
比如间隔重复。或者更具体一点,试试开源间隔重复软件 Anki。
间隔重复结合了间隔效应和测试效应,能科学有效地增强长期记忆。
以下内容摘自 @mmjang 的译文《【三万字长文】量子物理学家是如何使用 Anki 的? 》,原文标题为 Augmenting Long-term Memory,即《增强长期记忆》。
译者的话:
本文原文是 Augmenting Long-term Memory ,其作者 Michael Nielsen 是量子物理学家、科学作家、编程研究者,现供职于 Y Combinator Research 。他在《自然》等期刊发表过多篇高引论文,他写作的量子力学和深度学习教材也广受欢迎。

作者在本文记录了用 Anki 增强科研和生活中长期记忆的经验,同时也写了他对广义上的记忆软件的深刻思考。
这篇详尽的长文是记忆软件领域不可多得的第一手大牛经验,原文篇幅大且在墙外,所以翻译成中文以便更多人读到。
翻译水平十分有限,欢迎指出错误。
和原文一样,本文以 CC BY-SA 3.0 协议发布。
mmjang
导语
1920 年代中期某天,莫斯科报纸记者 Solomon Shereshevsky 走进心理学家 Alexander Luria 的实验室。报社老板发现 Solomon Shereshevsky 从不需要做笔记,却能记住听到的一切,于是老板建议让专家检查他的记忆力。
Luria 从短单词和数字序列构成的简单测试开始,检查 Shereshevsky 的记忆力。Shereshevsky 能轻松记住这些,所以 Luria 逐渐增加序列的长度。但是序列再长, Sherehevsky 还是能轻松回忆。Luria 对此着迷,并在其后的 30 年继续研究 Shereshevsky 的记忆力。Luria 在一本总结其研究的书里写到:
S. 的记忆力似乎在容量和持久度这两方面都是无限的。实验表明,他可以毫不费力地回忆出任何长度的词串,就算这些词串是一个星期、一个月、一年甚至好几年前给他看过的。实际上,有些测试他记忆留存水平的实验,是在他原先回忆单词的十五六年后进行的,然而它们总是会被正确回忆。
此般事迹真是不可思议。记忆是思考的基础,拥有完美记忆的概念更是诱人。同时,很多人对自身记忆抱模棱两可的态度。经常听到有人用羞怯、抱歉、甚至对抗的语气说,“我记忆力不行”。
鉴于记忆在思考中的中心位置,我们自然会问计算机是否可以作为辅助改善记忆的工具。这个疑问引发了许多优秀思想的产生,对其答案的探寻也导致了计算历史上很多最重要的愿景文档的出现。早期的例子是 Vannevar Bush 在 1945 年提出的“基于机械的记忆扩展器 memex ”。他写道:
memex 是一种个人存储其全部书籍、档案和通信的设备,其机械结构让人可以用极高的速度的灵活性查阅内容。它是对个人记忆的扩大版私人补充。
memex 的愿景激发了后来的计算机先驱们,包括 Douglas Engelbart 的人类智力增强理论,Ted Nelson 的超文本,Tim Berners-Lee 对万维网的构想。在其关于“Web”的提案中,Berners-Lee 描述了他的雇主对开发一种集体机构记忆的需求,
需要开发,能随着组织和其描述的项目增长与进化的信息池。
这只是用计算机增强人类记忆的许多尝试之一。从 memex 到 Web, 再到 org-mode、Project Xanadu 和为个人全部思想构建导图的尝试:记忆增强是对计算机行业极其有推动力的愿景。
本文研究个人记忆系统,即设计目标是提高个体长期记忆的系统。本文第一部分描述我对某个这样的系统(Anki)的个人使用经验。我们会看到 Anki 几乎可以用来记住一切事物。也就是说,Anki 让记忆成为一种选择,而不是留给概率的偶然事件。我将讨论如何用 Anki 理解学术论文、书籍以及更多。我也会介绍一些应用 Anki 时的模式和反面模式。虽然 Anki 是极其简单的程序,用其培养一项旨在深入理解复杂材料,而不单单是记忆简单事实的精湛技巧是可能的。
本文第二部分讨论广义的个人记忆系统。作为一种认知技巧,记忆被许多人以矛盾甚至轻蔑的态度看待:例如,人们经常谈论“死记硬背”,好像死记就比更高级的理解低级一样。对此观点我会提出反对意见,并论证记忆是问题解决和创造力的核心。第二部分也会讨论认知科学对于构建个人记忆系统,以及更广义上的人类认知增强系统的作用。
本文的风格并不常规。它既不是传统的认知科学论文(如对于人类记忆和其工作机制的研究),也不是计算机系统设计论文,虽然原型设计是我自身的主要兴趣。其实这篇文章是对于个人记忆系统的经验法则和非正式临时见解的提炼。我想把这些理解作为构建我自己的系统的准备。收集这些见解期间,我意识到别人也可能对此感兴趣。你完全可以把这篇文章看作是如何培养关于个人记忆系统的精湛技艺的指南。但是因为写这样的指南不是我的主要目标,对于读者本文可能会是一篇“比我想知道的要多得多”的指南。
作为引言部分的总结,稍微说下本文不会覆盖的内容。我只会简短的讨论记忆宫殿和轨迹记忆这样的视觉技巧。本文不会介绍用药物增强记忆,也不会介绍用未来可能实现的脑机接口来增强记忆。这些都需要单独的文章。然而我们将会看到仅仅是基于信息的组织和呈现都足够产生强有力的思想。
第一部分:用 Anki 记住几乎一切
我会以我自己使用个人记忆系统 Anki 的经验作为开始。如上所述,这部分内容很私人,是我自己的观察和经验法则的汇总。这些法则也许对其他人并不适用;事实上我可能高估了它们对我自己的适用程度。这绝对不是关于 Anki 使用的严谨对照研究!尽管都是些轶事和主观感受,我仍然认为收集这些个人经验是有价值的。我不是记忆认知科学专家,欢迎纠正任何错误和误解。
第一眼看上去 Anki 只不过是一款电子化的闪卡程序而已。输入问题:

再输入对应的答案:

然后你会被要求复习卡片:显示问题,测试你是否知道答案。
Anki 比传统闪卡优越之处,在于他能管理复习日程。正确回答某个问题,则复习间隔会逐渐增长。一天的间隔会变成两天,然后是六天,再然后是十四天。这背后的考虑是随着信息的记忆越来越深刻,所需要的复习频率也越来越低。但是如果某次回答错误,则日程会重置,你需要重新累积复习间隔。
诚然用计算机来管理复习间隔很有用,这看上去好像也没什么大不了的。但是妙就妙在,这被证实是一种高效得多的信息记忆方法。
那么到底有多高效呢?
为了回答这个问题,让我们做些粗略的时间估计。我复习一张卡平均要花 8 秒。假设我用传统闪卡且每周复习一次,那么,如果要在接下来的二十年记住某个东西,每张卡需要 20 年乘 52 周乘 8 秒。最后可得出每张卡需要大概两个小时的总复习时间。
相比之下,Anki 不断增长的复习间隔很快就跨越一个月,然后超过一年。实际上,我自己的卡片集合平均间隔目前是 1.2 年,并在不断增长。在后面的附录里,我通过估计得出在 20 年内,每张卡平均只需 4 到 7 分钟复习时间。这些估计也考虑到了偶然出现的会重置间隔的失败复习。相比于需要两个小时的传统闪卡,这节省了不止 20 倍的时间。
于是我得出两条经验法则。第一,如果记忆某个事实值得我在未来花上 10 分钟的话,那么我就记它。第二,这条法则可取代第一条法则,如果某个事实看上去很惊人,那么不管它是不是值未来的 10 分钟,Anki 走起。这条例外的原因是,在一开始我们并不知道很多我们所知的最重要的事物的重要性,只是因为直觉告诉我们是这样的。这不意味着我们应该记忆所有东西。但是培育关于记忆的选择品味是值得的。
Anki 所带来的最大一项改变是,记忆不再是一项受制于概率的偶然事件。它确保我能用最少的精力记住某些东西。也就是说,Anki 让记忆成为一种选择。
Anki 能用来干啥?我将其用于生活的方方面面。专业上,我用它学习论文和书籍,学习讲座和会议,帮助回忆谈话中的有趣内容,记住日常工作中的关键见解。个人生活中,我用它记忆关于家庭和社交的各方面事实,我的城市和旅途,我的爱好。后面我会介绍一些 Anki 使用模式,以及一些应该避免的反面模式。
两年半的日常使用期间我用 Anki 制作了一万张多一点卡片。这包括基本没有制卡的 7 个月空歇期。每天花上 15 到 20 分钟即可跟上复习节奏。如果日清所需时间超过 20 分钟,那么通常意味着我制卡太快,需要慢下来。或者也可能是因为我没做到日清(后面会再讨论)。
在实践层面,我用桌面版 Anki 制卡,用移动客户端复习。我在早上喝咖啡、排队、换乘等时间复习。开始刷卡时,如果我的脑子足够放松,那么复习体验近乎冥想。反过来,如果脑子不放松,我会感觉复习更加困难,而且 Anki 会让人心神不定。
走上 Anki 之路过程中,我曾有过困难。若干熟人强烈推荐过它(或者其他类似的系统),几年内我试着用过几次,都很快放弃了。现在回过头看,要让 Anki 成为习惯,得跨越几个不小的障碍。
真正让我上了 Anki 的道,并将其变成习惯的是一个我看做是玩笑的项目。我曾因为从来没真正学会过 Unix 命令行而懊恼多年。我只学过大多数基础命令。对于编程人士命令行是神器,所以学好它还是令人向往的。所以,纯粹为了好玩,我想知道,能不能用 Anki 从本质上记住一整本关于 Unix 命令行的薄书。
能!
我选的是 O'Reilly 的《麦金塔终端口袋指南》,作者 Daniel Barrett。我并不是说我真的背下了整本书。但是我的确背下了全书大部分概念,包括大部分书中命令的名称、语法和选项,我想不到使用场景的命令除外。我想象到用处的东西基本都记住了。最后,在跳过看起来跟我无关的部分后,我大概记住了全书的 60% 到 70%。就算如此我的命令行知识还是有显著提升。
设定这个有些荒唐却极其有用的目标,给我对 Anki 满满的信心。真是令人振奋,显然 Anki 可以帮我学习之前对我来说太枯燥或太难的内容。这份信心转而使建立 Anki 使用习惯更简单了。同时,这个项目也帮我熟悉 Anki 的界面,也让我得以尝试不同的提问方法。也就是说,它令我掌握了用好 Anki 所需的技巧。
用 Anki 透彻阅读陌生领域论文
我发现读论文的时候 Anki 的帮助很大,特别是我专长之外的领域。作为用法举例,我将描述我阅读 2016 年一篇介绍 AlphaGo (来自 Google DeepMind 的围棋程序,打败了一些世界顶尖棋手)的论文的经验。
在 AlphaGo 打败李世石(历史上最强的围棋棋手之一)的那场比赛结束后,我向 Quanta 杂志提议写一篇关于此系统的文章。当时 AlphaGo 是媒体热点,大多数报道从人类利益角度展开,把 AlphaGo 看做旷日持久的人机大战的一部分,少许的技术细节只是作为点缀。
我想选取一个不同的视角。从 1990 年代到 2000 年代,我相信达到或超越人类水平的通用人工智能是遥不可及的。原因是,一直以来,对于构建基于直觉推断的模式匹配系统,研究人员只取得缓慢进展,此类系统是人类听觉和视觉的基础,也是玩围棋等游戏的基础。虽然 AI 研究者投入巨大,一些对人类来说毫不费力的模式匹配,机器仍然根本无法实现。
长期以来这些问题的研究进展都非常缓慢,然而在 2011 年左右,在深度神经网络方面进步的推动下,进展开始加快。例如,机器视觉系统在有限的任务下,从表现糟糕快速进步到可与人类比拟的程度。到 AlphaGo 发布时,已经不能说我们不知道怎么构建直觉模式识别系统了。问题没有彻底得到解决,但是我们的进步飞快。AlphoGo 在这个故事中地位举足轻重,我想写篇文章,探索构建捕获人类直觉的计算机系统的概念。
兴奋归兴奋,写这样的文章却会是不容易的。比起一般的新闻报道,它要求对 AlphaGo 技术细节有更深入的理解。好在我对神经网络还是有些了解的——我写过一本相关书籍。但是我对围棋一窍不通,也不懂 AlphaGo 用到的很多叫做强化学习的思想。我得从头开始学,要想写出好文章我得真正理解文章背后的技术内容。
我是这样着手去干这件事的。
首先从 AlphaGo 论文本身开始。我一开始读得很快,几乎是略读。我并不追求全面的理解。我只做两件事。第一,尝试识别出文中最关键的思想。有哪些关键技术是我需要去了解的?第二,像吸尘器一样扫荡我能轻松理解的基本事实,这显然对我有益。比如基本术语,围棋规则,等等。
这里有几个此阶段我输入 Anki 的问题的例子:“围棋棋盘的大小?”;“围棋里哪方先走?”;“AlphaGo 从多少人类棋谱学习?”;“AlphaGo 训练数据的获取途径?”;“AlphoGo 用到的两种主要神经网络名称?”。
你可以看到这都是些初级问题。它们都是初次浏览论文可以轻松获取的信息,虽然有时也得转向谷歌和维基。更进一步,虽然这些事实都是可以轻松地单独学会的,它们也很可能对深入理解论文其他内容有帮助。
我用这种方法快速过了几遍论文,每次都更加深入。此阶段我不会试图全面理解 AlphaGo。我是在构建我对背景知识的理解。任何时候如果有难以理解的地方,我不会担心,就直接继续往下看。重复阅读的过程中,我能轻松理解的范围一直在增长。我会增添关于 AlphoGo 的神经网络的输入特征类型的问题,关于神经网络结构的基础知识的问题,等等。
过了五六遍论文后,我回过头准备来一次细致的阅读。这次的目标是从细节上理解 AlphaGo。这时我已了解大部分相关背景,细读也变得相对容易,肯定比上来就强读容易多了。别误解我的意思,还是挺有挑战性的。但是肯定远比直接细读简单。
细读过一遍 AlphaGo 论文后,我按类似的路子细读了第二遍。豁然开朗之处更多了。这时我对 AlphaGo 的理解已经相当不错。放到 Anki 里的问题很多都是高层次的,有的甚至到了原始研究方向的前沿。我对 AlphaGo 的理解足够让我有信心去写我的文章中的相关部分了(实际中我的文章跨越了多个系统, 不仅仅是 AlphaGo,我也得用类似的方法去学习,尽管没有那么深入)。写文章的同时我继续往 Anki 里添加问题,最终问题总数达到数百个。至此最难的工作已完成。
当然,不用 Anki,我也可以通过记传统笔记,采取类似的过程来积累对论文的理解。但是使用 Anki 让我有信心长期记住这些理解。大约一年后 DeepMind 发布了后续的系统,AlphaGo Zero 和 AlphaZero。在此期间我没怎么思考过 AlphaGo 和强化学习,我仍然能轻松阅读后续的论文。我并不指望能达到原始 AlphaGo 论文那样的理解程度,在一个小时内我还是能对这些论文达到不错的理解。大部分之前的理解都还留存着!
相比之下,要是我当初用传统笔记法读 AlphaGo 论文,我的理解肯定会更快消散,读后续论文也会花更久。所以这样用 Anki 让我有信心长期记住理解。这般信心也会使当初的理解过程更为愉快,因为你相信你是为了长期目标而学习,而不是一天或者一星期就忘了的东西。
整个过程花了我几个星期内的好几天时间。工作量挺大。然而回报是我对当代深度强化学习有了不错的基础。这个领域重要性深远,对于机器人技术很有用,许多研究者认为它会在通向通用人工智能的过程中扮演重要角色。几天的努力让我从对强化学习一无所知到深刻理解此领域的一篇关键论文,这篇论文使用的技术在整个领域都被广泛采用。当然,我离成为专家路还远着。我不懂 AlphaGo 里的很多重要细节,让我自己构建这样的系统也需要多得多的努力。但是这样的基础性理解为日后的精进打下了良好基础。
值得注意的是我读 AlphaGo 论文是为了支援我的一项创造性工作,也就是为 Quanta 杂志写文章。这很重要:我觉得在为某些个人创造性工作服务时, Anki 的效果更好。
有人会忍不住想要用 Anki 为日后储备知识,“呀,我得学下非洲地理,或者了解下二战,或者......”。对我来说这些目标在智力上固然诱人,情感上却不愿为之投入。我已经试过很多次了。此目标会倾向于产生出冷冰冰无生气的 Anki 问题,这样的问题日后复习时难以与之构建联系,其答案也难以深入内化。问题似乎在于最初“应该”学这些东西的想法:智力上是好主意,我却没有一点情感投入。
反之,一旦是为了某些创造性工作而阅读,我就能问出更好的 Anki 问题。情感上我更容易与问题和答案产生连接。我就是更加在乎它们,而这种在乎意义深远。所以虽然为了(假设的)日后之用做卡片挺有诱惑力的,想办法让 Anki 融入创造性工作会更好。
用 Anki 浅读论文
大多数我进行过的 Anki 阅读比 AlphaGo 论文要浅得多。与一篇论文花上几天不同,通常我会花 10 到 60 分钟,特别好的论文时间可能更长。下面是一些我觉得对浅度阅读有用的模式。
如上所述,此类阅读通常是为了给某些项目做背景研究。我会找到一篇或者数篇文章,然后通常会花上几分钟做评估。这篇文章看上去包含与我的项目相关的重要见解和启发——新问题、新思路、新方法、新成果吗?如果是,那么我有东西可读了。
这也不是说我会读完论文里的每个字。我只会在 Anki 里加入论文里的核心主张核心问题核心思路。从摘要、引言、图表和图表标题里提取 Anki 提问尤其有用。我通常会在论文里提取 5 到 20 个问题。少于 5 个问题通常是坏事,这会让这篇论文成为我记忆中的孤儿。之后我会很难找到与这些问题的联系。换句话说,如果一篇论文没意思到 5 个好问题都提不了,那干脆一个问题也不问吧。
有种失败模式是 Anki 化有误导性的成果。很多论文包含错误或者误导,如果记住这样的条目,你已经在让自己变得更傻了。
如何避免 Anki 化有误导性的条目呢?
比如我最近就 Anki 化了我读过的 Benjamin Jones 和 Bruce Weinberg 的一篇论文。该论文研究科学家们做出最伟大发现时的年龄。
首先我得说:我没理由认为此论文有误导性!但是还是谨慎为上。谨慎行为的一个例子是,某个加进 Anki 的问题是:“对于 1980 年到 2011 年间,诺贝尔物理学奖获得者做出其获奖成果时的平均年龄,Jones(作者)有哪些结论?”(答案:48)。另外一个变体问题是:“哪篇论文声称 ,1980 到 2011 年间,诺贝尔物理学奖获得者做出其获奖成果是的平均年龄是 48 岁?”。(答案:Jones 2011)。类似的问题还有一些。
这些问题认同了以下判断:我们现在知道这是 Jones 2011 这篇论文里的结论,我们也知道我们依靠的是 Jones 和 Weinsberg 的数据分析质量。事实上,我没对数据分析做足够让我把结论诺奖获得者平均年龄是 48 岁当成事实的检验。但是它显然是这篇论文的结论。这两者是不同的,后者更适合 Anki 化。
如果我对分析的质量特别关心,我也许会再加几个关于这项工作困难之处的问题,例如:“Jones 2011 里关于诺奖获得者做出获奖成果年龄的确定的讨论,会有哪一项难点?”。优秀的回答包括:确认哪篇论文包含诺奖成果;论文的出版可能会比成果晚数年;有些成果可能分散在数篇论文中;等等。这些难点提醒我如果 Jones 和 Weinberg 不够严谨,或者犯了个可以理解的错误,他们的结论可能偏离事实。嗯,正好对于这篇文章,我倒是不太担心此类问题。所以我没往 Anki 里放这样的提问。但是组织问题的时候小心点以免误导自己还是值得的。
另一个读论文时有用的模式是 Anki 化图表。例如,这是 Jones 2011 里的一张图,显示物理学家取得诺奖成果时年龄小于 40(蓝线)和小于 30(黑线)的概率:
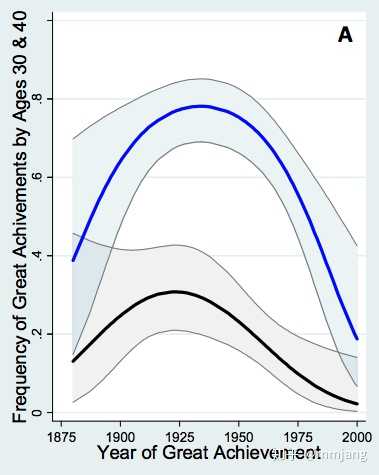
我的 Anki 问题很简单:“Jones 2011 里物理学家取得诺奖成果时年龄小于 40 和小于 30 的概率曲线”。答案就是上图,如果我脑海里回想的图里线条走向差不多的话,我就当我回答正确了。为了更深入的理解上图,我也可以问道:“Jones 2011 里关于诺奖成果的图中,40 岁之前取得伟大成果的概率峰值是多少(也就是上图中蓝线的最高点)?”(答案:0.8 左右)。事实上关于这个图可以轻松问出几十个有趣的问题。我没这么做,因为这些问题需要花太多时间。但是我的确认为此图很有吸引力,知道此图的存在也很有用,可以在需要参考更多细节时找到它。
上面说过我通常会花 10 到 60 分钟 Anki 化一篇论文,实际时长取决于我对论文价值的判断。然而如果文章让我学到很多也很有趣的话,我会一直阅读并制卡。好的资源值得投入时间。大多数论文并不符合这个路子,你很快就饱和了。如果你能轻松找到更有回报的东西读的话,马上换文章。刻意练习这种切换是有意义的,这可以避免养成一读到底这种妨碍生产力的习惯。一篇论文总是可以找到读得更深入的路径,但是这并不意味着你不能在别的地方获得更多的价值。在不重要的论文上花太多时间是失败之路。
用 Anki 进行主题阅读
我谈到了如何用 Anki 进行论文浅阅读和更深入的阅读。同时也有种思路是不仅用 Anki 读论文,而是“读”完某个领域或子领域的所有文献。下面是实现方法。
你也许会认为此方法的基础是大量浅读文献。实际上,真正领悟陌生领域需要深入关键论文——比如 AlphaGo 相关论文。深入重要论文所能带来的好处比单一的知识点和技术都显著:你体会到这个领域杰出的成果是什么样的。你借此领会这个领域最健康的规范和标准,内化在此领域提出好问题的方式,了解如何将技术组织到一起。你开始理解是什么让 AlphaGo 这样的系统成为突破性成果,同时也能了解到其局限性,同时也体会到它的出现其实是领域内的自然演进。这些体会是不能从单个 Anki 问题获得的。而是在深入关键论文的过程中提的问题中整体浮现。
所以,要获得领域的整体图景,我会从真正重要的论文开始,最好是其结果让我对这个领域开始感兴趣的文章。我会细致地把那篇论文读一遍,就像读 AlphaGo 论文一样。然后我细读领域内其他关键论文——理想情况下是最优秀的 5 到 10 篇。但是穿插其间我也会浅读数量更多的不那么重要(仍然优秀)的文章。从我目前的经验,这意味着几十篇文章,对于某些领域我估计最终需要像这样读几百甚至上千篇文章。
你也许会问为什么不仅仅关注最重要的这些论文呢?部分原因有些单调:很难区别哪些是最重要的论文。广泛的浅读让人明白哪些文章是关键的,而不至于投入很多时间细读后来发现并不是很重要的文章。同时,读这些基本的文章能让人领略到实践中行业内的常规进展是什么样的。这对于对于构建行业的整体图景,激发我本身的问题,也是很有价值的。实际上,虽然我不推崇花很多时间读三流论文,与三流论文开展不错的思想交流还是可能的。灵感来源于意想不到的地方。
长久下来这其实是 Mortimer Adler 和 Charles van Doren 所称的“主题阅读”的一种形式。我积累了对整个领域文献的理解:什么完成了,什么未完成。当然,并不是说我真的把整个文献都看完了。但是从效果上看还是很接近的。我识别到一些开放性问题,我希望有解答,但是却还没有解答的问题。我识别到一些技巧,一些充满可能性但其重要性还未为我所知的洞察。有时我好像还会发现行业范围内的盲点。我把这些也都做成了 Anki 问题。由于设计时并没有考虑过辅助创造性工作,Anki 这种媒介是有缺陷的:比如它并不能让你在暂存空间内长时间自由探索。但是就算不是为此设计的,作为创意支持它还是有用的。
我已经说了我是怎么用 Anki 学习未知领域的。与之对比,对于我已熟知的领域,我的好奇心和脑中的模型已足够强,从而容纳新知识会很简单。Anki 仍然有用,但是它在新领域绝对是最有用的。伟大的英国数学家 John Edensor Littlewood 曾写道:
我尝试学习兴趣领域之外的数学;每隔段时间我总想重新来过。
这捕捉到了学习新领域所必要的巨大情感投入。没有足够的动机,很难让很多新领域的资料稳固下来。Anki 对于解决这个问题能做很多。某种意义上它可作为情感义肢,真正地帮我创造实现理解所需的动力。如前面所说,它不能代替全部的工作,其他的决心(创造性工作,依赖我的人)对于创造这样的动机也很有帮助。无论怎样,Anki 给我信心去单纯地决定深入一个领域,并且记住和理解我所学到的。对于我所尝试过领域的概念性理解,这都是行之有效的。
这样阅读的一个惊奇后果是乐趣变得如此之多。我一直享受阅读,但是开始一门有挑战的新领域却是长路漫漫,经常会被我到底能不能踏入这个领域的怀疑所侵扰。这样的怀疑于是让我更不可能成功。现在我有自信踏入新领域并取得优秀且相对深刻的理解,一种经久的理解。这种自信让阅读更愉悦了。
更多 Anki 使用模式
说完了 Anki 在阅读技术论文中的应用,让我们回到一般使用模式。本节内容很多,读第一遍的时候最好快速浏览并关注最吸引你眼球的部分。
让 Anki 提问和回答尽量原子化:也就是问题和答案都只包含一个想法。例如,我学 Unix 命令行的时候提问:“怎么创建从 linkname 到 filename 的软链接”。答案是:“ln -s filename linkname”。遗憾的是,我经常答错。
解决方法是把问题重构为两部分。第一部分是:“创建 Unix 软链接的命令和选项是什么?”答案:“ln -s ...”。第二部分是:“创建 Unix 软链接的时候,linkname 和 filename 的顺序应该是怎样的?”答案:“filename linkname”。
将问题原子化使我原先总是答错的问题现在总是能答对。更重要的是:当我实际中想要创建 Unix 软链接的时候,我知道怎么做。
我不确定是什么导致了这种效应。我认为部分原因是因为专注。答错混合问题时,我经常对我具体的错误之处有点模糊。这意味着我没有足够集中于错误,所以不能从失败中学到足够的东西。答错原子化问题的时候我知道应当关注的确切位置。
一般来说,将 Anki 问题分解为更原子化的问题通常会有显著的益处。这是重构问题的强效模式。
注意这并不是说你不能保留原始问题的某种形式。我仍然想知道怎么在 Unix 里创建软链接,所以保留原问题还是值得的。但是这成为了一个综合性问题,是从简单原子知识点到更复杂内容的层级的一部分。
顺便,原子化的问题并不一定就不能包含复杂且高阶的概念。考虑下面这个来自广义相对论的问题:“罗伯森-沃克度规中 项是什么?”答案:“
”。好了,除非你学过广义相对论,这个问题看上去会很深奥。这是个复杂且综合的提问,它假设你已经知道什么是罗伯森-沃克度规,
代表什么,
代表什么,等等。但是,在已有背景知识的条件下,这却是一对非常原子化的问题和答案。
这样使用 Anki 的一个好处是让你养成分解问题的习惯。让你所学到的独一无二的东西精确地凝结。于我个人而言,凝结过程很有满足感,具体原因我却说不出来。有个真正的益处是我经常发现这些原子化问题会以最初没有想到的方式组合起来。麻烦一些都是值得的。
应该把 Anki 的使用看成一项待培养的大师级技巧:Anki 是个极其简单的程序:你以文本或其他媒介输入问题,然后根据你的回应,按相应的日程向你展示。虽然简单,其效用却是难以估量的。而且和很多其他工具一样,用好它需要技巧。应当把 Anki 看做一项可以发展到大师级别的技术,你也应该不断追求向此级别精进。
Anki 不仅仅是记忆简单事实的工具。它是可用来理解几乎一切事物的工具。把 Anki 当成仅仅是用来记忆词汇和基本定义这样的简单事实是常见的谬误。不过就像我们已经看到的,Anki 可以用于更高级的理解。我关于 AlphaGo 的问题从简单的“围棋棋盘的大小?”发展到关于系统设计的高阶概念性问题——AlphaGo 是如何避免过度推广训练数据的,卷积神经网络的局限性等等。
把 Anki 当成大师级技巧发展的一部分内容是培养把它用于超越基本事实的理解的能力。事实上我的很多关于 Anki 使用的见解(下面会有更多)其实本质上是关于什么是真正的理解。将事物拆分为原子知识点。构建由丰富的相互联系和汇总问题构成的层级。不要放入孤儿问题。与阅读材料打交道时的模式。关于问题类型的模式(和反面模式)。关于哪些东西需要记忆的模式。Anki 技能让你的认知方法论由构想变为现实。说大师级 Anki 用户也有大师级的理解能力未免言过其实。但这句话总归还是有点道理的。
使用一个大牌组:Anki 允许你把卡片组织为牌组和子牌组。一些人用此特性创造复杂的组织结构。我也曾这么做过,但是我逐渐把我的牌组和子牌组合并到了一个大牌组。这个世界并没有整齐的划分为独立的部分,所以我觉得把不同的问题杂糅在一起是个好主意。某个时间点 Anki 问我做鸡肉的时候应该火应该开到多少度。下个问题就可能是关于 JavaScript 的接口的了。这种混搭真的对我有实际益处吗?我不清楚。但是我认为不会有任何坏处,也能帮助我把知识运用到意想不到的情境下。
避免“编外问题”:假设我在浏览网页时碰到一则关于阿尔巴尼亚巨型猫鼬的有趣文章,一个我以前从来不知道我会感兴趣,但是结果发现有趣至极的话题。很快我就 Anki 了 5 到 10 个问题。很不错,但是经验告诉我要不了几个月我就会发现这些问题死气沉沉了,而且还会经常打错它们。我认为主要原因是这些问题与我的其他兴趣太不相关了,我会丢掉当时使我感兴趣的情景。
我把这些称作编外问题,因为它们与我记忆中的其他东西都不相关。Anki 几个编外问题并不算太糟 —— 预先很难知道哪些会变成慢慢消退的兴趣,哪些又是会变成与我的其他兴趣相关联的真正兴趣。但是如果你的牌组中不可忽略的一小部分都是孤儿问题的话,那么这意味着你得把 Anki 问题集中到与你的创造性工作相关的方面来,减少 Anki 偏离主题的材料。
避免孤立编外问题(与其他一切都不相关的单个问题)尤为重要。比方说,我正在读一篇关于一个新主题的文章,我学到一个看起来尤其有用的知识。我会定下一个规矩永远不只输入单个问题。反之我会输入至少两个问题,三个以上更佳。对于某则有用知识的核心来说这一般足够了。对于孤儿问题,我会不可避免地经常答错它们,输入它们本身就是浪费时间。
不要分享牌组:我经常被问愿不愿意分享我的 Anki 牌组。我不愿意。很早开始我就意识到把个人信息放进 Anki 会很有用。我不是说我会往里面放极其私人的东西,我永远也不会往里面加入深藏心底的黑暗秘密。我也不会放需要安全保障的东西,例如密码。但是我确实会输入一些不会轻易吐露的内容。
例如,我有一个表面上有魅力而且很了不起的同事名单(很短!),我永远不会与他们共事,因为我经常看到他们糟糕地对待其他人。Anki 这些相处细节挺有用的,这让我能记住为啥要远离这个人。这不是适合轻易传播的信息:我可能曲解了别人的行为,或者误解了当时的情境。但是于我个人来说把它们放 Anki 里还有有用处的。
自己建牌组:Anki 网站上有很多共享牌组,但是我没发现有很多用处。最重要的原因是制卡本身就是理解的一部分。也就是说,想出如何得出好问题和好答案是深入理解一项新材料的一部分。用别人的卡片相当于丢掉了大部分理解。
事实上我想当制卡行为本身就能帮助记忆。记忆研究者反复发现对记忆的编码越精细,记忆也就会更持久。精细的编码本身就相当于你构造的联系的丰富程度。
比如,对于 1962 年第一颗通信卫星 Telstar 升入轨道这一事实,你可以把它记忆为孤立的事实。更好的途径是把它当成与其他事实相关的内容来记。略显乏味地,你可能发现 Telstar 是在苏联的第一颗卫星 Sputnik 五年后发射的。还有个不那么乏味的更丰富阐述,我发现 Telstar 居然是在 ASCII 编码(第一个当代数字文本通信标准)引入的前一年升入轨道的,这真是太有意思了。人类居然在有数字文本通信标准前就有了通信卫星。找到这种联系是精细编码的一个例子。
制卡这个行为本身几乎总是精细编码的一种形式。这强迫你考虑各种不同的问题形式,想出最佳答案,等等。我认为对于大多数初级卡片这也是正确的。对于更复杂的需要将基本事实与其他想法联系起来(就像 Telstar 和 ASCII 的联系)并构成相互关联的丰富想法网络的复杂卡片这就更确凿无疑了。
不过还是存在有一些有价值的牌组分享行为的。比如有些医学生发现相互共享并时常合作制卡是有价值的。我本人也会发现一些包含初级问题的共享牌组的价值,比如问题是谁画了哪幅画的艺术牌组。对于更深层的理解,我还没找到如何利用共享牌组的方法。
培养精细编码/构造丰富联系的策略:这其实是个元策略,用来构造策略的策略。一种简单的示例策略是:使用“相同”问题的多个变体。比如我前面提到过的两个问题,“对于 1980 年到 2011 年间诺贝尔物理学奖获得者做出其获奖成果时的平均年龄,Jones(作者)有哪些结论?”和“哪篇论文声称 1980 到 2011 年间诺贝尔物理学奖获得者做出其获奖成果是的平均年龄是 48 岁?”。逻辑上这两个问题显然是紧密联系的。但是对于记忆机制来说它们是不一样的,它们在不同的方面触发联系。
怎么看待记忆宫殿以及类似技巧?有一系列基于记忆宫殿和轨迹法之类思路的著名记忆技巧。这是精细编码的极端形式,对于你想记住的材料构造丰富的图像和空间联系。下面是余时行对忆术家 Ed Cooke 关于一项基本技巧的谈话的转述(译注:这里为了符合中文修改了原文):
Ed 然后向我解释了他让名字难以忘记的程序,他在比赛中使用这个程序记住了 99 个姓氏名字和与之对应的面孔照片。他保证这种技术可以让我记住聚会和会议中人们的名字。 “这个伎俩实际上很简单,”他说。 “总是将一个人的名字的声音与你能清楚想象的东西联系起来。这一切都是为了在你的脑海中创造一个生动的图像,将你对人脸的视觉记忆锚定在与人名相关的视觉记忆中。当你需要在以后的某个时间返回并记住这个人的名字时,你创建的图像会直接回到你的脑海中......所以,嗯,你说你的名字是余时行,是吗?“他抬起眉毛给了他的下巴一个戏剧性的抚摸。 “我会把房间想象成鱼缸,然后聚会时你就像一条鱼一样在鱼缸里时常游走。这幅画面会比你的名字更加有趣,很容易记住“。
我试验过这些技巧,很有趣,但是只适用于记忆简单事实 —— 一副牌的顺序/一组数字等等。这些技巧不太适用于更抽象的概念,这些抽象通常是最深刻的理解所在。这样看来,这些技巧可能反而会干扰理解。和 Anki 一样,可能我就是需要找到更好的方式运用这些技巧而已。继续深入探索一些记忆术练习者用来构造丰富联系的技巧也许尤其有价值。就像 Foer 在引述一位记忆专家时所说的,“用更难忘的方式思考”。
Anki 95% 的价值来自于 5% 的特性:Anki 可以自动制卡,可以为卡片加标签,有插件系统,还有更多。实际中我基本不用这些特性。我的卡片主要是两种类型:绝大多数是简单的问答卡片;然后有小部分是填空卡:类似于完型测试。比如给我最喜欢的名言挖空:
“如果个人计算机真的是一种____,那么
其应用将会改变____的_____”
____,_____
(答案:媒介,整个社会,思维模式,
Alan Kay,1989)填空也能用来提不包括名言的问题:
Adelson 错觉又称为 ______ 错觉。
(答案:棋盘阴影)为什么不使用更多的 Anki 功能呢?部分原因是仅仅使用核心功能我就已经获得巨大的好处了。更进一步,用好这一点核心功能就已经很花功夫了。篮球和篮筐是简单的装备,但你可以花一辈子去学会用好他们。同样的,基本 Anki 操作可以发展到很高的程度。所以我专注于学会用好这些基础功能。
我知道很多尝试 Anki 的人会掉进无底洞,不断学习尽可能多的特性从而提高“效率”。他们通常在追求 1% 的改善。通常最终因为“太难”而放弃 Anki 的人其实是说“我还没达到完美使用的状态,好紧张”。真是可惜。如前所述,Anki 相比于传统闪卡要高效大约 20 倍。所以他们是因为最终的 5%、1% 和很多情况下 0.1% 的改善而放弃了 2000% 的提升。程序猿似乎特别容易掉进这种无底洞。
鉴于这个原因,我会建议刚开始用的人不要使用任何高级特性,不装任何插件。不要在短期内成为程序员效率病的反面教材。学习基础问答卡,在此范式内探索新的使用模式。这会远比花数小时折腾各种功能好。接着,如果你已建立高质量的 Anki 日常习惯,可以去试验更多高级特性。
用 Anki 存储亲朋好友信息之挑战:我试验过用 Anki 存储亲朋好友的(非敏感!)信息。“【我的朋友】是素食者吗?”这类问题感觉还行。但是我却在更尖锐的问题上搁浅了。比如我与某个新朋友讨论他们的孩子,但是却从来没见过他们的孩子。我也许会输入“【朋友】家最大的孩子的名字是?”或者如果我们讨论音乐,我会输入“【朋友】最喜欢的音乐家是?”
这类试验目的明确。但是问出这类问题让我感到不安。有点像假装对朋友们的兴趣。有种强烈的社交规范是,如果你记得朋友的品味和小孩姓名,那是因为你对他们感兴趣。至少对我来说,用记忆辅助会有点不真诚的感觉。
我跟几个朋友谈过这个问题。多数人告诉我同样的话:他们感激我费了这么大的劲,同时觉得我那么担心是不是不真诚这件事挺有魅力。所以也许担心是不必要的。然而,我还是有些迟疑。我把 Anki 用于不那么私人的东西上 —— 例如人们的事物偏好。也许日后我会存储更加私人的信息。目前我还是慢慢来吧。
程序记忆与陈述记忆:记住事实与掌握过程有天壤之别。例如,被某个 Anki 问题提示后你可以想起某个 Unix 命令,但是这并不意味着,你可以在命令行情境下,想到使用这个命令的机会,并自如地敲出它。而且,通过有创意地组合你知道的命令,从而解决富有挑战性的问题仍然是另外一回事。
好了,我发现其实转移过程还算简单。对于命令行,我一般会有足够的机会去运用 Anki 化的命令行知识。随着时间退役,陈述性知识变成了我经常实际运用的过程性知识。嗯,还是希望能知道什么时候转移会发生什么时候不会发生。如果能有系统能集成到我的真实工作环境就更好了。比如在真实的命令行提问我 Unix 命令相关问题。或者在命令行让我解决一些高阶问题。
我在这条道路上做过一次尝试:复习卡片时模仿输入命令的动作。我的主观感受是好像不太管用,而且做起来也很烦人。所以我弃坑了。
抛弃“名称无关紧要”的想法:我的本行是理论物理家。物理学界有个 Richard Feynman 讲的著名故事。Feynman 小时候在田野里和另一个万事通小孩玩。Feynman 讲述了当时的经过:
有个小孩跟我说:“看到那只鸟了吗?那是什么鸟?”
我说:“我根本不知道那是什么鸟。”
他说:“那是棕喉画眉。你爸啥都没教你。”
其实正好相反。他(Feynman 的父亲)早就教过我了:“看见那只鸟了吗?那是一只 Spencer's warbler。(他其实不知道那只鸟的名字)嗯,在意大利语里它叫 Chutto Lapittida。在葡萄牙语里它叫 Bom da Peida。在中文里它叫 Chung-long-tah。在日语里它叫 Katano Takeda。你可以知道这种鸟在全世界所有语言里的名字,但是到了最后,你却对它一无所知。你只知道不同地方的人,以及他们如何称呼这种鸟。所以我们来看看它会做哪些事情。那才是重要的!”(我很早就知道了知道事物的名称和知道事物本身的区别。)
Feynman(或者他父亲)接着讨论了什么是真正的知识:观察行为,了解原因,等等。
这是个好故事。但是有点矫枉过正:名字其实是重要的。也许没万事通小孩想得那么重要,通常事物的名字也不包含深刻的知识。但是它们确是让你能构建知识网络的基础。
在科学训练期间,我一直不停地被告知名字无关紧要这个比喻。刚开始用 Anki 的时候,我觉得输入关于名字的问题有点傻。现在我可以热情高涨地做这件事了,因为我知道这是通向理解的初期环节。
Anki 适用于各类事物的名字,不过我觉得对于非言语类事物尤为有用。比如,我会输入关于艺术作品的问题:“Emily Hare 的作品《嗥》是什么样的?”答案:

输入这个问题有两个原因。主要原因是我想时不时地回忆起这幅画作的体验。另外我想给画作赋予一个名称。如果我对画作做更多的分析 —— 比方说其巧妙的色彩过渡运用 —— 我可以添加更细致的问题。但是将画作的体验置入大脑已经足够开心了。
没跟上复习进度怎么办?在没跟上卡片进度后 Anki 会变得困难。跳过一两天或者半个月后卡片就会堆积起来。回来之后发现每天要复习 500 张卡,这是很吓人的。更糟的是,如果中断了 Anki 习惯,会掉队很长一段距离。在七个月内,我几乎没用过 Anki,回来发现几千张堵塞的卡片。
不过还好,补回进度并不是太难。我为自己设定了一个逐渐增长的每日配额(100,150,200,250,直到 300),按计划刷卡数周,直到补回进度。
虽然并不是太难,这还是有点消磨士气。我希望 Anki 有个“补进度”的功能,能将堆积的卡片分散在接下来的几周内。但是它没有。这是个陷阱,不过不是很难解决。
编程接口、书籍、视频、研讨会、对话、网页、事件、地点:几乎所有之前关于 Anki 论文的讨论都可以应用到其他资源上。这里有一些小贴士。关于编程接口的讨论我放到了附录里,如果感兴趣可以去看(译注:附录请看原文)。
对于研讨会和同事间的交谈,我发现设置 Anki 配额意外的好用。例如对于研讨会我会尽量找出至少三个可以 Anki 化的高质量问题。对于长篇交谈,至少一个高质量问题。设置限额让我更加专心,特别是研讨会期间。(我觉得一对一的对话期间更容易保持专注。)
对于视频、时间和地点,我更加随意。理想情况下出行和去新餐馆之后系统化地 Anki 3 到 5 个问题会比较好,这让我记住当时的体验。有时我会这么做。但是还不够系统化。
对于论文和书籍我倾向于在当时就制卡。对于研讨会和交谈,我更喜欢沉浸其中。相比于直接拿出 Anki,我会脑海或者纸上快速设想我要 Anki 的问题。随后我便将其输入 Anki。这需要一些自律。所以我一般会设置较低的限额,这样我只需要输入几个问题就行,而不是几十个。
关于书籍要注意:读一整本书是项大投入,时常加 Anki 问题会显著减慢阅读速度。决定 Anki 哪些内容时需要将此牢记于心。有时一本书优质内容的密度是如此之大以至于值得花时间去添加很多问题。但是无脑 Anki 眼前的所有内容是坏习惯,我也偶尔会这样。
决定 Anki 哪些内容并不是简单的选择:去 Anki 能协助长期目标的东西。某种角度上我们记得什么,我们就成为什么,所以对于记忆一定要倍加谨慎。这一直是正确的,但 Anki 让这句话变得更加正确了。
好了,另一个有趣的模式是翻出以前的前 Anki 时代的读书笔记,然后 Anki 它们。这可以很快地完成,而且让在快忘光的书上投入的时间变得更有回报了。
我没有搞清楚怎么将创造性工作时的笔记和 Anki 集成起来。我没法用 Anki 代替笔记,太慢了,而且很多东西并不适合占用我的长期记忆。另一方面,Anki 重要条目也会带来诸多好处 —— 对记忆的流畅读取是很多创意想法的基础。实践中,我会凭直觉非系统化地将一些东西做笔记另一些做 Anki,还有一些两者都做。总体上效果不错,但是我觉得如果能应用一些更系统化的思考和试验会更好。部分原因是归根结底我根本没有很好的笔记系统。如果这个问题解决了,我猜整个事情会变得更好。好吧,目前还凑合。
避免判断题:有个我时常陷入的坏习惯是有很多答案是“是与否”的卡片。例如,学习机器学习里的图模型的时候,我加过一个不太好的问题:
计算分区函数对大多数图模型
来说是难以处理的吗?答案是“是”。就其本身来说,无伤大雅。但是如果能深入阐述提问里包含的思想会帮助更大。可以加个问题提问哪些图模型的分区函数是难以处理的。可以给出一个难以处理的图模型的例子吗?分区函数的计算难以处理到底是什么意思?进行问题重构时,应当优先考虑重构判断题。
难道外部记忆辅助还不够吗?对于 Anki 这种系统的常见批评是,谷歌、维基和笔记本这种外部记忆设备已然足够。当然,用好这些系统是对 Anki 的极好辅助。但是对于创造性工作和问题解决,内化的理解有其特殊作用。它确保关联思考的速度,让人能够快速尝试点子的组合,凭直觉发现模式,这些在你费劲地查找信息时都不可能实现。
流畅度对于思考举足轻重。Alan Kay 和 Adele Goldberg 提出了一项关于长笛的思想实验,此长笛“吹奏音符和听到声音之间存在一秒的延时”。他们发现这简直是“荒谬”的。类似的,某些类型的思考在全部相关领悟都已经在脑海时是最容易的。对此,Anki 简直是无价之宝。
既然个人记忆系统这么强,为何没有被更广泛的使用呢?这个问题类似于那个陈年笑话。两个经济学家一起走路的时候,其中一个发现地上有 20 美元钞票,“瞧,地上有 20 美元!”另一个回答道:“不可能!要是真有,早就有人捡走了。”
这个类比是不完全的。实际上,Anki 似乎是躺在地上的一串 20 美元钞票。为什么没有更广泛应用的疑问是有理有据的。相关文献中引用最高的文章之一讨论为什么这种思路没有在教育系统更广泛的应用。虽然发表于 1988 年,我觉得其中大部分见解在今天依然成立。
个人推测主要有三大原因:
- 在关于记忆的实验中,人们一致低估了像 Anki 那样分散式学习的成效。他们更喜欢临时抱佛脚,认为可以取得更好的效果,虽然很多研究显示并不会。
- 心理学家 Robert Bjork 提出过“理想难度原理”,即遗忘边缘时的测试会最大程度地强化记忆。这暗示高效的记忆系统必然在本质上是艰难的。人类与有难度的活动的关系是复杂的,大多数时候并不想执行他们,除非动机强烈(这时困难活动可能变得愉悦了)。
- Anki 这样的系统用好很难,用坏简单。
考虑开发一个克服这些问题的系统会很有意思。
第二部分:更广义的个人记忆系统
在本文第一部分,经由我的个人经验,我们探讨了特定的个人记忆系统 Anki。在更短的第二部分,我们会考虑关于个人记忆系统的两个更宽泛的问题:记忆对于认知能力有多重要?开发个人记忆系统时,认知科学应扮演什么样的角色?
长期记忆到底有多重要?
长期记忆经常被抨击。经常有人贬低“死记硬背”,特别是在课堂上。我听说过很多人退出某些课程——常见于有机化学——因为“这就是些知识点,我想要包含更多理解的课程”。
我不会为糟糕的课堂教学或者是有机化学常见的教学方式做辩护。然而低估记忆的作用是个错误。我曾相信“记忆不重要”这样的陈词滥调。但现在我相信记忆是认知的基础。
改变的原因主要有两方面,其一是个人经验,其二是来自认知科学的证据。
让我从个人经验开始。
多年来,我经常指导别人学习量子力学这样的技术科目。时间久了你就会理清人们止步不前时的模式。某个共通的模式是人们会认为难住他们的是某些奇异复杂的问题。但是深挖过后就会发现他们对基本符号和术语的掌握有困难。如果每三个单词或者符号你就搞不懂,那你很难理解量子力学。每个句子都是煎熬。
就好比他们想要用法语作一首美妙的十四行诗,却发现只会 200 个法语单词。他们沮丧,觉得问题出在找到好的主题,生动的情感和意向等等。然而问题其实是他们只有 200 个单词来作诗。
我虔诚地相信如果人们对基础记忆多些关注,少去担心“困难”的高阶问题,他们会发现这些高阶问题迎刃而解。
虽然对他人有这种强烈的信念,我从未意识到它也能适用到我自己身上。并且我也对其适用于我的程度一无所知。用 Anki 读新领域文献让我破除了这个错觉。Anki 让学习这类科目变得如此更加容易,这让人坐立不安。现在我相信记住基础是理解的最大难关。如果你用类似于 Anki 的系统克服这个难关,你会发现阅读进入新领域变得更加更加简单。
Anki 使学习新的技术领域变得容易得多的经历让我更加发自肺腑地欣赏记忆的重要性。
同时也有很多来自于认知科学的结果显示了记忆对于认知的关键作用。
有条惊人的研究路线是由研究者 Adriaan de Groot 和 Herbert Simon 分别做出的,他们研究人们是怎么获得专家级技能的,尤其关注国际象棋领域。他们发现世界级棋手看待棋盘的方式是和新手不同的。新手会看到“一兵一车”等一系列单独的棋子。大师则看到更加精妙的“组块”:他们识别为单位的棋子组合,由此可在比单个棋子更高的抽象层次上推理。
为什么学习识别和推理这样的组块非常有利于培养专家技能呢?这里有个就我目前所知臆测且随便的模型,没被认知学家验证过,所以不要太当真。我会在数学专业的上下文描述它,因为我有跟各个层次的人讨论数学的经验,从初学者到功成名就的专业数学家。
很多人会认为卓越数学家的成功模式是惊人的智慧,高智商,能在脑中处理复杂的问题。有种常见的认知是他们的聪慧给了他们处理复杂问题的能力。简单来说就是他们的引擎马力更足。
一流数学家的确更聪明这是事实。但是也有另一种解释。如 Simon 所说,很多顶尖数学家比常人内化了更多的复杂数学组块。这意味着对我们很复杂的问题对他们很容易。他们处理复杂性的能力并不等于马力更大的大脑。而是前期的学习让他们有更好的组块能力,大多数人觉得复杂的情况他们会觉得简单,也更容易进行相关推理。
Simon 所用的“组块”的概念其实来源于 George Miller 的著名论文,“魔力数字,七加正负二”。Miller 提出工作记忆的容量大致为 7 个组块。事实上后来发现这个数字在人与人之间是有区别的,且工作记忆与一般智力水平(IQ)呈显著正相关。工作记忆越大,智商越高,反之亦成立。Miller 所说的组块到底指什么还是有些模糊不清,他写道:
单元与组块的对比也强调了一个事实,即我们其实不是很确定信息组块的构成。例如 Hayes 所得到的 5 个单词的记忆范围也可以说成是 15 个音素,因为每个单词大概有 3 个音素。直觉上很显然被试者回想起的不是 15 个音素,而是 5 个单词,但是其逻辑差异却不是显然的。我们面对的是讲输入组织和归类到熟悉的单元和组块的过程,学习很大程度上就是这些熟悉的单元的形成过程。
换句话说,对于 Miller 来说记忆组块其实就是工作记忆的基本单元。所以 Simon 和协作者们研究的其实是象棋棋手工作记忆的基本单元。如果这些组块更复杂,那么棋手的工作记忆就会在效用上更高。特别是,如果某人智商比较低却能记住更复杂的组块,他会比智商高但是内化组块复杂度低的人更能进行复杂情境推理。
也就是,某些领域内记得更多的组块相当于提升在这里领域的智商。
好的,这是个臆测且随意的模型。不管对不对,内化高阶组块都是获取专家级技能的关键部分。然而,这并不意味着使用 Anki 这样的系统就能加快组块的习得。这个模型的论点仅仅是长期记忆在某些专业技能的习得是扮演重要角色。不过,日常使用 Anki 这种系统还是有可能加快专家组块的习得的。这些组块是认知的核心,包括理解能力,问题解决能力,创造能力。
分布练习
Anki 为什么有用?本节简略探讨来自认知科学的关键思想之一,“分布练习”。
假设聚会上你被介绍了参与者的名字,他们也告诉你他们的名字。如果你留意了,他们的名字也不是太怪,那么 20 秒后你几乎肯定还记得他们的名字。但是一小时后你更可能忘掉名字,一个月后就更加可能了。
记忆会衰退。这不是什么新闻!但是德国心理学家 Hermann Ebbinghaus 用系统化和量化的方法研究了记忆衰退。特别地,他对衰退的速度和原因感兴趣。为此,Ebbinghaus 背诵“fim”和“pes”这样的随机音节,并随后自我测试,记录不同间隔后的记忆留存情况。
Ebbinghaus 发现正确回忆某项内容的记录是(大致)随着时间指数下降的。如今这被称为“Ebbinghaus(艾宾浩斯)遗忘曲线”。
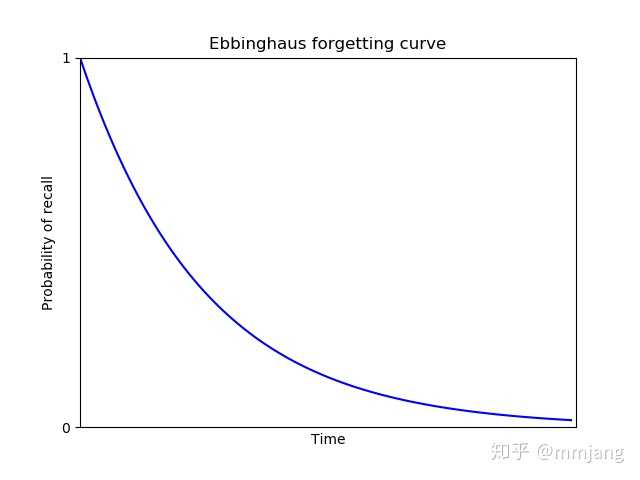
什么决定了曲线的陡峭程度(记忆衰退的速度)?实际上陡峭程度关乎多项因素。例如,对于复杂或陌生的概念曲线会愈陡。你也许会觉得跟以前听过的类似的名字会更好记住:比方说郭时行就好记,而西力甫尼加提就不行。所以它们的曲线就会更平坦。类似的,你可能觉得图像比声音更好记。或者觉得声音比运动技巧更好记。另外如果你用了记忆术这种精巧的记忆方法,或者想办法与已有知识联系起来,你可以将曲线变平坦。
假设你有人向你介绍了参加聚会者的名字,之后的二十分钟你都没想过他们的名字。然后你需要把参加者名字介绍给另外一个人,所以需要去回忆这些名字。在此之后的一小段时间你回忆出来名字的概率会再次变得很高。Ebbinghaus 的研究发现重新测试后记忆率会再次按指数下降,但是这次下降的速度会比初始速率低。事实上,接下来的重测会让记忆衰退速度更加慢,衰退曲线随着多次回想加固的记忆而逐渐变得平坦。
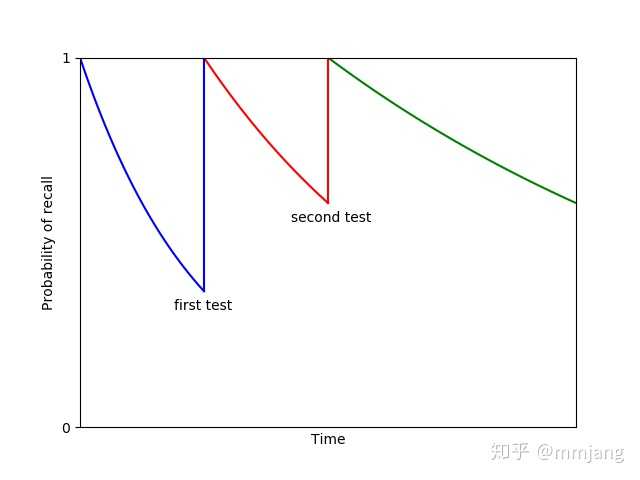
衰退时间的逐渐增长是 Anki 和类似记忆系统的基础。这就是 Anki 逐渐增长测试间隔的原因。
这个现象也是科学家广泛研究的一组理论的一部分。这组现象有好多相关名词,但我们只会用“分布练习”这个词,它指在时间上分布的练习,这种练习最好设计为能最大程度促进记忆留存。这和抱佛脚行为,把全部内容塞进一次学习时段并依靠重复的集中练习,形成对比。
认知科学在认知增强系统设计的作用
Ebbinghaus 之后,有数以千计的研究分布练习不同变种的研究。这些研究揭示了很多长期记忆的相关现象。最重要的是,这些研究强有力地证明了分布练习比集中练习效果优异。人们也许会想跳入这片文献之海然后用其指导记忆系统的设计。但是同时还值得考虑下这些文献作为系统开发指导的局限性。
虽然科学家对于分布练习做了数不清的相关研究,很多关于分布练习的基本问题还是不甚明晓。
我们还不明白记忆的指数衰退的原因细节,也搞不清什么时候这个模型会不适用。我们没有关于衰退速度决定因素的恰当模型,以及为什么不同类型的记忆衰退速率不一样。我们不清楚为什么随后的回忆会使衰退时间变长。我们对扩展练习间隔的最佳方式也知之甚少。
当然,存在很多不完整的理论能回答这些或其他基本问题。但是不存在一个可进行量化预测且被广泛接受的理论。从这个角度,我们对分布练习几乎一无所知,距离完善的理解可能还有几十年的时间。
为了更具体地阐释这个观点,让我再举一个例子:有时候记忆并不会随着时间衰退,反而会增强,就算我们没有做过明确的回忆行为。你可能在自己的生活中也注意到过这种情况。心理学家 William James 曾开玩笑说(据他说引用自一位未给出名字的德国作家):
我们在冬天学会游泳,在夏天学会滑冰。
实际上这种效应被 Axel Oehrn 1895 年的一项实验研究证实过。虽然后续研究也确认了这项结果,但是这个效应却对记忆材料、具体的间隔和其他一些变量十分敏感。这在某种程度上与 Ebbinghaus 的指数遗忘曲线矛盾了。在实践中,一个不错的假设是 Ebbinghaus 曲线大体上是正确的,但是对于一些特定材料的少数情况,例外也存在。
说这个不是为了让你开始怀疑 Ebbinghaus 的模型。只是作为警醒:记忆是复杂的,很多大问题还未被解答,在过于信任某个单一模型之前应该小心。
总结来说:分布练习和 Ebbinghaus 遗忘曲线的基本效应是真实、显著、被大量实验证实的。Oehrn 发现的这种效应相比之下没那么重要。
这把我们置入一个有趣的境地:我们对记忆有足够的理解从而得出 Anki 这样的系统会很有用的结论。然而开发此类系统时的很多设计选择却是权宜之计,基于直觉和未被证实的假说。科学文献中的实验还没证实这些设计选择。原因在于这些实验目的并不是验证这些问题。这些实验关于记忆某些特定类型的信息。或者它们只关注一天或一个星期内的短期记忆,而不是数年。这些工作对于发展更好的记忆理论是帮助用的,但是并不一定能回答系统设计师的问题。
于是,系统设计师必须另谋他路,借助非正式的实验和理论。例如 Anki 的间隔算法就是基于 Piotr Wozniak 的个人实验。虽然 Wozniak 发表了几篇论文,它们却是非正式的报告,没有遵循认知科学文献的准则。
在某种意义上,这并不能使人满意:我们不明白用什么间隔时间表比较好。但是系统又必须用到某些时间表,所以设计者只能尽力而为。这看起来比原始方法要好,但长期来看,最好还是有基于人类记忆详细理论的方法。
有种观点是说你必须科学地设计,一切设计选择都应有实验支撑。我听过用这种观点作为对 Anki 这种系统者的批评,说他们做了太多将就的猜测,而不是基于系统化的科学理解。
但是,他们该怎么办呢?等上 50 或 100 年,直到答案出现?放弃设计,用今后的 30 年成为记忆科学家,然后给出设计系统时出现的问题的“科学”答案?
设计不是这样进行的,也不应这样进行。
如果设计者一直等待所有证据出现,那么根本不会有人设计出任何东西。实践中你想要的应该是大胆且充满想象力的设计,探索新想法,同时知悉(而不受限)当前的科学进展,从中激发灵感。理想情况下,伴随于此的是一个较慢的反馈环,设计选择提出对于记忆的疑问,从而导致新的科学实验,从而导致对记忆更完善的理解,从而又引发新一轮设计。
这种平衡难以实现。脑机交互社区构建他们的系统时做到了这一点,不仅仅是对于记忆,而是对于一般意义上的人类认知增强。但是我认为他们做的不够好。我觉得他们在设计时放弃了太多的大胆与想象。同时,他们搞的也不是真正的认知科学研究,他们不是在探索对于心智的详细理论。找到充满想象的设计和认知科学之间恰到的关系是认知增强工作的核心问题,这并不是简单的事。
与此相似,人们也会忍不住想象认知科学家开始构建系统。这有时可能会起作用,但我认为大多数情况下并不会得到好结果。构建有效的系统,就算是原型,都是困难的。认知科学家总体上缺乏做好这件事所需的技巧和设计想象。
这使我认识到我们需要关于人类增强的另外一个领域。该领域从认知科学获取输入。不过该领域本质上是一门设计科学,面向大胆而富有想象的设计,构建从原型到大规模部署的系统。
致谢
Gwern Branwen, Sasha Laundy 和 Derek Sivers 的文章是导致我当初被 Anki 迷住的部分原因。感谢 Andy Matuschak、Kevin Simler、Mason Hartman 和 Robert Ochshorn 关于本文激发灵感的讨论。尤其感谢 Andy Matuschak 充满思想且愉悦的对话,特别是他指出把 Anki 作为一项协助理解的精湛技巧而不仅仅是记忆知识点的方法的观点是多么非同寻常。最后,谢谢所有在推特上回复我 Anki 帖子的人。