

看到上期评论区有读者想要了解一下 @多邻国Duolingo 的 HLR 算法[1]的细节,正好我之前因为工作原因有整理过相关文档,本期就从 HLR 算法说起,讲讲机器学习在复习算法中的应用。
注:以下与 HLR 算法相关的内容,均参考自 A Trainable Spaced Repetition Model for Language Learning B. Settles and B. Meeder ACL Proceedings, 2016
算法简介
HLR 是 Half-life Regression 的缩写,直译为中文就是半衰期回归。半衰期在这里的含义是遗忘概率达到 50% 时的复习间隔(类似记忆稳定性[2])。而回归指的是该算法应用了回归模型,用以拟合记忆的半衰期。
这样讲有点抽象,不过 HLR 算法作为机器学习算法的代表,可以直接从机器学习的角度来理解。对于一个机器学习任务,最重要的两个部分就是数据和模型。让我们看看 HLR 到底用了怎样的数据和模型吧!
数据
以下是 HLR 算法的数据样例
样本示例
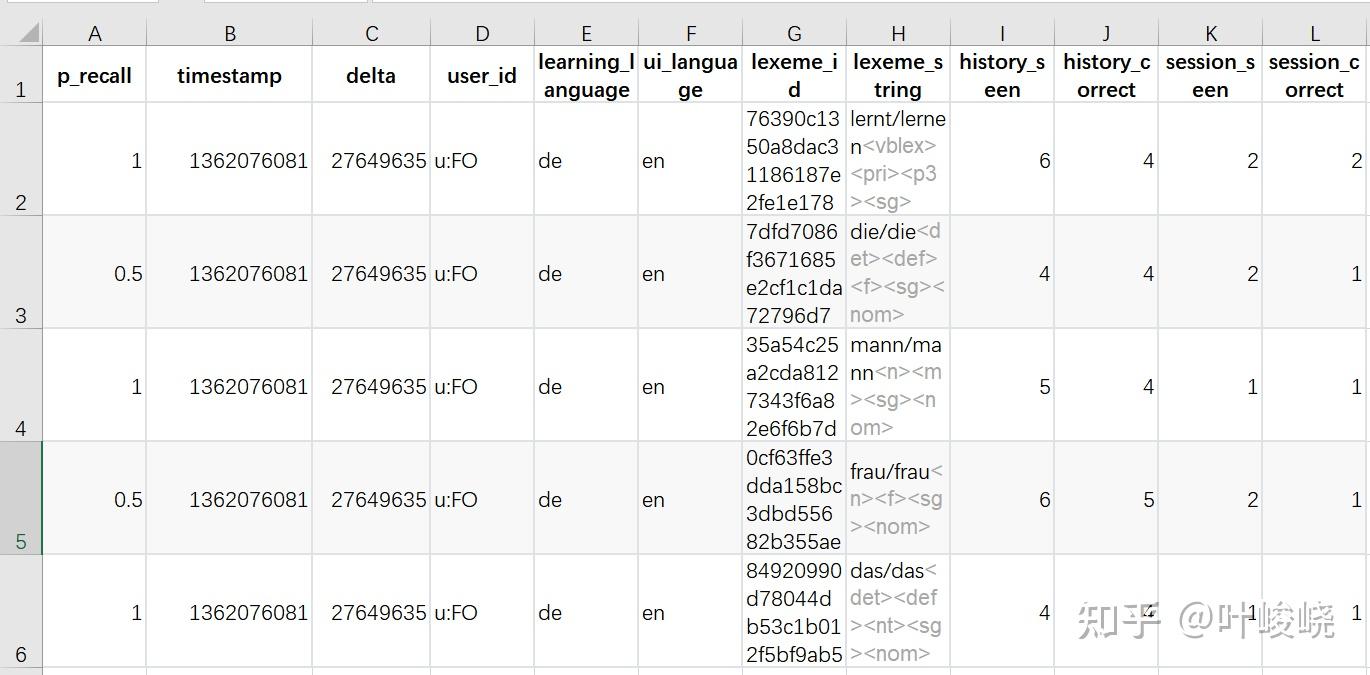
属性注解
- p_recall:回忆概率,用一轮练习中一个单词被正确回忆的次数比去总共回忆的次数来表示;
- timestamp:练习的日期
- delta:距离上次练习该单词的时间
- user_id:学生 id
- learning_language:学习的语言
- ui_language:用户 ui 语言
- lexeme_id:词位 id
- lexeme_string:词位标签
- session_seen:本次练习该单词次数
- session_correct:本次练习正确次数
从这个数据中我们就能看出一些有用的信息。比如,学生 id 表示了学习者,词位 id 表示了记忆材料,这两者在直觉上似乎就与记忆有关。还有练习次数、回忆正确次数等等,相当于记忆行为的历史特征,表示在过去学习者对材料的反馈情况。当然,可千万别忘记了一个重要的特征,那就是距离上次练习该单词的时间。
模型
看完了数据,就该好好思考一下如何用一个模型来利用这些数据了。别忘了复习算法的目标,那就是给出高效的复习安排,而实现这一目标的基础,正是对记忆本身的精确预测。
想要预测,就要建模。而建模,就少不了输入输出,也就是特征向量(feature vector)和标记(label)。
特征向量
HLR 的特征向量是 ,其中:
- right:
- wrong:
:20k 维的稀疏向量,对应哪个词位,其值设为 1,其余为 0
- bias:1
可以很明显地看出,HLR 将记忆反馈历史转化为历史累计答对次数(right)和答错次数(wrong),还用到了记忆材料本身(lex)。
标记
HLR 的标记是回忆概率(p_recall),用来表示学习者实际的反馈,即同一个单词的相关测试正确率。
预测函数
HLR 的核心就是预测函数,这是特征与标记之间的桥梁。不同于常见的线性模型,HLR 在特征与标记之间加入了名为半衰期的中间变量。最终的预测函数为:
:半衰期
:回忆概率
其中
:复习间隔
:学习权重,与特征向量一一对应
在 HLR 的预测过程中,先用特征和权重计算半衰期,再用复习间隔和半衰期计算回忆概率,从而预测记忆的情况。
训练
这个部分需要机器学习基础,所以就不详细介绍了,简单讲讲两个重要的部分。
损失函数
可以看出该算法同时优化 p 和 h 的误差,并加入的正则化项,偏好权重更小的模型。
数值优化
HLR 所用的数值优化算法是 AdaGrad,比较重要的两个公式是:
梯度:
学习率:
算法思路总结
- HLR 算法假设回忆概率是关于实际间隔的指数函数。
- 由于 p 是 h 和
- 由于 h 是模型的一个中间变量,在实际生活中无法直接观测,所以使用
来近似实际值。所以实际上只有 p 是标签(Label)。
- 模型的损失函数使用的是平方损失函数,并且同时对 p 和 h 同时惩罚。
- 最后使用 AdaGrad(自适应梯度算法)来优化权重。
特征工程
没有线代、高数基础的读者看到这些数学公式可能会很晕,不过可以放心的是,数学优化不是本期的重点。机器学习最重要的,其实是数据。数据决定了模型的上限。该谈谈标题里提到的特征工程了,其实这也是机器学习的艺术所在。
HLR 特征分析
HLR 选用的两个核心特征——right 和 wrong,是非常符合直觉的——right 越大,回忆正确次数越多,自然会记得越牢,半衰期长;wrong 越大,遗忘次数越多,记得不好,半衰期短。
事实上,如果学习者完全按照算法的间隔来复习,并且算法的间隔不会临时调整,这两个特征就非常好了。但是现实并没有那么理想。让我们看看以下四个案例,就会发现这样提取特征的问题:
- 案例一:复习间隔为 1 3 5,反馈为 正确 正确 错误
- 案例二:复习间隔为 1 3 5,反馈为 错误 正确 正确
- 案例三:复习间隔为 2 6 10,反馈为 正确 正确 错误
- 案例四:复习间隔为 2 6 10,反馈为 错误 正确 正确
通过计算,我们会发现,它们的 right 和 wrong 都一样。但是显然,它们的复习过程区别很大(后两个案例的间隔前两个案例的两倍,另外还有反馈顺序的问题)。这种区别在特征提取的过程中被忽略了。
当然,特征工程本来就是要忽略区别,找到一个合适的粒度,便于模型找到规律。是否忽略某些区别,就要看这种区别对预测的影响是否显著。
之前我在参数模拟[3]那篇文章提到过,两倍的间隔在理论上会将回忆概率从 90% 降低到 80%。对于一个百分数来说,10% 的差距可以说是非常大了。所以,我认为这种区别是不应该被忽略的。
状态空间方法特征分析
既然分析机器学习方法的特征,不妨也把状态空间方法拿出来对比对比。
以 Anki 为例,用到的特征只有 grade 和 t,也就是反馈和复习间隔。看起来这两个特征比 HLR 用的豪华特征集寒碜多了。但是我们别忘了状态空间本身的特点:状态。
没错,其实状态在一定程度上,保留了记忆的反馈历史。每一次状态转移都是基于反馈和复习间隔的。所以,在这里,状态空间方法用到了被机器学习方法省略的历史间隔特征和反馈顺序。
那可能就会有读者问了,这只是特征工程的锅,盖不到机器学习方法上。确实,这只是特征选取的问题。但是想要在机器学习方法上用到历史间隔和反馈顺序,还是有一定难度的,有两种方法比较常见。
如何在机器学习中利用记忆历史反馈信息(时间序列)?
第一种方法,比较暴力。直接将历史间隔和反馈顺序以矩阵的方式输入。比如我们以天为单位,并用 1 表示正确,0 表示错误。那么案例四的特征可以用两个向量表示: ,
。
这两个向量包含了历史间隔和反馈顺序的完整信息,看起来非常不错。然而,如果真要这样做特征工程,会遇到一个很大的问题:数据稀疏。
什么意思呢?让我们看看,这是复习了 3 次之后的记录,就有 6 个值了。其中反馈还好,只有 2 * 2 * 2 = 8 种可能的结果,但是间隔可能会有 10 * 10 * 10 = 1000 种可能的结果(这还是把间隔上限设置为 10 天的情况)。如果复习 10 次,这个可能结果的数量就要组合爆炸了。再多的样本也难以填满这个样本空间。而数据稀疏带来的后果就是误差偏大、难以训练等等。
第二种方法,那就是给模型增加记忆能力,比如循环神经网络、自回归模型等。这种方法其实是在向状态空间方法学习,将过去的输出作为当前的输入,能够更好地处理时序数据。
不过这种方法也存在一些问题,倒不是理论上的问题,而是实践上的问题。因为目前为止还没有相关研究用这种方法来处理记忆数据。并且应用这种方法该如何做数据处理也是一个新的挑战。
总结
一不小心写得太长了,先感谢一下能看到这的读者朋友们 2333
本文介绍了 Duolingo 所使用的 HLR 算法,概述了机器学习方法是如何应用于记忆预测的。同时深入探究了记忆反馈数据的特征工程和利用方法,简单提及了几个可能的解决方法及其难点。联系前几期文章,我认为记忆模型的进一步发展还需要依靠回归模型和状态空间相结合的方法。
记忆研究还有很多问题等待我们解决,希望我们能够解开记忆的迷雾,让记忆的规律更加清晰地浮现出来。
这里是热爱记忆算法研究的学委叶哥,欢迎大家在评论区交流!
2021 年 1 月 18 日
叶峻峣
参考
1. duolingo / halflife-regression https://github.com/duolingo/halflife-regression2. 从一个记忆伪概念,到记忆研究的难题。 ./343115387.html
3. 【硬核】参数模拟——每天 40 张新卡片,365 天后我要复习多少? ./78398403.html