
求求你们来做点新数据集、新任务上的工作吧!(顺带 sell 一下我的 work)
在间隔重复领域对学生记忆的时间序列预测任务
项目地址:open-spaced-repetition/srs-benchmark: A benchmark for spaced repetition schedulers/algorithms
引言
间隔重复算法(Spaced Repetition Algorithms)是一种计算机程序,旨在帮助人们规划抽认卡(flashcards)的复习安排。优秀的间隔重复算法能助你更高效地记忆。它并非让用户进行一次性的突击记忆(cramming),而是将复习活动分散到不同的时间点。为了实现高效复习,这些算法试图理解人类记忆的运作机制,旨在预测你可能遗忘某个知识点的时间点,以便据此安排下一次复习。
本基准测试旨在评估各种算法的预测准确性。我们评估了多种算法,以期找出能提供最准确预测的算法。
数据集
SRS 基准的数据集来自 1 万名使用 Anki(一个开源的抽认卡应用)的用户。该数据集包含约 7.27 亿次复习记录。完整数据集托管在 Hugging Face Datasets 上:
open-spaced-repetition/anki-revlogs-10k · Datasets at Hugging Face评估
数据划分
在间隔重复系统(SRS)基准测试中,我们使用了一个名为 TimeSeriesSplit 的工具,它是机器学习库 sklearn 的一部分。该工具帮助我们按时间顺序划分数据:较早的复习记录用于训练模型,较新的复习记录用于测试模型。这样,我们就能避免通过让算法获取本不应得到的未来信息而「作弊」。实践中,我们正是利用过去的的学习记录来预测未来的学习表现,因此 TimeSeriesSplit 非常适合我们的基准测试需求。
注意:TimeSeriesSplit 在评估时会排除第一个数据分割。这是因为第一个分割用于训练,我们不希望在训练数据上评估模型的性能。
评估指标
我们在 SRS 基准测试中使用三个指标来评估算法性能:对数损失(Log Loss)、曲线下面积(AUC)以及一个我们称为「分箱均方根误差」(RMSE (bins))的自定义指标。
- 对数损失 (Log Loss)(亦称二元交叉熵):主要用于二元分类问题,对数损失衡量的是预测回忆概率与实际复习结果(1 或 0)之间的偏差。它量化了算法对真实回忆概率的拟合优度。对数损失的取值范围为 0 到无穷大,值越低表示性能越好。
- 分箱均方根误差 (RMSE (bins)):这是专为 SRS 基准测试设计的指标。该方法将预测结果和实际复习结果依据三个特征(复习间隔时长、复习次数、(记忆)中断次数)划分到不同的「箱」中。在每个箱内,计算平均预测回忆概率与平均实际回忆率之间的平方差。然后,根据每个箱内的样本数量对这些平方差进行加权,最终计算出加权均方根误差。该指标能够提供对算法在不同概率区间性能表现的更细致的理解。更多详情,请参阅该指标说明。RMSE (bins) 的取值范围为 0 到 1,值越低表示性能越好。
- AUC (ROC 曲线下面积):该指标衡量算法区分不同类别(在此场景下指回忆成功与失败)的能力。AUC 的取值范围为 0 到 1,但在实践中几乎总是大于 0.5;值越高表示性能越好。
对数损失和 RMSE (bins) 主要衡量校准度 (calibration):即预测的回忆概率与实际观测数据的一致性。AUC 主要衡量区分度 (discrimination):即算法区分两个(或更广义地说,多个)类别的能力。即使对数损失和 RMSE 指标表现不佳,AUC 也可能很高。
算法及算法家族
- 双组件或三组件*记忆模型:
- FSRS v1 和 v2:FSRS 的早期实验版本。
- FSRS v3:FSRS 算法的首个正式发布版本,以自定义调度脚本的形式提供。
- FSRS v4:FSRS 的升级版,在社区的帮助下进行了改进。
- FSRS-4.5:基于 FSRS v4 的微幅改进版,主要调整了遗忘曲线的形状。
- FSRS-5:FSRS 的升级版。与先前版本不同,它利用了当日复习数据。当日复习数据仅用于训练,不用于评估。
- FSRS-6:FSRS 的最新版本。改进了处理当日复习数据的公式。更重要的是,FSRS-6 引入了一个可优化的参数来控制遗忘曲线的平坦程度,这意味着不同用户的遗忘曲线形状可以不同。
- FSRS-6 default param.:使用默认参数的 FSRS-6。这些默认参数是通过在数据集中全部一万个用户数据集上运行 FSRS-6 并计算每个参数的中位数得到的。
- FSRS-6 pretrain:仅优化前 4 个参数(首次复习后的初始稳定性值),其余参数设为默认值的 FSRS-6。
- FSRS-6 binary:将「困难」和「简单」两种评级均视为「良好」的 FSRS-6。
- FSRS-6 preset:每个预设配置使用不同的参数。在 Anki 中,最少可以有一个预设配置,一个预设可以应用于多个牌组。
- FSRS-6 deck:每个牌组使用不同的参数。
- FSRS-6 recency:训练时根据复习记录的新近度进行加权的 FSRS-6,使得较早的复习记录对损失函数的影响更小,较新的记录影响更大。
- FSRS-rs:FSRS-6 的 Rust 语言移植版。另见:https://github.com/open-spaced-repetition/fsrs-rs
- HLR:由 Duolingo 提出的算法,全称为半衰期回归(Half-Life Regression)。更多信息请参阅这篇论文。
- Ebisu v2:一种利用贝叶斯统计在每次复习后更新记忆半衰期估计值的算法。
*在长期记忆的双组件模型中,使用两个独立变量描述人脑中单个记忆项目的状态:可提取性 (R),即检索强度或回忆概率;以及稳定性 (S),即存储强度或记忆半衰期。扩展的三组件模型增加了第三个变量——难度 (D)。
- 其他记忆模型:
- DASH:在这篇论文中提出的算法,其名称代表难度(Difficulty)、能力(Ability)和学习历史(Study History)。在我们的基准测试中,由于难度部分不适用于我们的数据集,我们仅使用了能力和学习历史部分。我们还增加了该算法的两个变体:DASH[MCM] 和 DASH[ACT-R]。更多信息请参阅这篇论文。
- ACT-R:在这篇论文中提出的算法。它包含一个基于激活的陈述性记忆系统,通过记忆痕迹的激活来解释间隔效应。
- 神经网络模型:
- GRU:一种循环神经网络,常用于基于数据序列进行预测。它是机器学习领域处理时间序列相关任务的经典模型之一。为使比较更公平,它采用了与 FSRS-4.5 和 FSRS-5 相同的幂律遗忘曲线。
- GRU-P:GRU 的一个变体,移除了固定的遗忘曲线,直接预测回忆概率。这使其比 GRU 更灵活,但也更容易产生奇怪的预测,例如预测回忆概率随时间增加。
- LSTM:一种比 GRU 架构更复杂、更精密的循环神经网络。它使用 Reptile 算法进行训练,并将短期复习记录、小数间隔以及复习时长作为其输入的一部分。 上述三种神经网络首先在 100 个用户的数据上进行了预训练,然后针对每个用户的数据单独进行了进一步优化。
- NN-17:SM-17 算法的神经网络近似。它具有数量相当的参数,根据我们的估计,其性能与 SM-17 相近。
- 基于 SM-2 的算法:
- SM-2:SuperMemo(首款间隔重复软件)早期使用的算法之一。它诞生于 30 多年前,至今仍广受欢迎。Anki 的默认算法基于 SM-2,Mnemosyne 也在使用它。该算法本身并不直接预测回忆概率;因此,为了进行基准测试,我们基于一些关于遗忘曲线的假设对其输出进行了修改。Piotr Wozniak 在此处描述了该算法。
- SM-2 trainable:具有可优化参数的 SM-2 算法。
- Anki-SM-2:Anki 中使用的 SM-2 算法变体。
- Anki-SM-2 trainable:具有可优化参数的 Anki 算法。
- 其他:
- AVG:一个输出恒定值(等于用户平均记忆保持率)的「算法」。没有实际应用价值,仅用作性能基线。
- RMSE-BINS-EXPLOIT:一种利用 RMSE (bins) 计算方式的算法,通过模拟分箱操作将误差项维持在接近 0 的水平。
关于 FSRS 算法的进一步信息,请参阅以下维基页面:该算法。
结果
总用户数:9,999。
用于评估的总复习次数:349,923,850。 当日复习数据不用于评估,但部分算法会利用这些数据来优化对次日回忆概率的预测。部分复习记录会被过滤掉,例如:手动更改到期日所产生的复习日志条目,或在禁用「根据我在此牌组中的答案重新安排卡片」选项的筛选牌组中复习卡片所产生的记录。最后,还会应用异常值过滤器。这些是导致用于评估的复习次数远低于之前提到的 7.27 亿的原因。
下表展示了各项指标的均值和 99% 置信区间。最佳结果以粗体标出。「参数」列显示了可优化(可训练)参数的数量,恒定参数不计入。箭头指示指标值越低 (↓) 或越高 (↑) 越好。
为简洁起见,「输入特征」列中使用了以下缩写:
IL = interval lengths, in days
FIL = fractional (aka non-integer) interval lengths
G = grades (Again/Hard/Good/Easy)
SR = same-day (or short-term) reviews
AT = answer time (duration of the review), in milliseconds
根据复习数量加权
| Algorithm | Parameters | Log Loss↓ | RMSE (bins)↓ | AUC↑ | Input features |
|---|---|---|---|---|---|
| LSTM | 8869 | 0.312±0.0078 | 0.035±0.0011 | 0.733±0.0038 | FIL, G, SR, AT |
| GRU-P-short | 297 | 0.320±0.0080 | 0.042±0.0013 | 0.710±0.0047 | IL, G, SR |
| FSRS-6 recency | 21 | 0.320±0.0081 | 0.044±0.0013 | 0.710±0.0040 | IL, G, SR |
| FSRS-rs | 21 | 0.320±0.0082 | 0.044±0.0012 | 0.709±0.0041 | IL, G, SR |
| FSRS-6 | 21 | 0.321±0.0083 | 0.046±0.0013 | 0.706±0.0041 | IL, G, SR |
| FSRS-6 preset | 21 | 0.322±0.0081 | 0.046±0.0013 | 0.707±0.0041 | IL, G, SR |
| GRU-P | 297 | 0.325±0.0081 | 0.043±0.0013 | 0.699±0.0046 | IL, G |
| FSRS-6 binary | 17 | 0.326±0.0081 | 0.049±0.0013 | 0.686±0.0047 | IL, G, SR |
| FSRS-5 | 19 | 0.327±0.0083 | 0.052±0.0015 | 0.702±0.0042 | IL, G, SR |
| FSRS-6 deck | 21 | 0.329±0.0082 | 0.052±0.0016 | 0.699±0.0041 | IL, G, SR |
| FSRS-4.5 | 17 | 0.332±0.0083 | 0.054±0.0016 | 0.692±0.0041 | IL, G |
| FSRS v4 | 17 | 0.338±0.0086 | 0.058±0.0017 | 0.689±0.0043 | IL, G |
| DASH-short | 9 | 0.339±0.0084 | 0.066±0.0019 | 0.636±0.0050 | IL, G, SR |
| FSRS-6 pretrain | 4 | 0.339±0.0084 | 0.070±0.0024 | 0.695±0.0039 | IL, G, SR |
| DASH | 9 | 0.340±0.0086 | 0.063±0.0017 | 0.639±0.0046 | IL, G |
| DASH[MCM] | 9 | 0.340±0.0085 | 0.064±0.0018 | 0.640±0.0051 | IL, G |
| GRU | 39 | 0.343±0.0088 | 0.063±0.0017 | 0.673±0.0039 | IL, G |
| DASH[ACT-R] | 5 | 0.343±0.0087 | 0.067±0.0019 | 0.629±0.0049 | IL, G |
| FSRS-6 default param. | 0 | 0.347±0.0087 | 0.079±0.0027 | 0.692±0.0041 | IL, G, SR |
| ACT-R | 5 | 0.362±0.0089 | 0.086±0.0024 | 0.534±0.0054 | IL |
| AVG | 0 | 0.363±0.0090 | 0.088±0.0025 | 0.508±0.0046 | --- |
| FSRS v3 | 13 | 0.371±0.0099 | 0.073±0.0021 | 0.667±0.0047 | IL, G |
| FSRS v2 | 14 | 0.38±0.010 | 0.069±0.0021 | 0.667±0.0048 | IL, G |
| NN-17 | 39 | 0.38±0.027 | 0.081±0.0038 | 0.611±0.0043 | IL, G |
| FSRS v1 | 7 | 0.40±0.011 | 0.086±0.0024 | 0.633±0.0046 | IL, G |
| Anki-SM-2 trainable | 7 | 0.41±0.011 | 0.094±0.0030 | 0.616±0.0057 | IL, G |
| HLR | 3 | 0.41±0.012 | 0.105±0.0030 | 0.633±0.0050 | IL, G |
| HLR-short | 3 | 0.44±0.013 | 0.116±0.0036 | 0.615±0.0062 | IL, G, SR |
| SM-2 trainable | 6 | 0.44±0.012 | 0.119±0.0033 | 0.599±0.0050 | IL, G |
| Ebisu v2 | 0 | 0.46±0.012 | 0.158±0.0038 | 0.594±0.0050 | IL, G |
| Anki-SM-2 | 0 | 0.49±0.015 | 0.128±0.0037 | 0.597±0.0055 | IL, G |
| SM-2-short | 0 | 0.51±0.015 | 0.128±0.0038 | 0.593±0.0064 | IL, G, SR |
| SM-2 | 0 | 0.55±0.017 | 0.148±0.0041 | 0.600±0.0051 | IL, G |
| RMSE-BINS-EXPLOIT | 0 | 4.5±0.13 | 0.0062±0.00022 | 0.638±0.0040 | IL, G |
未加权
| Algorithm | Parameters | Log Loss↓ | RMSE (bins)↓ | AUC↑ | Input features |
|---|---|---|---|---|---|
| LSTM | 8869 | 0.333±0.0042 | 0.0538±0.00096 | 0.733±0.0021 | FIL, G, SR, AT |
| FSRS-6 recency | 21 | 0.344±0.0041 | 0.063±0.0010 | 0.710±0.0023 | IL, G, SR |
| FSRS-rs | 21 | 0.344±0.0041 | 0.063±0.0010 | 0.710±0.0022 | IL, G, SR |
| FSRS-6 | 21 | 0.345±0.0042 | 0.066±0.0011 | 0.707±0.0023 | IL, G, SR |
| GRU-P-short | 297 | 0.346±0.0042 | 0.062±0.0011 | 0.699±0.0026 | IL, G, SR |
| FSRS-6 preset | 21 | 0.346±0.0042 | 0.065±0.0010 | 0.708±0.0023 | IL, G, SR |
| FSRS-6 binary | 17 | 0.351±0.0043 | 0.068±0.0011 | 0.685±0.0025 | IL, G, SR |
| GRU-P | 297 | 0.352±0.0042 | 0.063±0.0011 | 0.687±0.0025 | IL, G |
| FSRS-6 deck | 21 | 0.355±0.0045 | 0.074±0.0013 | 0.703±0.0023 | IL, G, SR |
| FSRS-5 | 19 | 0.356±0.0043 | 0.074±0.0012 | 0.701±0.0023 | IL, G, SR |
| FSRS-6 pretrain | 4 | 0.359±0.0044 | 0.083±0.0013 | 0.702±0.0022 | IL, G, SR |
| FSRS-4.5 | 17 | 0.362±0.0045 | 0.076±0.0013 | 0.689±0.0023 | IL, G |
| DASH | 9 | 0.368±0.0045 | 0.084±0.0013 | 0.631±0.0027 | IL, G |
| DASH-short | 9 | 0.368±0.0045 | 0.086±0.0014 | 0.622±0.0029 | IL, G, SR |
| DASH[MCM] | 9 | 0.369±0.0044 | 0.086±0.0014 | 0.634±0.0026 | IL, G |
| FSRS-6 default param. | 0 | 0.371±0.0046 | 0.097±0.0015 | 0.701±0.0022 | IL, G, SR |
| FSRS v4 | 17 | 0.373±0.0048 | 0.084±0.0014 | 0.685±0.0023 | IL, G |
| DASH[ACT-R] | 5 | 0.373±0.0047 | 0.089±0.0016 | 0.624±0.0027 | IL, G |
| GRU | 39 | 0.375±0.0047 | 0.086±0.0014 | 0.668±0.0023 | IL, G |
| AVG | 0 | 0.394±0.0050 | 0.103±0.0016 | 0.500±0.0026 | --- |
| NN-17 | 39 | 0.398±0.0049 | 0.101±0.0013 | 0.624±0.0023 | IL, G |
| ACT-R | 5 | 0.403±0.0055 | 0.107±0.0017 | 0.522±0.0024 | IL |
| FSRS v3 | 13 | 0.436±0.0067 | 0.110±0.0020 | 0.661±0.0024 | IL, G |
| FSRS v2 | 14 | 0.453±0.0072 | 0.110±0.0020 | 0.651±0.0023 | IL, G |
| HLR | 3 | 0.469±0.0073 | 0.128±0.0019 | 0.637±0.0026 | IL, G |
| FSRS v1 | 7 | 0.491±0.0080 | 0.132±0.0022 | 0.630±0.0025 | IL, G |
| HLR-short | 3 | 0.493±0.0079 | 0.140±0.0021 | 0.611±0.0029 | IL, G, SR |
| Ebisu v2 | 0 | 0.499±0.0078 | 0.163±0.0021 | 0.605±0.0026 | IL, G |
| Anki-SM-2 trainable | 7 | 0.513±0.0089 | 0.140±0.0024 | 0.618±0.0023 | IL, G |
| SM-2 trainable | 6 | 0.58±0.012 | 0.170±0.0028 | 0.597±0.0025 | IL, G |
| Anki-SM-2 | 0 | 0.62±0.011 | 0.172±0.0026 | 0.613±0.0022 | IL, G |
| SM-2-short | 0 | 0.65±0.015 | 0.170±0.0028 | 0.590±0.0027 | IL, G, SR |
| SM-2 | 0 | 0.72±0.017 | 0.203±0.0030 | 0.603±0.0025 | IL, G |
| RMSE-BINS-EXPLOIT | 0 | 4.61±0.067 | 0.0135±0.00028 | 0.655±0.0021 | IL, G |
按复习次数加权的平均值更能代表在有充足数据可供学习时的「最佳情况」性能。由于几乎所有算法在学习数据充裕时表现更佳,因此按复习次数(n(reviews))加权会使(代表误差的)平均指标值向更低(更优)的方向偏移。
未加权的平均值则更能反映「一般情况」下的性能。现实中,并非每个用户都拥有数十万条复习记录,因此算法并非总能完全发挥其潜力。
优越性
上文呈现的各项指标或许难以直接解读。为了更清晰地展示各算法间的相对性能,下图显示了算法 A(行)的对数损失值低于算法 B(列)的用户所占百分比。例如,FSRS-6-recency 相较于 Anki SM-2 算法的默认参数版本,在 99.6% 的用户数据集上表现更优,这意味着对于本基准测试中 99.6% 的用户数据集,FSRS-6-recency 能够更准确地估计回忆概率。但请注意,SM-2 算法最初并非为预测概率而设计,其在本基准测试中之所以能预测概率,完全是因为我们为其额外添加了计算公式。
此图表基于 9,999 个用户数据集生成。为提高图表的可读性,并未包含所有参评算法。
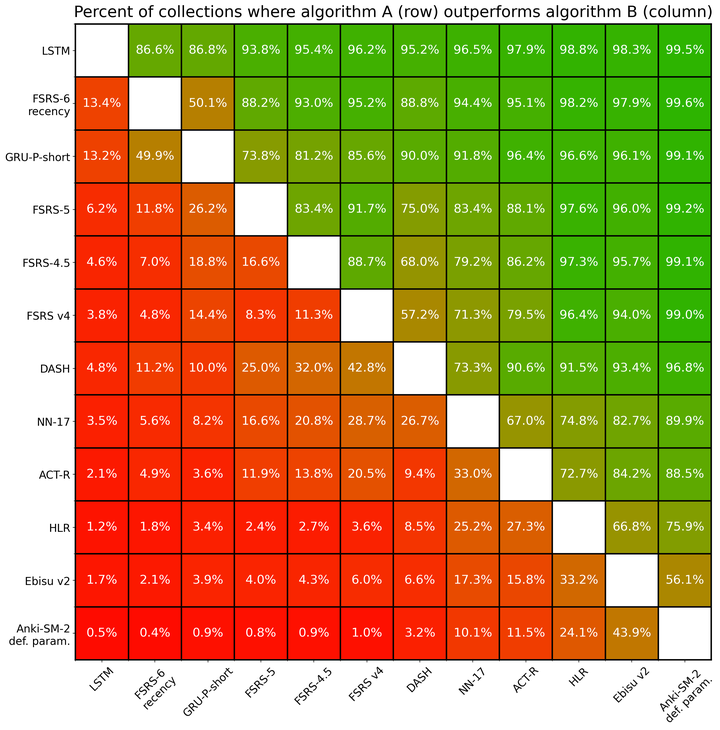
此外,你可以在此处找到完整表格。
统计显著性
下图展示了采用 Wilcoxon 符号秩检验比较任意两种算法间对数损失的效应大小(r 值):
颜色表示:
- 红色系表示行算法的性能劣于列算法:
- 深红色:大效应 (r > 0.5)
- 红色:中等效应 (0.5 ≥ r > 0.2)
- 浅红色:小效应 (r ≤ 0.2)
- 绿色系表示行算法的性能优于列算法:
- 深绿色:大效应 (r > 0.5)
- 绿色:中等效应 (0.5 ≥ r > 0.2)
- 浅绿色:小效应 (r ≤ 0.2)
- 灰色表示 p 值大于 0.01,意味着我们无法得出哪个算法性能更优的结论。
Wilcoxon 检验同时考虑了成对数据差值的正负号和秩次,但未考虑不同用户数据集中复习次数的差异。因此,尽管该检验结果对于定性分析是可靠的,但在解读具体效应大小时应持谨慎态度。
为提高图表的可读性,并未包含所有参评算法。
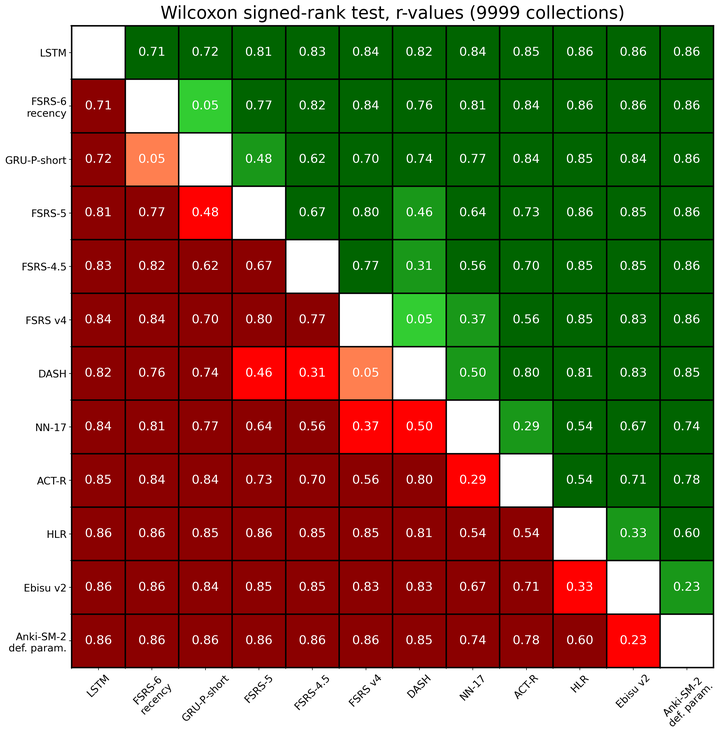
此外,你可以在此处找到完整表格。
我之前发表的相关论文:
KDD'22 | 墨墨背单词:基于时序模型与最优控制的记忆算法 [AI+教育] - 知乎Thoughts Memo:IEEE TKDE 2023 | 墨墨背单词:通过捕捉记忆动态,优化间隔重复调度相关研究资料:
Thoughts Memo:间隔重复记忆算法研究资源汇总我写的入门文章:
Thoughts Memo:间隔重复记忆算法:e 天内,从入门到入土。我的科研经历:
Thoughts Memo:我是如何在本科期间发表顶会论文的?(内含开源代码和数据集)