
译者:FSRS 是基于墨墨背单词的论文《优化间隔重复调度的随机最短路径算法 | 墨墨百科》衍生出的开源项目。
*这是在我和 u/LMSherlock 能想出并实现的算法中最精确的。而且我们与 SuperMemo 的比较测试也只是基于有限的数据。嘿,我得取个酷酷的标题,对吧?
这篇帖子可以看作是之前这个(过时的)帖子[1]的后续。
任何一个「诚实」的间隔重复算法,都应该能够根据卡片的复习历史,预测在特定时间点回忆一张卡片的概率。我们把这个概率称为 R。
如果一个「不诚实」的算法不计算概率,只是输出一个时间间隔,我们仍然可以在某些假设下把这个间隔转换成概率。虽然这总比没有好,因为至少能进行一些比较。这就是我们对 SM-2 算法所做的,也是我们评测中唯一一个「不诚实」的算法。还有其他「不诚实」的算法,比如 Memrise 所用的那种。我原本想把它也包括进来,但我和 Sherlock 想不出一个合理的方法将其间隔转换成 R,所以最终决定不纳入评测。不过,说实话,就算加进来,它的表现也不会好到哪去。它太过死板,简直不够格称作算法。
一旦我们有了能预测 R 的算法,无论是本就为此而设计的,还是通过数学上的巧妙手段将间隔转化成概率的,我们就可以在一些用户的复习历史上运行它,看看预测的 R 和实际测量的 R 之间会有多大的偏差。通过对数百万次复习的分析,我们能够对各种算法的平均表现有一个相当不错的了解。均方根误差(RMSE)可以被解释为「预测的 R 和实际测量的 R 之间的平均差距」。虽然它和我们通常所说的算术平均值有所不同,但差别不大。平均绝对误差(MAE)存在一些不太理想的特性,因此我们选择了 RMSE。RMSE >= MAE,也就是说,均方根误差总是大于或等于平均绝对误差。
在我之前提到的帖子中,我用了 MAE,但 Sherlock 发现在间隔重复学习的情况下它存在一些问题,因此我们现在只使用 RMSE。
现在,让我们来看看我们的参赛者:
1) FSRS v3 是首个真正被人们使用的 FSRS 版本,它在 2022 年 10 月发布。别问为什么第一个版本叫 v3。(译注:好问题,我也忘记了,可能只是 v1 和 v2 知道的人太少了。)
它并不算太差,但也有不少问题。Sherlock、我以及其他几位用户提出并测试了许多想法(其中只有少数是有效的),接下来……
2) FSRS v4 于 2023 年 7 月问世,到了同年 11 月初,Anki 就已经开始原生支持这个版本。它比 v3 更加精确,这一点你马上就能看出来。
3) FSRS v4(默认参数)。这其实就是带默认参数的 FSRS v4。换言之,这些参数并没有针对每位用户进行个性化设置。对比该版本主要是为了证明,即使使用默认参数,FSRS 也优于 SM-2。
4) LSTM,长短期记忆网络,是一种常用于时间序列分析的神经网络,如股市预测或人类语音识别。有意思的是,一个被称为「长短期记忆」的网络,正被用来预测,嗯,记忆。它并非作为调度器提供,仅为这次基准测试而设计。此外,如果有精通神经网络的专家介入,可能还能提高其准确度。
5) HLR[2],半衰期回归,是由 Duolingo 为其自家产品开发的算法。它的作用是,呃...进行半衰期回归。老实说,除了它有类似 FSRS 中的记忆稳定性(称作记忆半衰期)这一点外,我对它的运作方式并不太了解。
6) SM-2,这是一个有 30 多年历史的算法,Anki、Mnemosyne 以及其他一些应用至今仍在使用。它最大的优点在于简单。这里实现的是原版的 SM-2,不是 Anki 版本,而是最初的设计。
7) SM-17,是 SuperMemo 最新推出的算法之一。它使用了 DSR 模型,这一点和 FSRS 相似。FSRS 中的许多公式和特性都是尝试对 SuperMemo 进行逆向工程的结果,有些很成功,有些没卵用。
好了,接下来是大家期待的时刻:
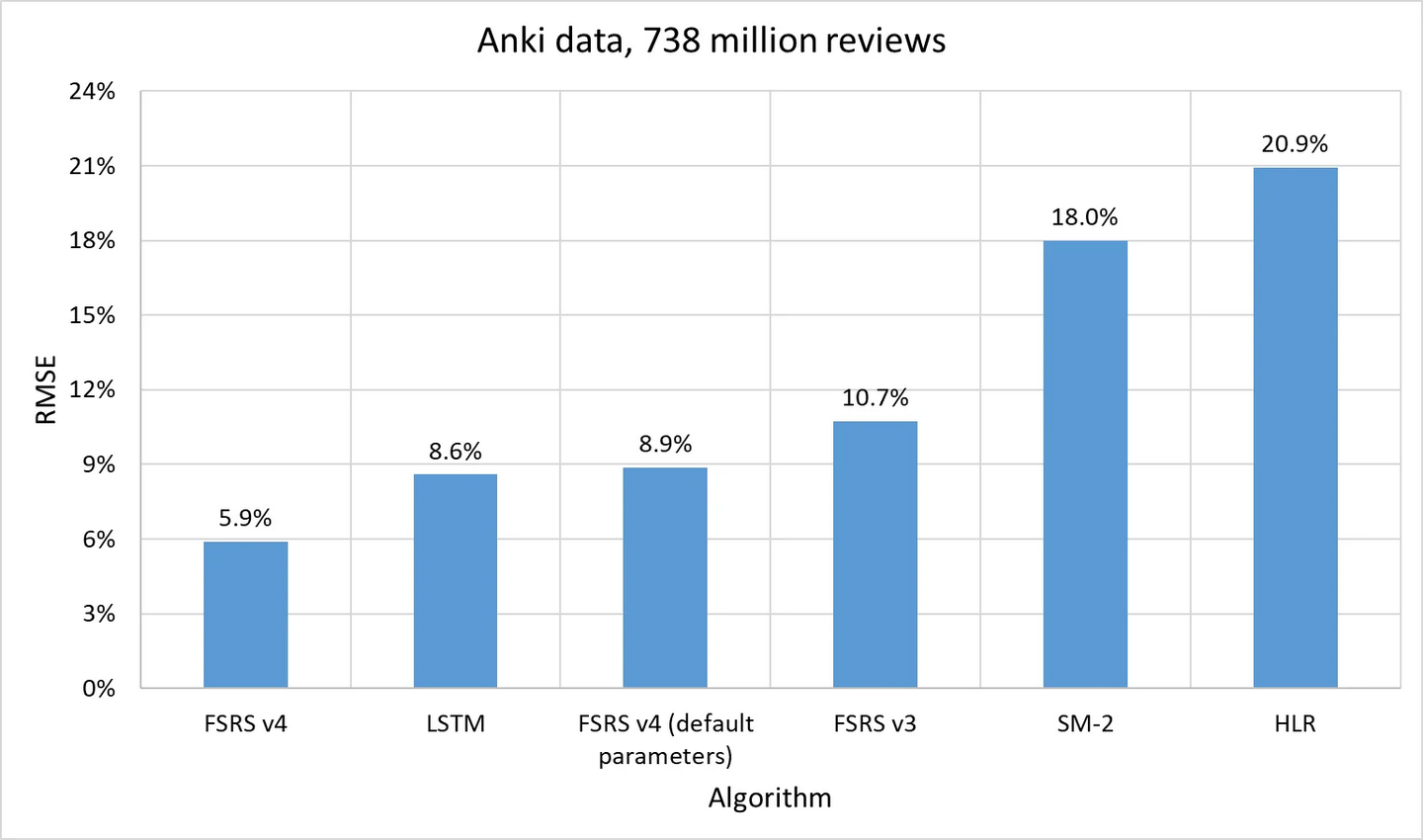
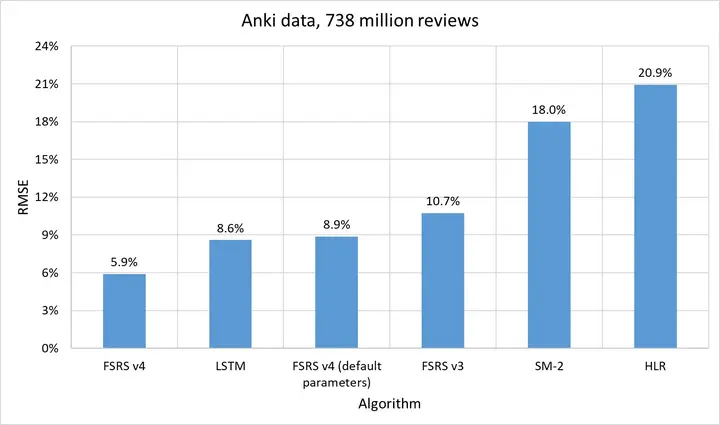
从上图中可以看出,FSRS v4 的表现超过了所有其他算法。有意思的是,HLR 虽然专为预测 R 而设计,却表现得不如未以此为目的的 SM-2。或许 Duolingo 该考虑聘请 LMSherlock 了,哈哈。
你可能在 AnKing 的视频中看过类似的图表,但那是基于 70 个集合和 500 万次复习的数据。而这基于 2 万个集合和 7.38 亿次复习(不包括当天复习)的数据。Dae,主要开发者,向 Sherlock 提供了这份庞大的数据集。如果你想用这份数据集来进行自己的研究,请联系 Dae(Damien Elmes)。
注:数据集仅包含卡片 ID、评分和间隔长度。不包含任何媒体文件和卡片字段的内容,所以不必担心隐私问题。
你可能注意到了,上图中没有包括 SM-17。这是因为 SM 算法是保密的(好吧,早期的除外),所以我们没法在 Anki 的数据上运行它们。不过,Sherlock 已经邀请了许多 SuperMemo 的用户,提交他们的数据来进行研究。他没有在 Anki 用户的数据上运行 SuperMemo 算法,反而是在 SuperMemo 用户的数据上运行了 FSRS。幸运的是,SuperMemo 生成的复习历史里包含了预测的可提取性,不然就无法进行基准测试了。这里是测试结果:
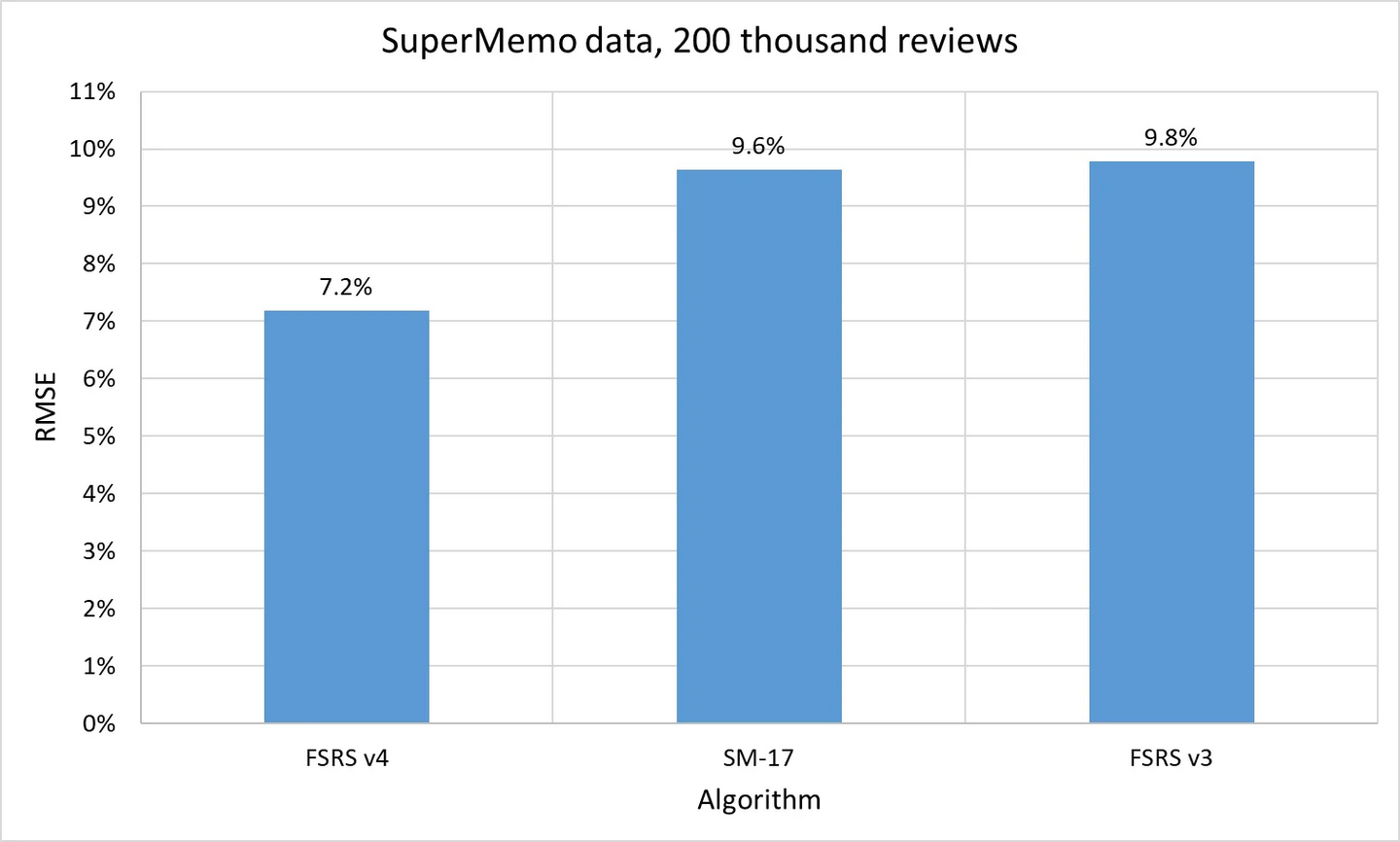
正如你所见,FSRS v4 的表现比 SM-17 稍好。不仅如此,SuperMemo 有 6 级评分,但 FSRS 在设计上最多支持 4 个。因此,必须对评分等级进行转换,这不可避免地造成了信息的损失。你不能把 6 级评分无损地转换成 4 级评分。尽管如此,FSRS v4 的表现依然出色。而且还不止这些!SuperMemo 的优化流程和 FSRS 的大不相同。为了使比较更公平,Sherlock 在这次基准测试中改变了 FSRS 的优化方式。这进一步降低了 FSRS 的准确性。这就像是让一个搏击手减肥,然后按照他不熟悉的拳击规则与拳击手比赛。而这位搏击手还是赢了。这就是 FSRS v4 对 SuperMemo 17 的情况。
注:SM-17 并不是最新的算法,最新的是 SM-18。Sherlock 没能找到获取 SM-18 数据的方法。但这两个版本相差不大,所以 SM-18 不太可能有显著的改善。如果有变化的话,由于难度公式被简化,SM-18 可能还不如 SM-17。
当然,有两个重要的警示:
- 首先,可能还有比 FSRS 更优秀的间隔重复算法存在,但我和 Sherlock 都没听说过。全球所有间隔重复应用所用的所有算法,我并没有一份全面的清单,这样的清单恐怕也不存在。还有很多专利算法,像 Quizlet 的算法,我们无法对它们进行基准测试。(译者:比如还有墨墨背单词的商业算法,MM 系列)
- 其次,基于 Anki 用户数据的基准测试(第一张图)涵盖了大量复习数据,而与 SM-17 的比较(第二张图)则基于相对较少的复习数据。
如果你想了解更多关于 FSRS 的信息,这里是个不错的入门点。你也可以看看 AnKing 的视频。
如果你想更全面了解间隔重复算法,可以阅读 LMSherlock 撰写的这篇文章[3]。
如果你的 Anki 版本早于 23.10(版本号以 2.1 开头),请下载最新版本的 Anki 来使用 FSRS。这里有设置的步骤[4]。虽然在 23.10 之前的旧版 Anki 中也可以使用外置版 FSRS,但操作较为复杂,不太方便。目前 FSRS 在桌面版、AnkiWeb 和 AnkiMobile 上都支持使用。在 AnkiDroid 上,只有 alpha 版本支持 FSRS。
这是基准测试的 GitHub 仓库链接:https://github.com/open-spaced-repetition/fsrs-benchmark
Thoughts Memo 汉化组译制
感谢主要译者 GPT-4,校对 Jarrett Ye
原文:FSRS is now the most accurate spaced repetition algorithm in the world* : Anki (reddit.com)
作者:ClarityInMadness
参考
1. 解释 FSRS(下篇):准确度 ./649701172.html2. 从 Duolingo 机器学习算法说起,浅析记忆数据的特征工程 ./345172257.html
3. 间隔重复记忆算法:e 天内,从入门到入土。 ./556020884.html
4. Anki 新算法 FSRS 配置指南 ./664758200.html
专栏:AnkiX高考
围绕「Anki」和高考备考,面向广大高中生,交流作者们对「Anki」和高考的认识与见解,分享同学们整理的高中知识牌组,带每个考生高效学习!