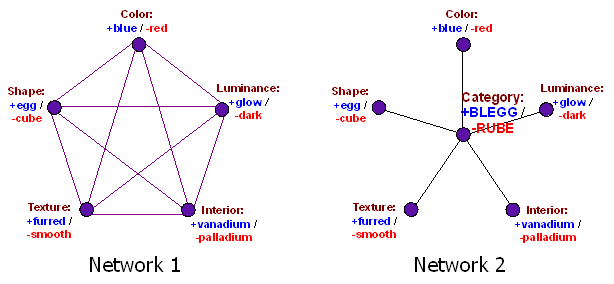
下面这两张来自神经类别[2]一文的图表,展示了两种可能被用来回答关于蓝蛋和红方问题的神经网络。
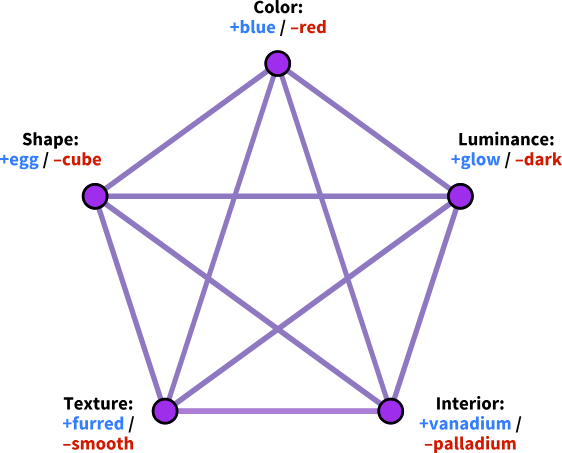
网络 1 有很多缺点——比如可能会产生震荡或混沌行为,或者需要 O(N²) 的连接数——但是,网络 1 的结构确实有一个比网络 2 强得多的优势:网络中的每一个单元(节点)都对应着一个可以被测试的查询。如果你观察了每一个可观察特征,并把每一个值都固定(clamp)下来,网络中就不会再有任何剩余的、未确定的单元了。
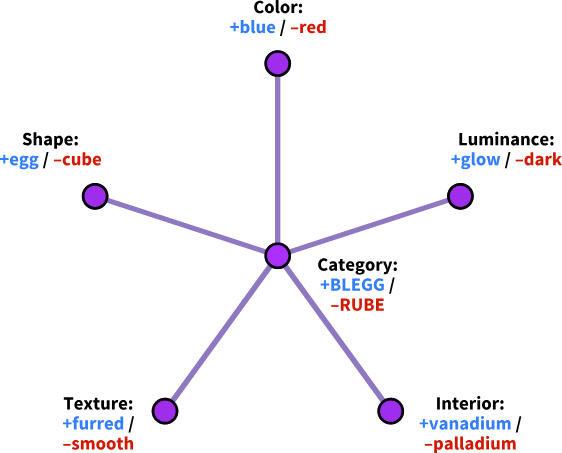
然而,网络 2 更有可能是一种大致接近人类大脑工作方式的模型:它运算快、成本低、可扩展性强——并且在中心有一个额外悬挂着的游离单元,即使我们在观察了周围每一个节点(特征)之后,它的激活状态仍然可以存在变化。
也就是说,即使你已经知道了这个物体是蓝色还是红色、是蛋形还是立方体、是多毛还是光滑、是明亮还是黯淡、是含有钒还是钯,你依然感觉好像留下了一个未解之谜:「但它到底是不是一个蓝蛋呢?」
通常情况下,在我们的日常经验中,空气的声波振动和大脑的听觉体验是相伴而生的。但是,一棵倒在荒无人烟森林里的树,解开了这种常见的关联捆绑。于是,即使你明明知道这棵倒下的树产生了声波振动但没有产生听觉体验,你依然感觉好像留下了一个问题:「它到底发出声音了吗?」
我们知道冥王星在哪里,以及它的运行轨道;我们知道冥王星的形状,也知道它的质量——但它是一颗行星吗?
请记住:当你看网络 2 时,就像我把它展现在这里一样,你是在从外部看待这个算法。人们在思考时绝不会想,「中心单元该触发还是不触发?」这就好比你绝对不会想,「我视觉皮层里的第 12,234,320,242 号神经元该触发还是不触发?」一样。
你需要刻意地努力,才能从外部视角去想象你的大脑——而且,即便如此,你依然看不到你实际的大脑;你想象出来的,只是你认为大脑里存在的东西。哪怕你是基于科学原理去想象的,不管怎样,你也无法通过内省(introspection)直接触及神经网络的结构。这就是为什么古希腊人没能发明计算神经科学的原因。
当你看网络 2 时,你是在从外部看它;但是,如果你自己就是一个正在运行那个算法的大脑,那种神经网络结构从内部感觉起来的方式就是:即使你已经知道了这个物体的每一个特征,你依然会发现自己在想:「但它到底是不是一个蓝蛋?」
这是一道难以跨越的巨大鸿沟,我曾亲眼目睹它让无数人停滞不前。因为我们不会本能地把我们的直觉看作是「直觉」,我们只会把它们当成「现实世界」本身。当你看着一个绿色的杯子时,你不会认为自己看到的是在视觉皮层中重构出来的一幅画面——尽管这确实就是你正在看的——你只是看到一个绿色的杯子而已。你会想:「瞧,这个杯子是绿色的」,而不是想:「我的视觉皮层里呈现的关于这个杯子的画面是绿色的。」
同样的道理,当人们在争论倒下的树是否发出了声音,或者冥王星是否是一颗行星时,他们并不认为自己是在争论:自己的神经网络中某个用来分类的中心节点是否应该被激活。在他们看来,事情就是非黑即白的:树要么发出了声音,要么没有。
我们知道冥王星在哪里,知道它的轨道;我们知道冥王星的形状和质量——但它是一颗行星吗?没错,有人确实会说这是一场关于定义的争论——但即使是这种说法,也是从网络 2 的视角出发的,因为你依然是在争论中心单元究竟该如何进行逻辑接线。如果你是一个按照网络 1 的架构构建出来的心智,你就不会说「这取决于你如何定义『行星』」,你只会说,「既然我们已经知道了冥王星的轨道、形状和质量,那就没有任何问题可问了。」或者更准确地说,如果你是一个按照网络 1 构建的心智,这就会是你内心的感觉——你就是会感觉没有留下任何问题。
在你能够开始质疑自己的直觉之前,你必须首先意识到,你心灵之眼正在注视着的,本身就是一种直觉——也就是某种从内部被体验到的认知算法——而不是对「事物真实本来面貌」(the Way Things Really Are)的直接感知。
我认为,人们之所以死守着他们的直觉不放,与其说是他们坚信自己的认知算法绝对可靠,不如说是因为他们无法将自己的直觉,看作是他们的认知算法从内部碰巧呈现出来的样子。
正因如此,你试图向他们解释人类原生的认知算法是如何走入歧途的任何话语,最终都会被拿去与他们对「事物真实本来面貌」的直接感知相对比——然后作为明显荒谬的谬论被抛弃。
上一篇:
神经类别下一篇:
争论定义Thoughts Memo 汉化组译制
感谢主要译者 gemini-3.1-pro,校对 Jarrett Ye
原文:How An Algorithm Feels From Inside
参考
1. 伪装的查询 ./2050519448814195814.html2. 神经类别 ./2050999897550223000.html