

我是叶峻峣,论文 A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling | Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 的第一作者,现就职于墨墨科技,主要负责墨墨背单词的记忆算法业务。关于我这篇论文的科研经历,请见:
我是如何在本科期间发表顶会论文的?(内含开源代码和数据集)《间隔重复记忆算法:e 天内,从入门到入土。》改编自我在墨墨内部介绍记忆算法的手稿,希望能让大家了解记忆算法到底在研究些什么,也希望能帮助更多研究者进入这一领域,推动学习技术的发展。废话不多说,让我们开始吧~
引言
从学生时代起,我们就隐隐约约察觉到以下两个事实
- 对一条知识多复习几次,就能记得更清楚。
- 不同的记忆有不同的寿命(记住一组知识后,它们将一条一条被遗忘,而不是作为一个整体完全丢失)
这两个事实常常引发我们思考
- 此刻的我们忘掉了多少知识?
- 我们遗忘知识的速度有多快?
- 怎样安排复习才能减少遗忘?
在过去,很少人去测量过这些指标,也少有人去根据具体的指标来安排复习。而记忆算法要研究的,正是如何描述与预测我们的记忆,并做出合理的复习安排。
接下来的 e 天,我们将从以下三个方面来了解记忆算法
- 经验算法
- 理论模型
- 前沿进展
为了让大家能更轻松地吸收这些知识,我在文章中嵌入不少助记卡片,不妨试试回答上面的问题。(需要访问 Thoughts Memo 小站获得完整阅读体验:Thoughts Memo (l-m-sherlock.github.io),知乎的表格不能插入公式,好不爽啊!)
Day 1 经验算法
今天我们从最简单的经验算法讲起,了解一下目前还在流行的一些算法细节和它们背后的思想。不过在此之前,我们先讲讲这些算法的通用名称——间隔重复——的由来。
间隔重复[1]
为了方便没有任何记忆相关基础知识的读者,我们先来认识一下遗忘曲线:
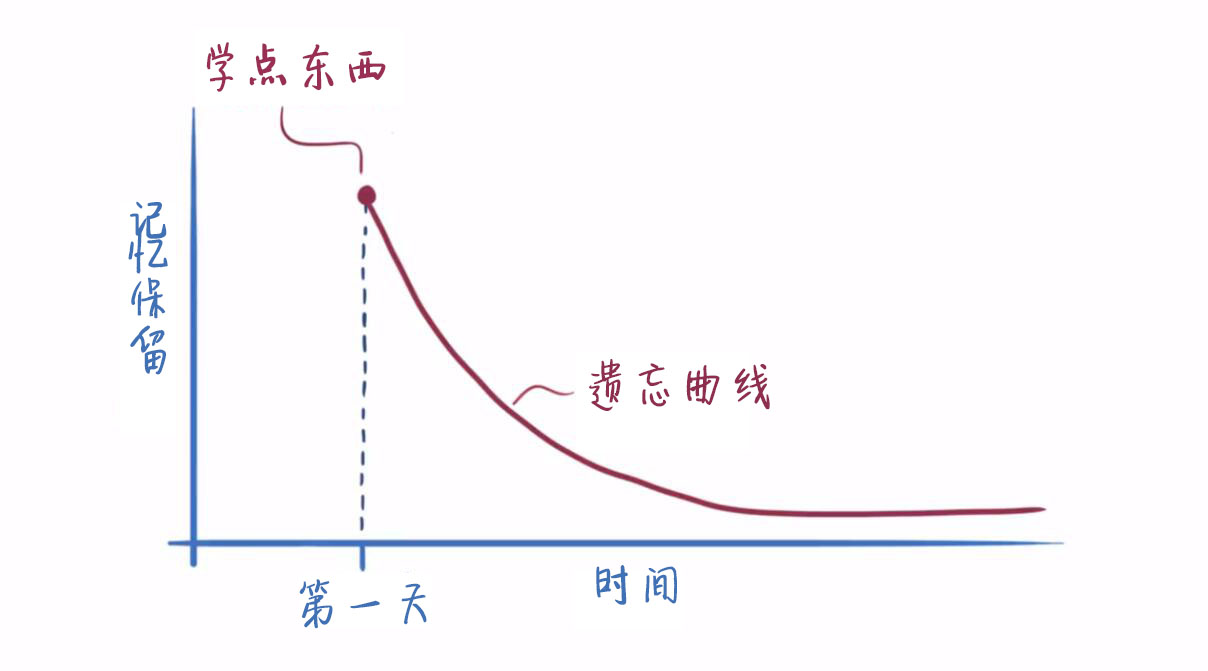
第一天,当我们翻开课本,听老师讲课,学了点东西之后,随着时间推移,我们学到的东西在记忆中的保留量将像遗忘曲线那样持续下降。
遗忘曲线是对知识在我们记忆中的保留情况进行描述,其特点也非常鲜明:在没有进行复习的情况下,记忆保留随着时间下降的程度是先快后慢的。
面对遗忘我们怎能坐以待毙?看看加入复习后的效果!
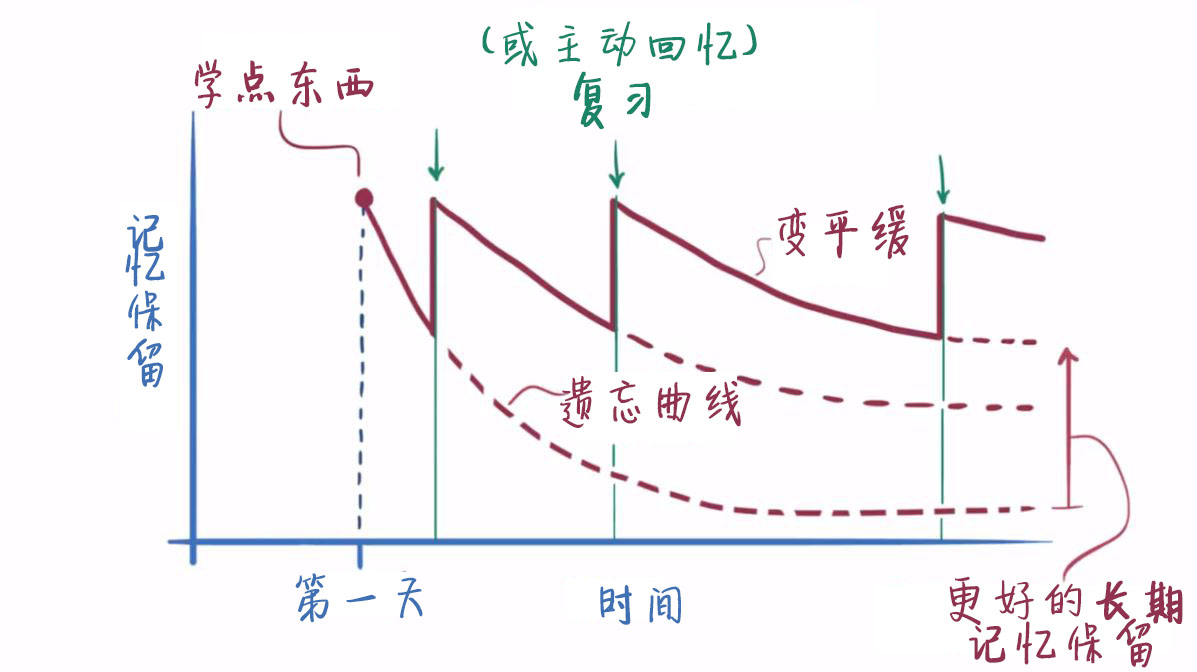
在学习新知识之后的这段时间里,如果我们进行复习,然后用一条新的遗忘曲线来刻画复习后的记忆保留情况,就会看到,复习之后的遗忘曲线变得更加平缓了,这意味着遗忘的速度在变慢。
那么问题来了,我们该怎样安排复习的间隔,才能更高效地记忆?
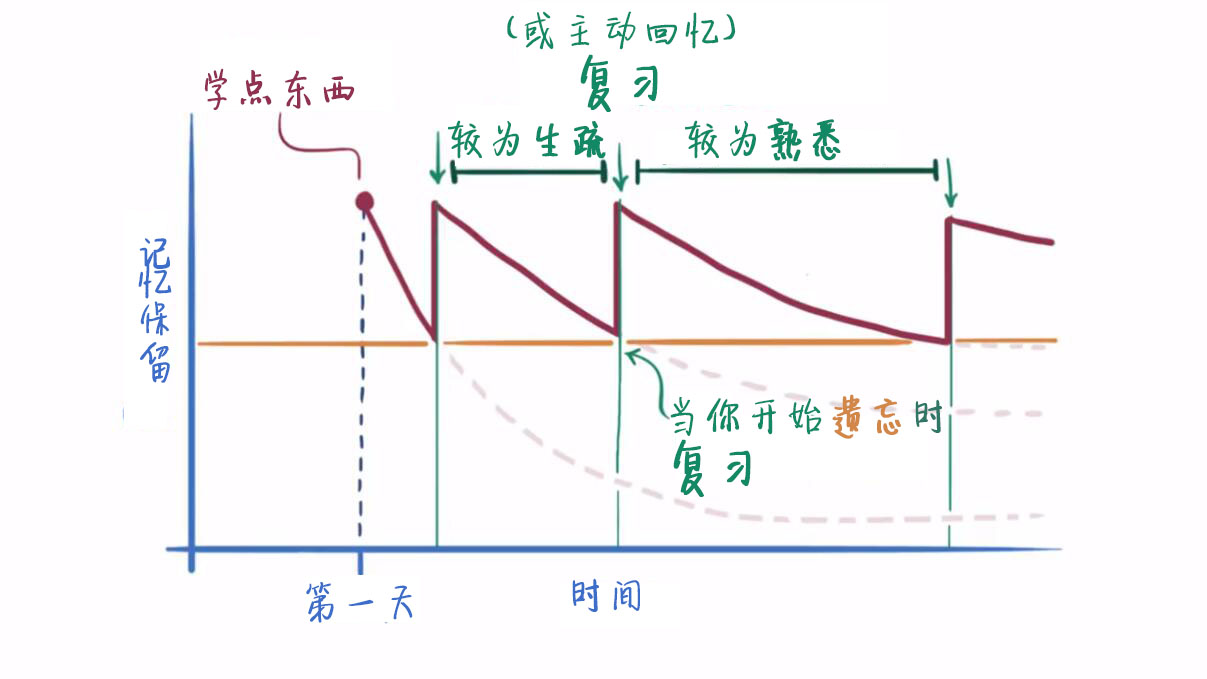
看到一长一短的两个间隔了吗?对于较为生疏的材料,我们加以较短的间隔,而对于较为熟悉的材料,我们加以较长的间隔,将复习分散到未来不同的时间点进行。这种增强长期记忆的方法,被称为间隔重复。
那么间隔重复效果究竟有多好呢?让我们看一组医学生的数据:
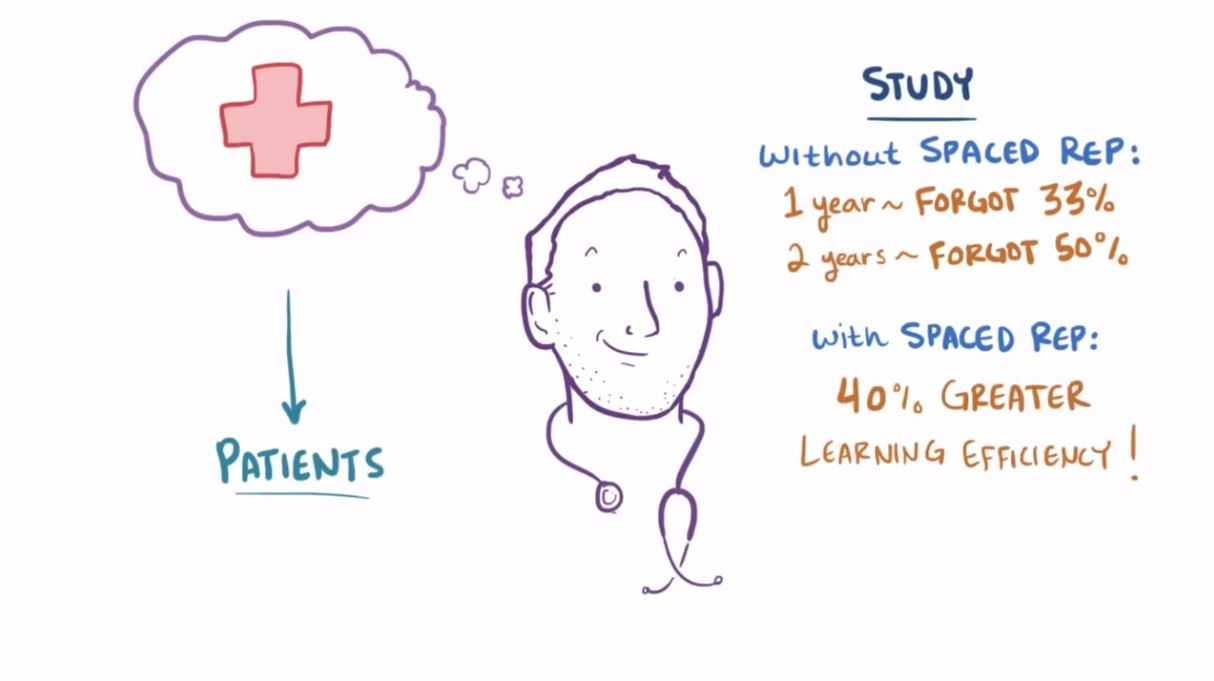
没有间隔重复,学生将在一年后遗忘 33% 的知识,两年后遗忘 50%!使用间隔重复后,将提高 40% 的学习效率!
既然间隔重复的效果这么好,那为什么它没有得到推广呢?
因为要学的知识太多了!而且每个知识都有自己的遗忘曲线,想要去追踪他们的复习时机并安排间隔重复是很难的。
这就引出了记忆算法的用途:自动化地跟踪知识的记忆状态,并安排高效的复习计划。
相信你对间隔重复已经有了初步的理解,不过肯定还会有不少疑问,比如复习时机是如何计算的,怎样间隔重复才是高效的。对于这些问题的解答,都在之后的章节中。让我们进入正题吧!
关于间隔重复更加详尽的介绍,请见 @Thoughts Memo 汉化组翻译的综述《高效学习的间隔重复》。
复习环节
| 问题 | 答案 |
|---|---|
| 遗忘曲线刻画了什么? | 随着时间推移,知识在我们记忆中的保留情况 |
| 在没有进行复习的情况下,记忆保留的下降速度呈什么变化? | 先快后慢 |
| 在复习之后,新的遗忘曲线相比旧的遗忘曲线,有什么区别? | 新的遗忘曲线更平,即遗忘得更慢 |
| 间隔重复的复习安排有什么特点? | 复习被分散到未来不同的时间点 |
| 间隔重复如何区别对待不同记忆程度的内容 | 生疏的材料用较短的间隔,熟悉的材料用较长的间隔 |
| 记忆算法在间隔重复中扮演什么样的角色? | 跟踪记忆状态,自动安排复习计划 |
在了解了间隔重复的概念后,你很可能已经开始琢磨这句话了:
对于较为生疏的材料,我们加以较短的间隔,而对于较为熟悉的材料,我们加以较长的间隔,将复习分散到未来不同的时间点进行。
这个较短的间隔,和较长的间隔,究竟是多久?生疏和熟悉,又该如何判断?
凭借直觉,材料在我们记忆中的遗忘速度越慢,那便是越熟悉。而一个合理的间隔,应当尽可能减少我们的遗忘。但是想要遗忘得越少,从遗忘曲线中我们可以推理出,需要的间隔也越短。而间隔越短,复习的频率就会越高。
看来复习频率和遗忘率之间存在某种不可调和的矛盾,这可如何是好?
坐在电脑前空想,看来是得不出什么结论。我们现在对间隔重复的了解还是太少了。
如果让你来解决这个矛盾,你会需要继续了解什么?你会设计怎样的实验?保持对这些问题的思考,如果能写下来就更好了!
让我们开始看看首个间隔重复算法的设计者是怎样开始他的记忆算法研究之路吧!
SM-0[2]
1985 年,年轻的大学生彼得·沃兹尼亚克[3](下文简称沃兹)正陷入遗忘的泥潭中:

上面这张图片是沃兹的单词笔记本中的一页。79 页,总计 2794 个单词,每页约有 40 个英语-波兰语词对,如何管理它们的复习,让沃兹头疼不已。沃兹一开始没有任何规律的复习计划,复习任何一张笔记全取决于有没有足够的时间。但沃兹做了一件很重要的事情:记录了复习日期和遗忘数量。这使得他可以量化自己的复习情况。
他统计了一整年的复习记录,发现他的遗忘率差不多有 40%~60%。这是他难以接受的,他需要一个合理的复习时间表,能降低他的遗忘率,但不要带来太多的复习负担。为了找到合理的复习间隔,他开始了他自己的记忆实验。
沃兹对合理的复习间隔的期望是:尽可能长,但不要让遗忘率超过 5%
沃兹的实验如下:
实验材料:5 页英语-波兰语笔记,每页 40 个词对。
在第一个学习阶段中,将 5 页材料全部记住。具体的操作为:看英语,回想波兰语,然后检查是否回忆正确。如果回忆正确,将该词对剔除出本阶段。如果回忆失败,就在稍后重新回想,直到所有的回忆都正确为止。
然后是第一个复习阶段,沃兹直接选择了 1 天的间隔,这来自于他此前的复习经验。接下来是该实验最重要的 3 个阶段,记作 A、B、C。
A 阶段,5 页笔记分别间隔 2、4、6、8、10 天后进行第二次复习,统计得到的遗忘率分别为 0%、0%、0%、1%、17%,沃兹选择了 7 天作为第二次复习的最佳间隔。
B 阶段,新的 5 页笔记,第一次复习间隔 1 天,第二次复习间隔 7 天,第三次复习分别间隔 6、8、11、13、16 天,测得遗忘率分别为 3%、0%、0%、0%、1%,沃兹选择了 16 天作为第三次复习的最佳间隔。
C 阶段,新的 5 页笔记,前三次复习分别间隔 1、7、16 天,第四次分别间隔 20、24、28、33、38 天,遗忘率分别为 0%、3%、5%、3%、0%,沃兹选择了 35 天作为第四次复习的最佳间隔。
之后沃兹还做了第五次复习的最佳间隔的实验。但每个阶段要花费的时间差不多是前一个阶段的两倍。最终他确定了纸上算法 SM-0:
- I(1) = 1 天
- I(2) = 7 天
- I(3) = 16 天
- I(4) = 35 天
- for i>4: I(i) = I(i-1) * 2
- 将第 4 次复习后忘记的词对放到新的笔记页面中,与其他新材料一起安排重复
这里的 I(i) 是指第 i 次复习使用的间隔。第五次重复开始的间隔是前一次的两倍,这是基于直觉设置的假设。在使用 SM-0 算法的两年中,沃兹收集了足够的数据来确认这一假设的合理性和准确性。
SM-0 算法的目标很清晰:在可接受的记忆遗忘程度内尽可能选择最长的间隔。它的问题也很明显:以笔记页面作为复习单位,无法跟踪更细粒度的记忆情况。
但 SM-0 的意义非凡,沃兹在 1986 年得到他的第一台电脑后,用计算机模拟了 SM-0 的学习情况,得出以下两个结论:
- 随着时间推移,记忆总量可以不断增加,而不是减少
- 长期来看,学习速率几乎保持不变
SM-0 让沃兹发现,记忆保留和低频重复之间是可以调和的。间隔重复并不会让学习者陷入复习的泥泞之中动弹不得。这让沃兹有了进一步优化记忆算法的信心。
复习环节
| 问题 | 答案 |
|---|---|
| 沃兹对复习间隔的期望,考虑了哪两个因素? | 间隔长度(与复习频率有关)和遗忘率(与记忆保留有关) |
| 为什么在沃兹的实验中,每寻找新一次的复习间隔,就要换一批新的材料? | 确保前几次的复习间隔都一样,控制变量 |
| SM-0的主要问题是什么? | 以笔记页面为复习单位,不能跟踪更细粒度的记忆状态 |
SM-2[4]
SM-0 在初期运作良好,但一些现象促使他继续改进算法:
- 如果一个单词在第一次复习时(1天后)被遗忘,那么在接下来的第二次、第三次复习(7 天,16 天)它要比之前没有忘记的单词更容易遗忘。
- 那些第四次复习后忘记的词对所组成的新笔记页面,在同样的复习安排下,遗忘率更高。
第一个现象让他意识到,复习并不是总能让他更熟悉材料,被遗忘的材料会更加生疏,遗忘的速度没有减缓,如果继续和同一页笔记上的材料继续按更长的间隔复习,效果并不好。
第二个现象让他意识到,材料的难度是有差异的,不同难度的内容应当要有不同的复习间隔。
于是,在 1987 年得到他的第一台电脑后,沃兹根据使用 SM-0 两年来的记录和思考,编写了 SM-2 算法。
SM-2 的算法细节如下
- 将要记忆的知识分成尽可能小的问答对
- 使用以下间隔(天)重复每个问答对
- I(1) = 1
- I(2) = 6
- 当 n > 2 时 I(n) = I(n-1) * EF
- EF(Ease-Factor)―简易度,初值为 2.5
- 每次复习后,nextEF = EF + (0.1-(5-q) * (0.08+(5-q) * 0.02))
- newEF―复习后 EF 的更新值
- q―回忆评分,范围 0 - 5,>= 3 即回忆成功,< 3 为遗忘
- 如果遗忘,将问答对的间隔重置为 I(1),EF 保持不变
SM-2 算法将复习反馈引入到间隔安排中,复习的反馈在一定程度上反映了问答对的难度。简易度 EF 决定了间隔倍数,简易度越低,间隔倍数越小。
此时的 SM-2 算法依然基于沃兹自己的实验数据,但有两个主要改进让 SM-2 成为今天还在流行的记忆算法:
- 对笔记页面进行更细粒度的分离,使复习安排可以精确到每个问答对,更早地分离不同难度的材料的复习周期。
- 引入简易度与评分,使算法有了一定的适应能力,能够根据学习者的反馈调整未来的复习规划。
复习环节
| 问题 | 答案 |
|---|---|
| 为什么复习时被遗忘的内容,不应该安排更长的间隔? | 被遗忘的内容,其遗忘速度没有减缓 |
| 什么现象指出了材料之间存在难度差异? | 由那些被忘记的材料所组成的笔记页面,遗忘率更高 |
| SM-2引入简易度和回忆评分的作用是什么? | 让算法能根据学习者的反馈来调整单张卡片的复习规划 |
| 对笔记页面进行更细粒度的分离,对复习安排有什么好处? | 能更早地分离不同难度的材料的复习周期 |
SM-4[5]
SM-4 的主要目标是改善 SM-2 适应能力低下的问题。虽然 SM-2 能够根据回忆评分和简易度来调整每个问答对(下文简称卡片)的复习规划,但这些调整是互相独立的。SM-2 调整新的卡片的间隔时,不会参考过去调整其他卡片的经验。
也就说,对 SM-2 来说,所有卡片在被添加时,都是一样的。不论学习者学习了多少张卡片,SM-2 对学习者依然一无所知。SM-4 通过引入间隔矩阵来代替计算间隔的函数(I(n) = I(n-1) * EF 以及 EF 更新公式):

上述矩阵被称为最佳间隔矩阵 OI(Optimal Interval),其行索引是简易度,列索引是重复次数。其元素值是使用 SM-2 的间隔函数计算的,所以在调整 OI 矩阵之前,SM-4 与 SM-2 是等价的。
为了让新卡片能受益于旧卡片的调整经验,OI 矩阵会在复习过程中不断调整。其主要操作是:如果矩阵给出的 OI 为 X,实际复习使用的间隔为 X+Y,且回忆评分 >= 4,那么 OI 的值应当进行调整为 X 与 X+Y 之间的一个值。
这种操作的直觉是,既然在 X+Y 的间隔下学习者都能记住卡片,并且评分还挺高,那么显然是之前的 OI 太短了,我有什么理由不把原来的 OI 给调高呢?
带着这样朴素的想法,SM-4 成为了第一个能够在整体范围内适应学习者的算法。然而,SM-4 的调整并没有想象的那么成功。原因也很简单:
- 每次复习只调整矩阵中的一项,无法在可接受的时间内明显地调整 OI 矩阵
- 对于较长的复习间隔,需要调整很久才能稳定
为了解决上述两个问题,SM-5 应用而生。但是由于篇幅所限,本入门读物就不详述了。
| 问题 | 回答 |
|---|---|
| SM-2的适应能力为什么不足? | 对每张卡片的调整是互相独立的,不能共享调整经验 |
| SM-4引入了哪些组分来提高适应能力? | 最优间隔矩阵和间隔调整规则 |
| SM-4调整间隔的思路是什么? | 如果学习者在更长的间隔下表现良好,就提高原有间隔,反之亦然 |
小结
1885 年发明的遗忘曲线刻画了记忆与遗忘,而 1985 年的间隔重复致力于寻找最佳的复习安排。本节介绍了经验算法的三步走:
- SM-0 收集实验数据确定了同一个人同一类材料的最佳复习间隔(这里的最佳是由沃兹定义的)
- SM-2 将算法转换成适应计算机的形式,并引入了更细粒度的卡片和具有适应性的回忆评分与简易度
- SM-4 为了让算法有适应不同学习者的能力,引入了最佳间隔矩阵和相应的间隔调整规则
经验算法让我们对间隔重复有了直观的理解,但光凭经验,没有系统性的理论,想要进一步优化记忆算法是非常困难的。所以接下来,我们将进入理论环节,抽象的概念会变多,请大家坐稳手扶好,司机要提速啦!
Day 2 理论模型
记忆算法听起来似乎是一个理论研究,但我花了大量篇幅介绍经验算法,这是何故?
因为记忆算法,是一种人工科学。记忆虽是人类生理的自然现象,但规律复习以增强记忆,却是人类自己构建的策略。
没有经验算法所支撑起的研究框架,一切理论都无从谈起。理论上的直觉,来自实践中的经验。
接下来的理论模型,也会从我们的经验出发,勿在浮沙筑高台。
记忆的两个组成成分[6]
先来道思考题:如果要你对一个材料在你记忆中的状态进行描述,你会考虑哪些因素?
在 Robert A. Bjork 之前,许多研究者使用记忆强度来表示人们对材料的记忆状态。
你觉得记忆强度这个变量能描述清楚记忆的状态么?
不妨让我们重新看看遗忘曲线:
首先,很明显,记忆保留(回忆概率) 是描述记忆状态的一个重要变量。从我们生活经验出发,遗忘几乎是一件随机事件,谁也没有把握说,今天记住的单词,十天后一定记住,二十天后一定忘记。
有了回忆概率,就足够了么?想象一下,如果我们在上面这些遗忘曲线上划一条水平线,每个曲线都会有一个交点,它们的回忆概率相同。此时,不知道你是否察觉到,回忆概率好像无法区分这些点之间的状态区别?
没错,光靠回忆概率,我们无法区别这些材料的遗忘速度。我们需要在记忆状态中考虑到它,但是遗忘速度是一个随着时间变化的量,能否用一个与时间无关的量来刻画出它呢?
我们需要找到遗忘曲线的数学性质,才能解答这个问题。而这需要我们收集大量的数据来绘制遗忘曲线(以下数据来自墨墨背单词的开源数据集):
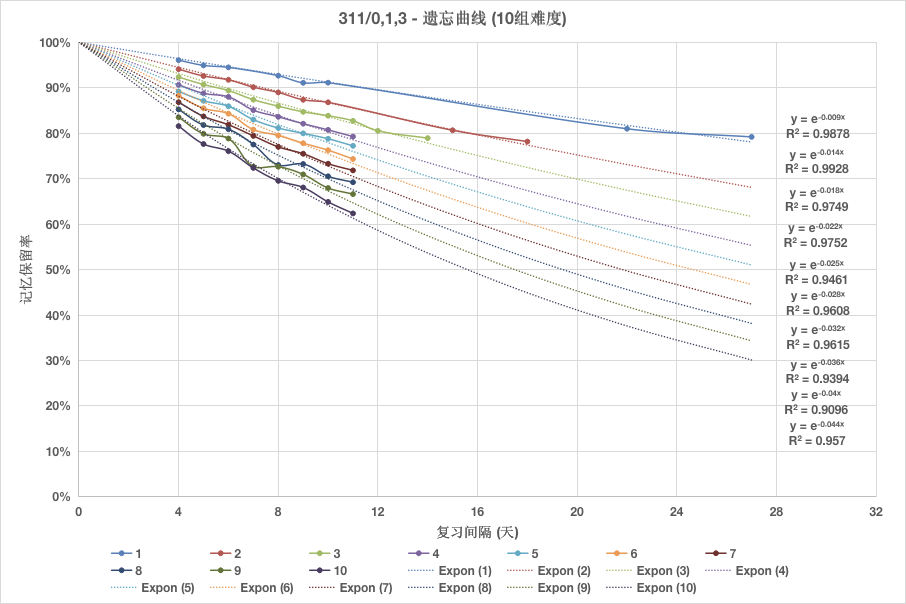
从上图中,我们发现,遗忘曲线近似一条以 e 为底的负指数函数,而遗忘速度就可以用负指数函数的衰减常数来刻画。
考虑到这个衰减常数很难与函数图像联系起来,我们往往会对这个衰减常数进行变换,从而得到遗忘曲线的拟合公式:
其中,R 为回忆概率(Recall),S 为记忆稳定性(Stability),t 为距离上次复习所过去的时间。
S 的大小与遗忘曲线之间的联系,可以从下图中得出:
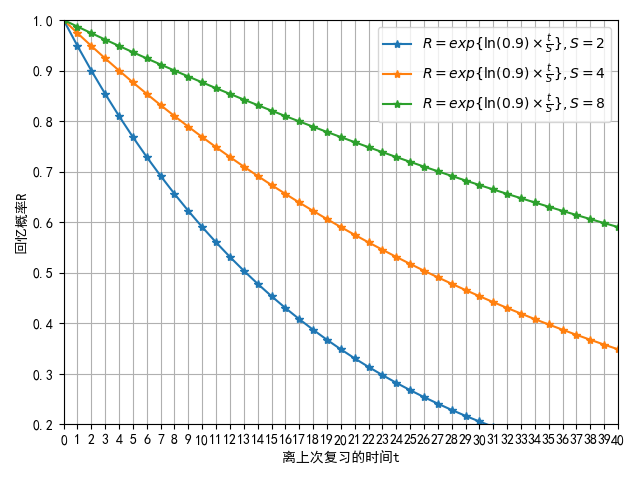
记忆稳定性恰好等于回忆概率从 100% 下降到 90% 所需的时间。(在其他学术文献中,也有使用 50% 作为基准,此时的记忆稳定性被称作记忆半衰期)
对照 Bjork 提出的记忆的两个强度——提取强度和存储强度——正好可以用回忆概率和记忆稳定性来对应。
该公式还有三个特性:
- 当 t=0 时,R=100%,表示刚刚复习时,遗忘还未开始,回忆概率为 100%;
- 当 t→∞ 时,R→0%,表示如果一直不复习,就会忘记几乎所有记忆;
- 同时,负指数函数的一阶导数也是递减的,这与遗忘先快后慢的现象一致。
由此,我们得到了描述记忆的两个组成成分,但好像有什么东西被遗漏了。
回忆概率描述了遗忘的程度;记忆稳定性描述了遗忘的速度;还有什么东西没有被描述到?
复习时,遗忘曲线发生变化的这个瞬间!记忆稳定性发生了变化,而这一变化,并不单单取决于复习时的回忆概率和此时的记忆稳定性。
有什么证据吗?想想一条材料第一次学习的情况:此时的记忆稳定性为 0,回忆概率也是 0,但学习后的回忆概率变成了 100%,而记忆稳定性则视材料的某些属性而定。
也就是说,材料本身还有一些变量,会影响记忆的状态。从直觉上来看,这个变量就是材料的难度。
纳入材料难度这个变量后,我们得到了记忆三变量模型。
| 问题 | 回答 |
|---|---|
| 为什么一个记忆强度变量无法描述清楚记忆状态? | 遗忘曲线不仅刻画了记忆保留,还刻画了遗忘速度,一个变量无法同时描述 |
| 用于刻画记忆保留程度的变量是什么? | 回忆概率 |
| 可以用什么函数来近似遗忘曲线? | 指数函数 |
| 刻画记忆遗忘速度的变量是什么? | |
| 记忆稳定性的现实含义是什么? |
记忆三变量模型
让我们直接进入术语约定:
- 记忆稳定性(memory stability):一条记忆的回忆概率从 100% 下降到 90% 所需的时间
- 记忆可提取性(memory retreivability):一条记忆在某一时刻的回忆概率
- 记忆难度(memory difficulty):一条记忆内在的难度
这里也精确地区分一下记忆可提取性和记忆保留的区别:前者专指某一条记忆的回忆概率,而后者是多条记忆整体的回忆概率均值。
使用上述术语,我们可以定义任意一条记忆在 n 次复习成功后 t 时刻的记忆可提取性:
通过这个式子,把 转换为复习间隔,便可以将记忆算法和记忆模型联系起来:
其中:
为第一次复习的间隔
为第 i 次复习间隔与第 i−1 复习间隔之间的比值
记忆算法的目标就是准确地计算 和
,这样就可以得到不同学生、不同材料、不同复习周期下的记忆稳定性,从而安排合理的复习间隔。
回顾一下,SM-0 和 SM-2 的 都是 1天。 SM-0 的
是一个预设值,不会变化;而 SM-2 的
是简易度 EF,会随着用户的评分输入而发生变化,但每张卡片的
是相互独立的。SM-4 尝试打破这种独立,并在 SM-5 及之后的算法上被持续改进。
问题来了,说了这么多, 跟记忆三变量有啥关系?
大家不妨先自己思考一下,在每一次复习时,记忆的状态会怎样更新。
以下是沃兹的一些实验结论(墨墨背单词的数据也能验证):
- 记忆稳定性的影响:当 S 越高,
- 记忆可提取性的影响:当 R 越低,
- 记忆难度的影响:当 D 越大,
由于存在上述多重因素的影响,难以计算,SuperMemo 使用多维矩阵在表示
的多变量函数,并在用户的学习过程中调整矩阵值,从而逼近真实情况。
为了方便后续讨论,我们使用 SM-17 对 的命名:记忆稳定性增长 SInc(Stability increase)。这个命名的含义是,
是重复前后记忆稳定性的增长倍数。
接下来,就让我们详细介绍一下记忆稳定性增长。
| 问题 | 回答 |
|---|---|
| 记忆三变量模型包含了哪三个变量? | 记忆稳定性、记忆可提取性、记忆难度 |
| 记忆可提取性和记忆保留率的区别是什么? | 前者是记忆个体的性质,后者是记忆总体的性质 |
| 记忆三变量模型和记忆算法之间联系的桥梁是哪两个参数? | 初始间隔 $I_1$ 和连续两个间隔之间的比值 $C_i$ |
| $C_i$ 的命名是? | 记忆稳定性增长 |
记忆稳定性增长[7]
在本章中,我们暂时抛开记忆难度的影响,把注意力集中在记忆稳定性增长与稳定性、可提取性之间的关系上。
下述数据由 SuperMemo 用户提供,沃兹通过控制变量和线性回归来分析这些变量之间的关系。
稳定性增长与记忆稳定性的关系
在研究 SInc 矩阵,我们发现,给定 R,SInc 关于 S 的函数可以很好地用负幂函数描述:
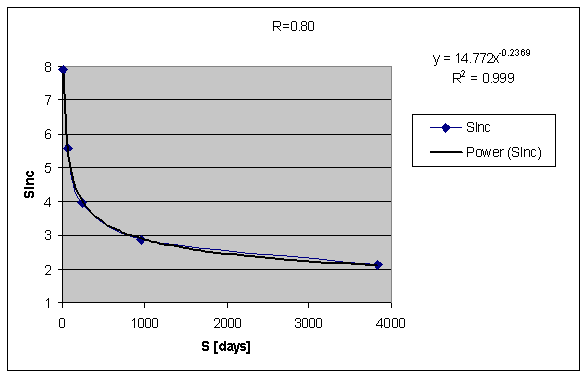
对稳定性增长(Y 轴)和稳定性(X 轴)分别取对数,得到下图:
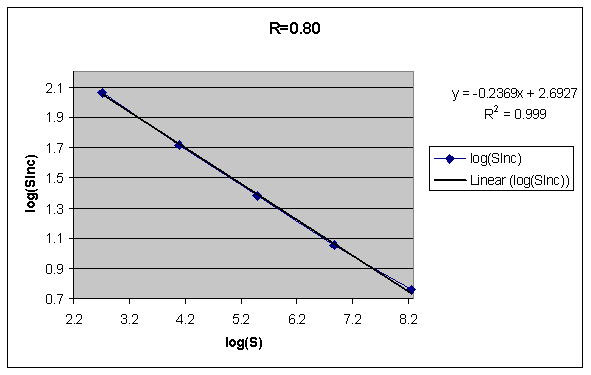
这与此前「当 S 越高, 就越小」的定性结论一致,并在函数性质上有了更细致的刻画。
稳定性增长与记忆可提取性的关系
如间隔效应预测的那样,SInc 在 R 较小时更大。在研究多个数据集后,我们发现,当 R 减小时,SInc 呈指数增长。这种增加的幅度高于预期,进一步为间隔效应提供了证据。
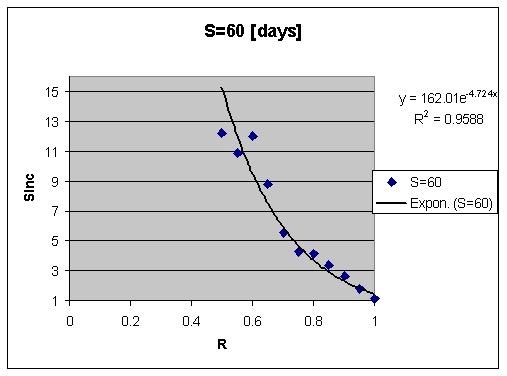
对可提取性(X 轴)取对数,得到下图:
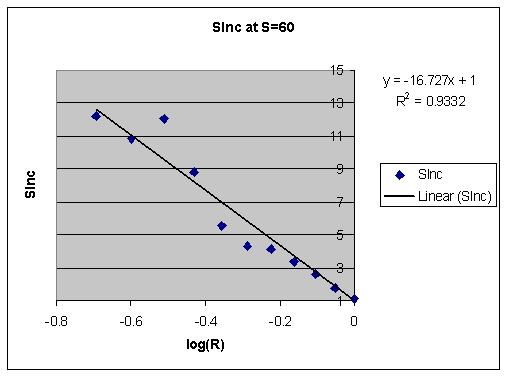
令人感兴趣的是,SInc 在 R 为 100% 时可能低于 1。一些分子层面的研究表明,复习时记忆的不稳定性增加。这又一次证明了,反复死记硬背不仅会浪费更多时间,还会损害记忆。
由稳定性增长函数得出的结论
根据以上基本规律,我们通过组合、变换视角等方式,便可推导出更多有意思的结论。
稳定性增长系数与时间呈线性关系
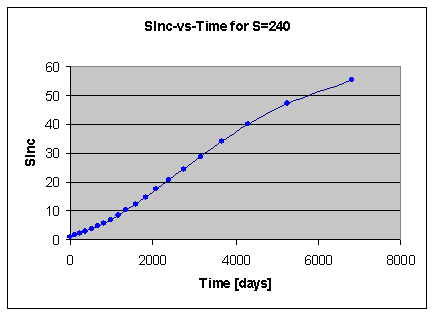
R 随着 t 增加而指数下降,而 SInc 随着 R 下降而指数上升。两个指数相互抵消,从而得到一条近似线性的曲线。
记忆稳定性的期望增长
学习优化有各种标准,我们可以针对特定的保留率进行优化,或者最大化记忆稳定性。在这两种情况下,了解预期的稳定性增长都是有帮助的。
我们将预期的稳定性增长定义为
E(SInc)=SInc×R
这产生了一个惊人的结果:当保留率在 30% ~ 40% 时我们达到了最大的期望稳定性增长:
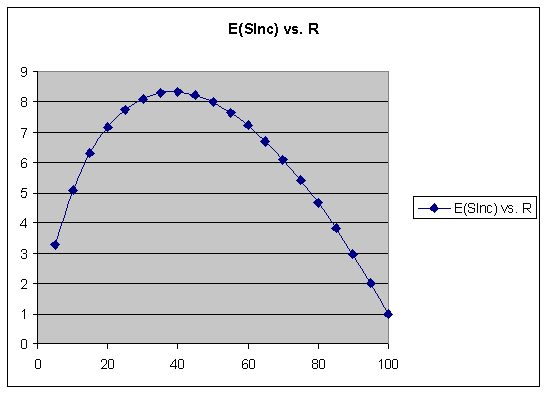
当然,最大的期望稳定性增长并不等同于最快的学习速度。真正最高效的复习策略,还请见后文的 SSP-MMC 算法。
复习环节
| 问题 | 答案 |
|---|---|
| 稳定性增长与记忆稳定性的关系可用什么函数刻画? | 负幂函数 |
| 稳定性增长与记忆可提取性的关系可用什么函数刻画? | 指数函数 |
记忆复杂性
记忆稳定性在间隔重复中取决于复习的质量,也就是记忆复杂度。为了有效复习,知识关联需要简单(即使知识本身是复杂的)。卡片可以构建出知识的复杂结构,但是独立的记忆卡片应该是原子的。
在 2005 年我们找到了可以描述复合*记忆复习的公式。我们注意到:复合记忆的稳定性就像电路里的电阻,并联电阻会使更多的电流通过。(*注:等同于复杂,但复合凸显出其由简单部分组成的本质,所以下文都用复合来代替复杂)
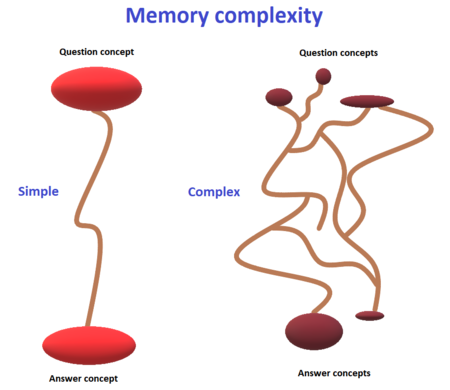
复合的知识会产生两种影响:
- 其他信息片段的干扰增加
- 难以在复习时对记忆的子成分均匀刺激
假设我们现在有一张复合卡片,需要记忆这张卡片上的两个填空。并假设这两个空是同样难记的。那么复合记忆的可提取性是其子记忆可提取性的乘积。
让我们代入遗忘曲线的公式
其中 S 是这个复合记忆的稳定性。那么由
可得
即复合记忆的稳定性将比其两个子记忆的稳定性还要低!根据公式推导,两个子记忆的稳定性会趋同于较难的子记忆的稳定性。
当复杂性达到某种程度,将无法建立长期保留的记忆稳定性。简而言之,要记住整本书,除了不停地重读,别无他法。这是个徒劳的过程。
复习环节
| 问题 | 答案 |
|---|---|
| 复合记忆的可提取性 $R$ 与其子记忆的可提取性 $R_a,R_b$ 之间存在什么关系? | $R = R_a \times R_b$ 复合记忆的可提取性是其子记忆的可提取性之积 |
| 复合记忆的稳定性 $S$ 与其子记忆的稳定性 $S_a,S_b$ 之间的大小关系是? | 复合记忆的稳定性小于其所有子记忆的稳定性 |
| 随着复合记忆的子记忆越多,复合的记忆稳定性会如何变化? | 越来越小,趋近于0 |
Day e 前沿进展
在学习了记忆的一些理论之后,该好好将它们用起来了(1+1=2 已经教会你们了,现在让我们一起算一下这道无穷级数吧 233)。接下来的前沿进展,将会介绍墨墨是如何应用这些记忆理论,研发自己的记忆算法,提高用户的记忆效率。
接下来就没有复习环节了,并且难度急剧上升,可要坐稳喽!
数据收集[8]
数据是记忆算法的源头活水,没有数据,巧妇也难为无米之炊。收集合适、全面、精确的数据,将决定记忆算法的上限。
为了精准的刻画学习者的记忆情况,我们需要定义出记忆的基本行为。先让我们思考一下,一个记忆行为,包含哪些重要属性?
最基本的要素很容易想到:谁(行为主体)何时(时间)做了什么事(记忆)。对于记忆,我们又可以继续挖掘:记了什么(内容)、记得怎么样(反馈)、花了多久(成本)等等。
考虑到这些属性之后,我们便可用一个元组来记录一条记忆行为事件:
该事件记录了一个用户 user 对某条材料 item 在某个时刻 time 作出了某类反馈 response,付出了多少成本 cost。举例说明:
即:小叶在 2022 年 4 月 1 日 12 点 0 分 1 秒记忆了 apple 这个单词,反馈忘记,用时 5 秒。
有了基本的记忆行为事件的定义,我们在此基础上,抽取、计算更多感兴趣的信息。
比如,在间隔重复中,两次重复之间的时间间隔是一个重要的信息,利用上述记忆行为事件,我们可以将事件数据按照 user、item 分组,按 time 进行排序,然后将相邻两次事件的 time 相减,即可得到间隔。通常来说,为了省去这些计算步骤,可以直接将间隔记录在事件中。虽然造成了存储冗余,但能够节省计算资源。
除了时间间隔之外,反馈、间隔的历史序列也是一个重要的特征。比如「忘记、记得、记得、记得」、「1 天、3 天、 6 天、10 天」,这些信息能够较为完整地反映一个记忆行为的独立历史,也可以直接记录到记忆行为事件中:
对数据感兴趣的朋友,可以下载墨墨背单词的开源数据集,自己分析一下试试哦~
DSR 模型
有了数据之后,该如何利用呢?回顾 Day 2 的记忆三变量模型,其实我们想要知道的是记忆状态的种种属性,而我们目前收集的数据暂时不包括这些内容。因此,如何将记忆数据转换成记忆状态和状态之间的转移关系,是本节的目标。
记忆状态
DSR 模型的三个字母分别对应难度(difficulty)、稳定性(stability)和可提取性(retrievability)。让我们先从可提取性入手。可提取性反应了记忆在某时刻的回忆概率,但记忆行为事件已经是进行回忆后的结果。用概率论的语言来说,记忆行为是只有两种可能结果的单次随机试验,其成功概率等于可提取性。
因此,若要测得可提取性,最容易想到的方法就是对同一个记忆进行无数次独立实验,然后统计回忆成功的频率。但这种方法在实际上是不可行的。因为对记忆进行实验,将改变记忆的状态。我们无法作为一个观察者,在不对记忆造成影响的情况下对记忆进行测量。(注:以目前的脑科学水平,还无法在神经层面测量记忆的状态,因此这条路目前也用不了)
那么,我们就束手无策了么?目前有两种妥协的测量方式:(1)忽略记忆材料的差异:SuperMemo 和 Anki 都属于此类;(2)忽略学习者的差异:MaiMemo 属于此类。(注:其实现在已经考虑了,只是在我刚动笔写这段话的时候还没开始考虑,但是没有关系,不会对理解下面的内容产生影响)
忽略记忆材料的差异是说,测量可提取性时,统计除了记忆材料外其他属性都相同的数据。虽然无法对一位学习者、一条材料进行多次独立实验,但一位学习者、多条材料就可以了。而忽略学习者的差异,则是对多位学习者、一条材料进行统计。
考虑到 MaiMemo 的数据量较为充分,本节仅介绍忽略学习者差异的测量方式。忽略后,我们便能聚合得到新的记忆行为事件组:
其中,N 为记忆该材料且历史行为相同的学习者数量,可提取性 是这些学习者中回忆成功的比例。当 N 足够大时,比率
接近真实的可提取性。
解决了可提取性之后,稳定性也就迎刃而解了。测量稳定性的方法是遗忘曲线,根据收集的数据,可以使用指数函数来回归计算 相同的记忆行为事件组的稳定性。
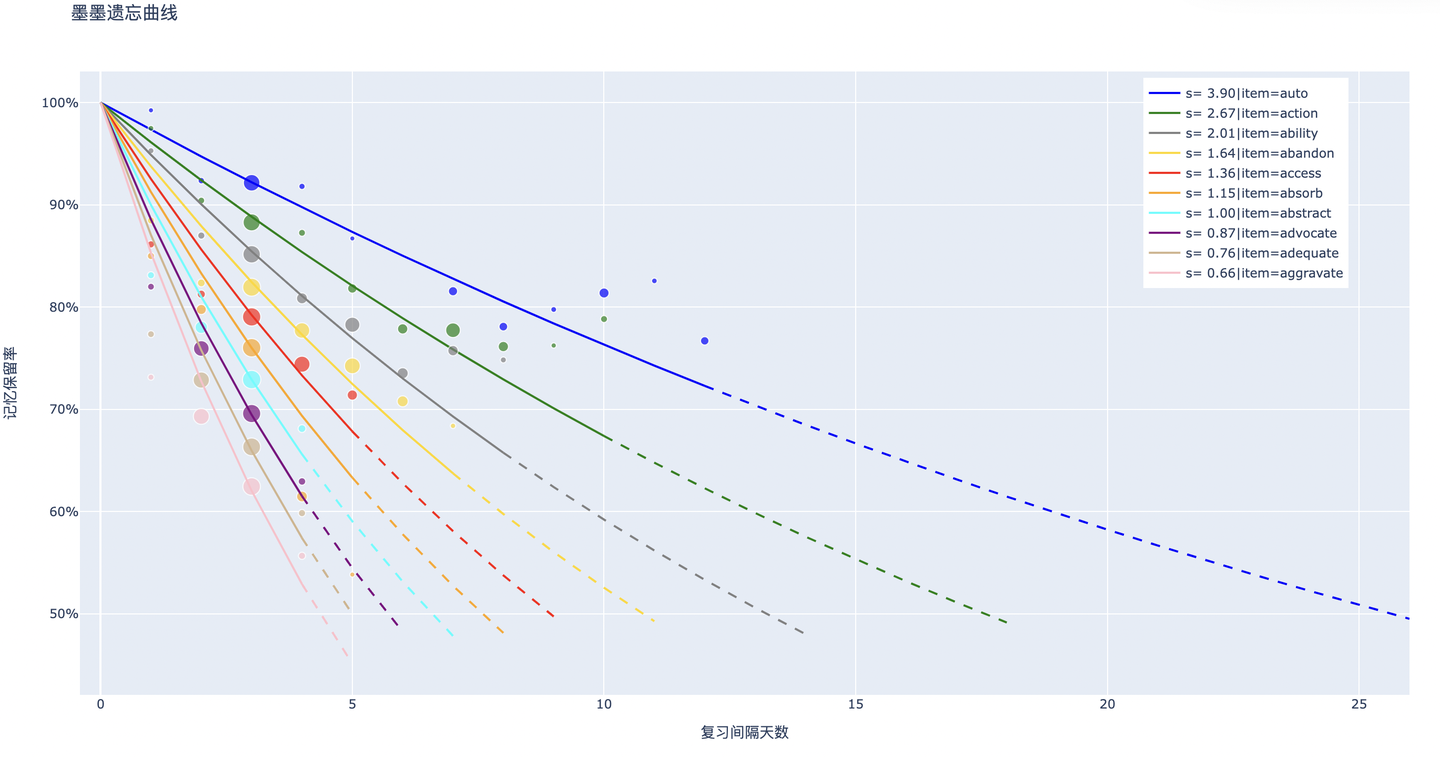
图中的散点坐标为 ,相对大小为
。曲线是拟合后的遗忘曲线。
最后,该对难度下手了。如何从记忆数据中得出难度?让我们先从一个简单的思想实验开始。假设有一群学习者,第一次记忆 apple 和 accelerate 两个单词。如何用记忆行为数据来区分两个单词的难度?
最简单的方法,在第二天立即测试,记录记忆行为数据,统计一下,看见哪一个单词的回忆比例更高。从这一个立足点出发,我们可以将第二天的回忆比例,换成第一次记忆后的稳定性。
也就是说,第一次记忆后的稳定性能够反映出难度。但如何使用第一次记忆后的稳定性来划分难度,并没有统一的标准。怎样的划分方式最好,也没有定论。作为入门材料,本文就不详细讨论了。
状态转移
至此,我们已经可以将记忆数据转化为记忆状态:
接下来,我们便可以着手描述状态之间的转移关系。如 在
天后复习,回忆结果为
,得到新的记忆状态
。那么,
与
和
、
之间的关系是什么?
首先,依然是先将记忆状态数据整理成适合分析的形式:
其中, 在复习后会立刻达到 100%,因此在分析过程中可以将其忽略。还有
、
和
之间知二求一,可以忽略掉
。
最终,我们要分析的状态转移数据如下:
而 ,正好可以参考我们在记忆稳定性增长一章中的提到的几个规律:
可以得到关系公式(难度 D 的影响在此处被省略了):
根据上式,我们预测学习者的每次回忆成功后的记忆状态 。反馈遗忘也是同理,可以用另一组公式状态转移方程进行描述。
SRS 模拟
有了记忆的 DSR 模型,我们便可以模拟任何复习规划下的记忆情况。那么,具体该如何模拟呢?我们需要从现实中普通人是如何使用间隔重复软件的角度出发。
假如小叶需要为四个月后的考研英语做好准备,需要使用间隔重复记忆考研考纲英语单词。而由于其他科目也需要抽时间准备。
从上面这句话中,有两个很明显的约束:学习周期天数和每日学习时间。SRS(Spaced Repetition System)模拟器需要将这两个约束考虑进来,同时这也点明了 SRS 模拟的两个维度:日间(by day)和日内(in day)。此外,考纲单词的数量是有限的,所以 SRS 模拟还有一个有限的卡片集合,学习者每天都从这个集合中挑选材料进行学习和复习。而复习任务的安排则由间隔重复调度算法来安排。整理一下,SRS 模拟需要:
- 材料集合
- 学习者
- 调度器
- 模拟时长(日内+日间)
其中学习者可以用 DSR 模型进行模拟,给出每次复习的反馈和记忆状态。调度器可以是 SM-2、Leitner box、递增间隔表,或者其他任何安排复习间隔的算法。而模拟时长和材料集合则需要根据想要模拟的情况来设定。
然后,我们从 SRS 模拟的两个维度出发,设计一下具体的模拟流程。显然,我们需要按照时间顺序,一天一天地往未来模拟,而每一天的模拟则由一张张卡片的反馈组成。所以,SRS 模拟可以由两个循环组成:外层循环表示当前模拟的日期,内层循环表示当前模拟的卡片。在内层循环中,我们需要规定每次复习所花费的时间,当累计时间超过每日学习时长限制时,自动跳出循环,准备进入下一天。
SRS 模拟的伪代码如下:

相关的 Python 代码我开源在了 GitHub 上,感兴趣的读者可以自行阅读代码:L-M-Sherlock/space_repetition_simulators: 间隔重复模拟器 (github.com)
SSP-MMC 算法
说完了 DSR 模型和 SRS 模拟,我们已经能够预测学习者的记忆状态和在给定复习规划下的记忆情况,但是仍然没有回答我们的最终问题:怎样的复习规划是最高效的?如何找到最优的复习规划呢?SSP-MMC 算法从最优控制的角度解决了这一问题。
SSP-MMC 是 Stochastic Shortest Path 和 Minimize Memorization Cost 的缩写,以体现这一算法的数学工具和优化目标。以下内容改编自我的毕业论文《基于 LSTM 和间隔重复模型的复习调度算法研究》和会议论文 A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling 。
问题场景
间隔重复方法的目标在于帮助学习者高效地形成长期记忆。而记忆稳定性反映了长期记忆的存储强度,复习次数、每次复习所花费的时间则反映了记忆的成本。所以,间隔重复调度优化的目标可以表述为:在给定记忆成本约束内, 尽可能让更多的材料达到目标稳定性,或以最小的记忆成本让一定量的记忆材料达到目标稳定性。其中,后者的问题可以简化为如何以最小的记忆成本让一条记忆材料达到目标稳定性,即最小化记忆成本(Minimize Memorization Cost, MMC)。
DSR 模型满足马尔可夫性,每次记忆的状态只取决于上一次的记忆状态和当前的复习输入和结果。其中回忆结果服从一个与复习间隔有关的随机分布。由于记忆状态转移存在随机性,一条记忆材料达到目标稳定性所需的复习次数是不确定的。因此,间隔重复调度问题可以视作一个 无限阶段的随机动态规划问题。考虑优化目标是让记忆稳定性达到目标水平,所 以本问题存在终止状态,可以转化为一个随机最短路径问题(Stochastic Shortest Path, SSP)。
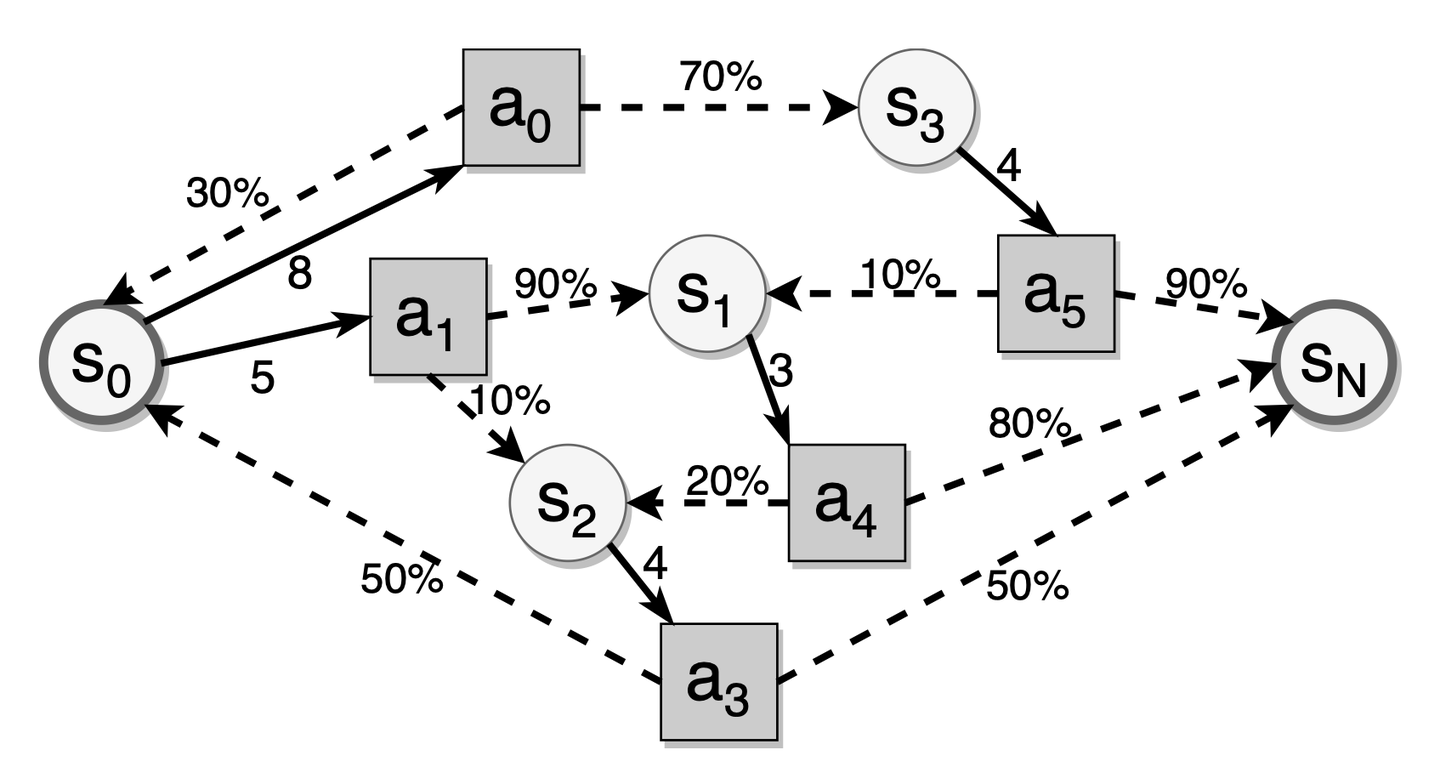
如上图所示,圆圈是记忆状态,方块是复习行为(即当前复习后的间隔),虚线箭头表示给定复习间隔的状态转移,黑边表示给定记忆状态中可用的复习间隔。间隔重复中的随机最短路径问题是找到最佳复习间隔,以最小化到达目标状态的预期复习成本。
方法表述
为了解决这个问题,可以用马尔科夫决策过程(MDP)来建模每张卡片的复习过程,有一组状态 、行为
、状态转换概率
和成本函数
。算法的目标是找到一个策略
,使达到目标状态
的预期复习成本最小。
状态空间 S 取决于记忆模型的状态大小。DSR 只有两个状态变量,所以状态可以表述为 。行为空间
由可以安排复习的 N 个间隔组成。状态转换概率
是卡片在状态 s 和行为 a 下被回忆的概率。成本函数
定义为:
其中 是每次复习的成本,
是服从伯努利分布的回忆结果。目标状态
即目标稳定性所对应的状态。
算法设计
可以用值迭代方法来解决 ,其贝尔曼方程为:
其中 是最优成本函数,
是状态转移函数,即 DSR 模型。对于每次复习的成本,出于简单起见,只考虑回忆结果的影响:
,a 是回忆成功的成本,b 是回忆失败的成本。
基于该贝尔曼方程,下图所示的值迭代算法在迭代过程中使用成本矩阵来记录最优成本,使用策略矩阵来保存每个状态的最佳行为。

不断遍历每个记忆状态下的每个可选的复习间隔,比较选择当前复习间隔后的期望记忆成本和成本矩阵中的记忆成本,如果当前复习间隔的成本更低,就更新对应的成本矩阵和策略矩阵,最终所有记忆状态对应的最优间隔和成本就会收敛。
这样以来,我们便得到了最优复习策略,与预测记忆状态的 DSR 模型相结合,便可为每一位使用 SSP-MMC 记忆算法的学习者安排最高效的复习规划。
该算法已经开源在墨墨科技的 GitHub 仓库:maimemo/SSP-MMC: A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling (github.com),想要深入研究的读者可以 fork 一份到本地把玩。
总结
恭喜你看完了!如果你还没有入土的话,那你就已经入门间隔重复记忆算法了!
可能你还有很多疑问,其中有些可能已有答案,但更多的是无人探索的领域。
我能回答的问题也十分有限,但我会用一辈子去推进间隔重复算法的前沿。
在此我向你发出邀请,一起揭开记忆之谜。不知道你是否愿意与我同行?
彩蛋
本来这篇文章的标题是《间隔重复记忆算法:3 天内,从入门到入土。》,我将「3」改为了「e」,以此致敬指数遗忘曲线的公式: ,同时也是玩个谐音梗,因为能看完这篇文章的朋友,大概都是在「1」天内看完的吧 hhhh。
叶峻峣
2022 年 8 月 20 日
参考
1. 【理论】Study smarter, NOT longer. 你需要间隔重复! ./57020308.html2. 1985:SuperMemo 的诞生 ./95111167.html
3. 彼得·沃兹尼亚克 ./303204832.html
4. 1987 SuperMemo 1.0: 日志 ./97887756.html
5. 1989: SuperMemo 适应用户记忆(上) ./205600711.html
6. 1988:记忆的两个成分 ./99505568.html
7. 2005:稳定性增长函数 ./471760789.html
8. 从 Duolingo 机器学习算法说起,浅析记忆数据的特征工程 ./345172257.html