

遗忘曲线:幂还是指数?
遗忘曲线的形状对于理解记忆至关重要。曲线背后的数学甚至可能影响到对睡眠作用的理解(见下文)。当艾宾浩斯第一次确定遗忘率的时候,他得到了一组相当不错的数据,能较好拟合幂函数。然而,现在我们知道遗忘是呈指数形式的。想了解这种差异可以阅读这篇文章[1]。
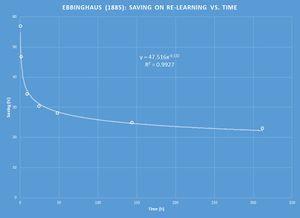
遗忘曲线的术语取自艾宾浩斯(1885)。该曲线是根据艾宾浩斯发表的原始表格数据绘制的(Piotr Wozniak,2017)
错误的想法反而有助于间隔重复研究
多年来,曲线的实际形状在间隔重复中并没有发挥多大作用。我早期对遗忘性质的直觉猜想非常混乱,在不同场景下都不一样。早在 1982 年,我就有这样的思考:进化为大脑设计了遗忘功能,是为了确保记忆空间不会耗尽。遗忘的最佳时机将由环境的统计特性决定。进化编码了衰变的功能,是为了最大限度地提高生存率。一旦没有及时复习,记忆就会被删除,以便为之后的学习提供空间。
我曾误以为存在最优的遗忘时间,然而这个错误其实有助于发明间隔重复。这种「最优时间」的直觉促成了 1985 年的第一次实验。遗忘的最优时间将意味着遗忘曲线是 S 形的,有一个明确拐点,这个拐点决定了最优性。在复习之前,遗忘将是最小的;延迟复习,遗忘则会非常迅速。这就是为什么找到最优间隔显得如此关键。随后大量数据扑面而来,但我因确认偏见所致,仍然看不出我的错误。我的硕士论文中,关于 S 形遗忘,我写道:「这直接源于这样的观察:在最优间隔过去之前,记忆错误的数量是可以忽略不计的」。我一定是忘记了我自己在 1984 年底制作的遗忘曲线图。
今天,这个S 形命题可能看起来很荒谬,但我的间歇学习模型[2]甚至也为这个概念提供了一些支持。对我在间歇学习模型工作中收集的数据进行指数拟合,产生的偏差特别高,而不同 E-系数的 S 形曲线叠加起来,与早期的线性趋势十分接近。在现有的数据中,间歇学习模型在回想范围内似乎可以进行完美地线性拟合。难怪,在整页整页的异质材料中,遗忘的指数性质仍然隐藏得很好。
矛盾的模型
对于遗忘曲线,我没有深入思考过。然而,我对记忆有一个生物模型,可以追溯到 1988 年,这个模型涉及了可提取性的指数衰减。显然,在那时候,遗忘曲线和可提取性这两个概念,在我的头脑中是互相独立的。
在我为计算机模拟课撰写的学分论文中(Dr Katulski,1988 年 1 月),我的图线清楚地显示了遗忘曲线是指数型的:
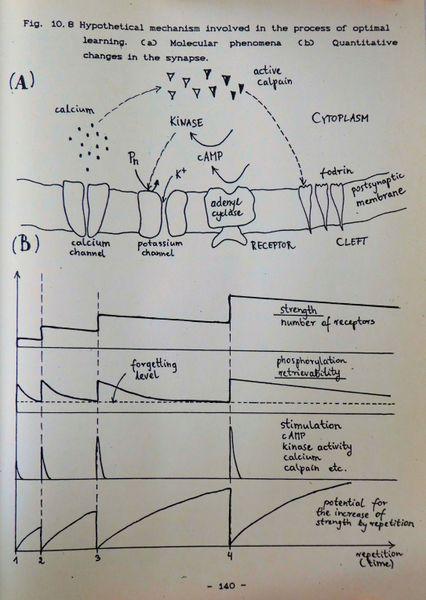
图:在我题为《学习的优化》(1990) 的硕士论文中,我提出了一些假想的概念,这些概念可能是基于间隔重复的优化学习过程的基础。(A) 分子现象 (B) 突触的定量变化。这些想法在今天已经有点过时了,但代表记忆可提取性的锯齿状曲线在关于间隔重复的流行出版物中广为人知。它们通常被错误地认为是赫尔曼-艾宾浩斯的作品
到那个时候,我可能已经从文献中形成了更好的想法。1986-1987 年,我花了很多时间在大学图书馆寻找关于间隔重复的优质研究。什么都没有找到。我可能已经熟悉了由艾宾浩斯确定的遗忘曲线。我在硕士论文中提到了它。
收集数据
当时,我在为我绘制于 1984 年底的第一个遗忘曲线图收集数据。由于所有的学习都是在 11 个月的时间里为学习而学习,而且绘制图表的成本很低,所以我忘记了那张图表,它在我的档案中闲置了 34 年:

图:我最早的遗忘曲线,绘制于 1984 年,即设计纸上 SuperMemo[3] 的几个月前,是关于英语词汇保留率的。这张图并不是实验的一部分,它只是对间歇性学习英语词汇的结果的累积性评估。这张图很快就被遗忘了。34 年后,我重新发现了这张图。英语单词共有 49 页,每页 40 对。我记忆这些单词之后,在不同的时间间隔内进行复习,并记录了回忆错误的数量。排除了异常值,取平均值,该曲线似乎远没有艾宾浩斯(1885)得到的曲线那么陡峭,他画曲线时记忆的是无意义音节,遗忘测量方法也不同:重新学习时节省的时间
我 1985 年的实验也可以被看作是收集遗忘曲线数据的一个未去干扰的尝试。然而,最初 SuperMemos 并不关心遗忘曲线。优化的本质是开关型控制,尽管今天,收集保留率数据似乎是如此明显的解决方案(就像在 1985 年)。
直到我开始用 SuperMemo 软件收集数据,每个记忆条目都能单独研究,我才从我早期关于遗忘的错误想法中完全恢复过来。
DOS 版 SuperMemo 1[4](1987)能收集完整的重复历史,因此便有可能确定遗忘性质。然而,短短 10 天内(1987 年 12 月 23 日),我不得不抛弃全部的重复记录。当时,我的磁盘空间是 360KB,所以不得不如此。我在老式的 5.25 英寸软盘中运行 SuperMemo。经过 Janusz Murakowski 博士卓绝努力,记录完整重复历史的功能在 8 年后(1996 年 2 月 15 日)才回到 SuperMemo 中,他认为如果没有这项功能,每一分钟都是在浪费宝贵的数据,丢失未来算法和记忆研究的动力。20 年后,我们的数据多到处理不完。
没有重复历史,我仍然可以借助独立收集的遗忘曲线数据来研究遗忘问题。1991 年 1 月 6 日,我想出了在小文件中记录遗忘曲线的方法,这样数据库就不会过度膨胀(即没有重复历史的完整记录)。
直到 SuperMemo 6[5] 才开始收集遗忘曲线数据以确定最佳间隔时间(1991 年)。SuperMemo 6 所做的事情和我的第一个实验是一样的,只不过 SuperMemo 6 能够自动化,大规模地收集数据,并且记忆都已经分离成一个个问题(这就解决了异质性的问题)。SuperMemo 6 最初使用二分查找算法来寻找与遗忘指数相对应的最佳时刻。之后还要 3 年才能找出最优的近似。
第一条遗忘曲线的数据
到 1991 年 5 月,我有了首批一定量可供查看数据,然而我大失所望。我预测我需要一年的时间才能从数据中看到任何规律性。然而,每隔几个月,我都要要记录我对进展不足的失望。收集数据的进展缓慢得令人痛苦,漫长的等待难以忍受。一年后,我仍没有更多进展。如果艾宾浩斯能够用无意义的音节绘制出一条好的曲线,那么他忍受非连贯性[6]的痛苦一定是值得的。有了有意义的数据,真相就会得非常缓慢;尽管此时已有了电脑带来的便利,学习的过程也充满乐趣。
1992 年 9 月 3 日,适用于 Windows 的 SuperMemo 7 使人们有可能第一次很好地窥视到真正的遗忘曲线。这种景象令人陶醉:
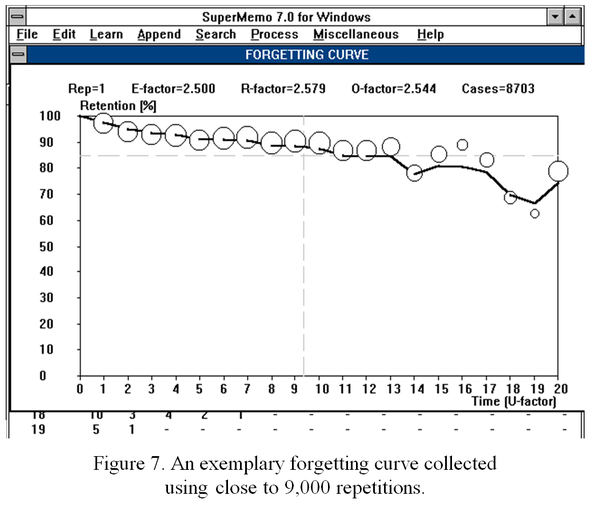
图:Windows 版 SuperMemo 7 编写于 1992 年。截至 1992 年 9 月 3 日,它能够显示用户的遗忘曲线图。标有 U-系数的横轴与这个特定图表中的天数相对应。第 14 天和第 20 天之间的奇怪弯曲是很难确定遗忘性质的原因之一。旧的错误假设很难被推翻。直到第 13 天,遗忘似乎几乎是线性的,也可能提供一个良好的指数拟合。我们又花了两年的时间收集数据,才最终找到答案(来源:《SuperMemo 7:用户指南》)
遗忘曲线近似
到 1994 年,我仍然不确定遗忘的性质。我汇集前三年(1991-1994 年)收集的数据,下定决心要一劳永逸地找出这条曲线。我把重点放在我自己的数据上,这些数据来自 20 多万次的重复。然而,这并不容易。如果 SuperMemo 将在 R=0.9 下安排重复,你可以从 R=1.0 到 R=0.9 画一条直线,这在未去干扰的数据中拟合得很好:
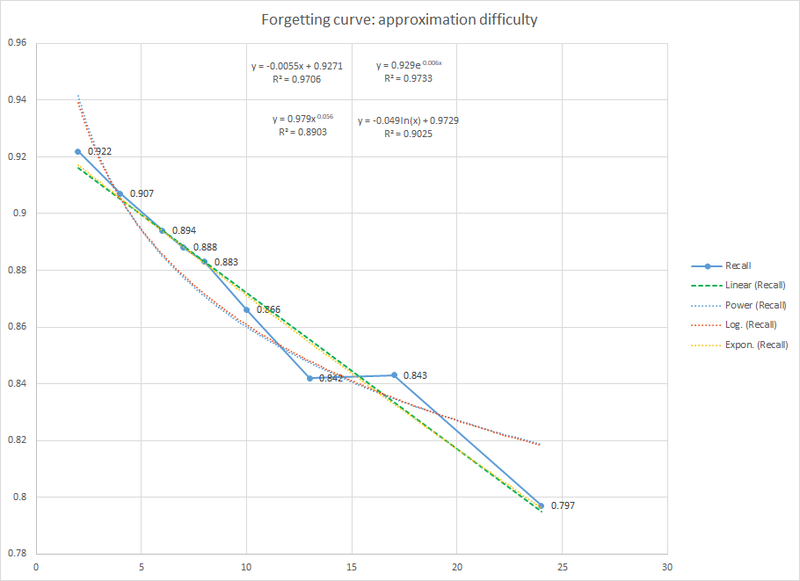
图:拟合遗忘曲线 的困难。在 1994 年,在 SuperMemo 中很难理解遗忘的本质,因为大多数数据都是在较高的回忆率范围内收集的
我在 1994 年 5 月 6 日的笔记说明了这种近似有多不确定:
个人轶事。为什么使用轶事?
1994 年 5 月 6 日。一整天都在疯狂地尝试更好地近似遗忘曲线。首先我尝试了,其中 i - 间隔时间,H - 记忆半衰期,n - 合作性系数。到了晚上,我慢慢地让它能工作起来了,但是......看来
的效果也差不了多少!即使是旧的线性近似也没有差很多(S 型 D=8.6%,指数 D=8.8%,而线性 D=10。8%)。也许,遗忘的曲线确实是指数型的?2 点 50 分睡觉。
要把线性、幂、指数、齐夫型、希尔型等等函数分开并不容易。一些难以区别的情况下,指数、幂甚至是线性近似带来了相当好的结果。为了更清楚地看到遗忘的指数性质,遗忘曲线数据需要有较高的的稳定性,且按复杂性排序好。即使这样的数据很少,观察得却更明白。
94 年中遇到了一个逻辑谬误是,大部分数据都是在第一次复习收集的。开始学习的新项目仍然是异质性集合,这个集合服从遗忘的指数规律。
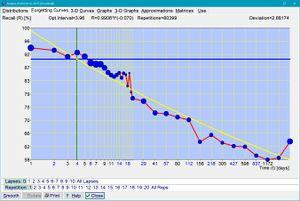
用 SuperMemo 收集的新学知识的第一次复习后的遗忘曲线
后来,当数据按复杂性和稳定性排序时,它们开始变得指数化。在SM-6 算法中,复杂性和稳定性分别由 E-系数 和重复次数来表达。这种表达并非尽善尽美,算法便有些瑕疵,最终排序也不完善。此外,当遗忘几乎是线性的时候,SuperMemo 仍然是高保留率的。
截至 1994 年 5 月,我的高级英语数据库中的主要初次复习曲线收集了 18000 个数据点,这些数据似乎是最好的分析材料。然而,这条曲线包含了所有进入这个过程的学习材料,与它的难度无关。我无从得知这条曲线由幂律掌控。我的最佳偏差是 2.0。
在 2018 年绘制的类似曲线可见:
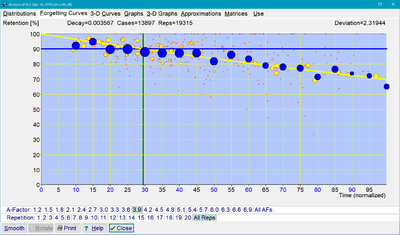
图:在 2018 年使用 SuperMemo 17 获得的平均难度(A-系数=3.9)下的遗忘曲线。其数据包含 19,315 次重复,最小二乘法偏差为 2.319,而这条曲线与 1994 年的曲线极为相似,只是它用指数函数来近似最好(幂函数的例子可参见:遗忘曲线
指数式遗忘胜出
到 1994 年夏天,我足够确信遗忘是指数的。到 1995 年,我们发表了《记忆的两个组成部分》[7],其中有公式 R=exp(-t/S)。我们的出版物在很大程度上仍然被主流科学所忽视,但网上一提到遗忘曲线,便屡屡提及我们的作品。
有趣的是,在 1966 年,诺贝尔奖得主赫伯特-西蒙对艾宾浩斯在 1897 年的工作中得出的约斯特定律[8]简单做了研究。西蒙注意到,遗忘的指数性质说明记忆必然具备某种属性,今天我们称这种属性为记忆稳定性。西蒙就此写了篇简短的论文,之后就转头研究他手上的数百个其他项目了。这篇小文基本上被人遗忘了,然而,它是预言性的。1988 年,类似的推理是长期记忆的两个组成部分模型[7]的想法起源。
今天,关于指数特点的遗忘,我们还有一点推论。如果遗忘是指数级的,就意味着在单位时间内遗忘的概率是恒定的,这意味着神经网络干扰[9],也就意味着睡眠可能不是通过加强记忆来建立稳定性,而是通过简单地消除干扰的原因:多余的突触。那么朱利奥-托诺尼认为睡眠中净损失突触的看法可能是正确的。然而,他认为这种损失是正常的。指数式遗忘表明此中更有深意。它可能是一种「智能遗忘[10]」,这种遗忘干扰了在清醒时强化的关键记忆。
负指数的遗忘曲线
直到 2005 年,关于遗忘的指数性质才有了更多文章。在 Gorzelanczyk 博士于一个波兰建模会议上发表的论文中,我们写道:
存档警告:为什么使用文字档案?
尽管人们一直推测遗忘在本质上是指数式的,但证明这一事实从来都不容易。从放射性衰变到脱水中的木材,指数衰减在生物和物理系统中屡屡现身。这个模型出现在任何预期衰变率与样本大小成正比,而且单粒子以恒定概率衰变的地方。自艾宾浩斯(Ebbinghaus, 1885)的年代以来,以下问题阻碍了遗忘建模:
- 样本量小
- 样本异质性
- 混淆了遗忘曲线、再学习曲线、练习曲线、保留曲线、试验学习曲线、错误曲线以及学习曲线族中的其他曲线
通过 SuperMemo,我们可以克服所有这些障碍来研究记忆衰减的本质。作为一个流行的商业应用程序,SuperMemo从世界各地的学生收集了大量的数据,并能非常自由地访问这些数据。该程序的每个用户都可以得到的遗忘曲线图(工具:统计:分析:遗忘曲线)是基于同质性较强的样本绘制的,因而是对记忆衰减的真正反映(相对于其他形式的学习曲线)。不过,对异质性的追求大大影响了样本的大小。值得注意的是,遗忘曲线对于不同记忆稳定性,和不同知识难度的材料是不同的。而记忆稳定性会影响衰减率,异质性学习材料使得遗忘曲线互相叠加,每条曲线衰减率不同。因此,即使在有几十万个单独信息参与学习过程的机构中,也只能过滤出相对较小的同质化数据样本。这些样本大小很少超过几千。即使如此,这些数据在质量上也远远胜过研究人员在受控条件下研究记忆特性的样本。然而,遗忘的随机性仍然使得我们很难对衰减函数的数学性质做出最终的判断(见下面两个例子)。在分析了几十万个样本后,我们非常接近于说明记忆是一种指数衰减。
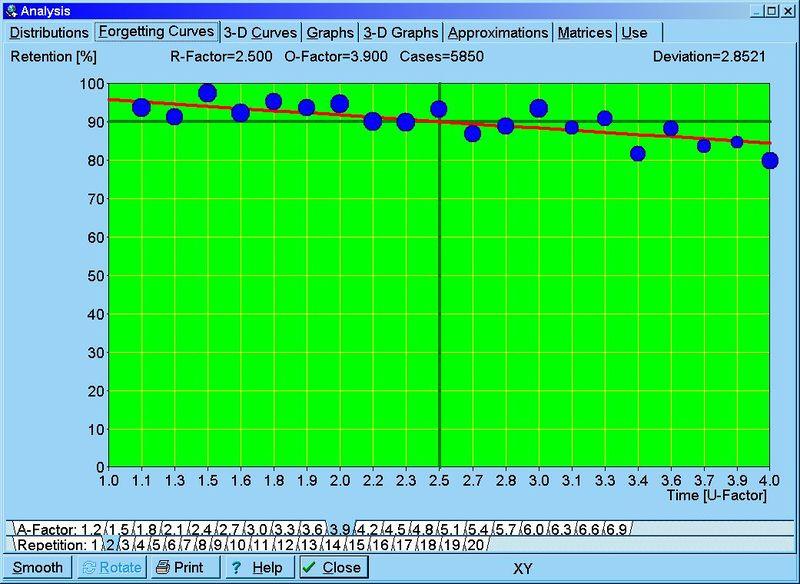
图:由 SuperMemo 画出的示范性遗忘曲线。从数据库中近一百万个重复案例样本里,找出平均难度和低稳定性(A-系数=3.9,S 在 [4,20])的数据,最终得到 5850 个重复案例(不到整个样本的 1%)。红线是回归分析的结果,R=e-kt/S。用其他基本函数进行曲线拟合,表明指数衰减最能契合数据。图中使用的时间量度是所谓的 U-系数,其定义为现在和以前的重复间隔的比值。请注意,在 R 处于 1 到 0.9 的范围时,指数衰减可以合理地用一条直线来近似,而衰减若用幂函数刻画的话就并非如此。
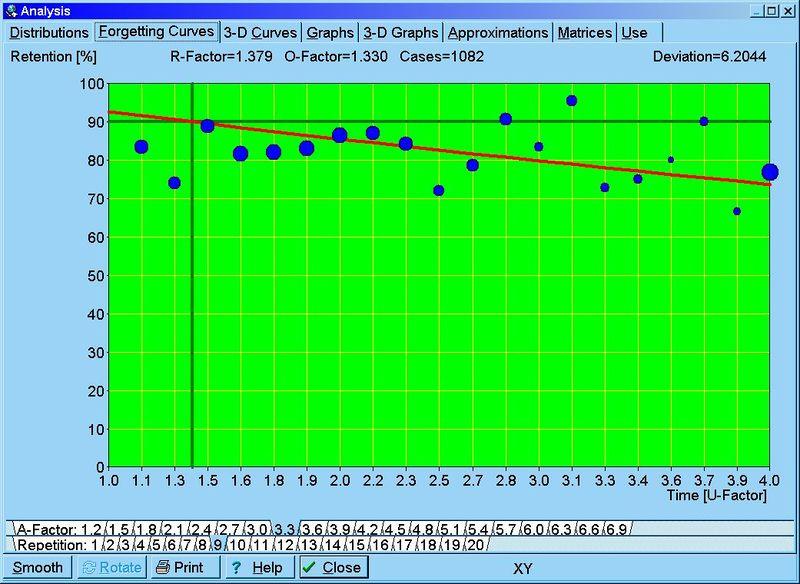
图:由 SuperMemo 画出的示范性遗忘曲线。从数据库中的近百万个重复案例筛选出平均难度和中等稳定性(A-系数=3.3,S>1 年)的案例,最终得到了 1082 个。红线是按照 R=e-kt/S 回归分析的结果。
遗忘曲线:可提取性公式
在 SM-17 算法 中,可提取性 R与回忆的概率相对应,并代表指数式遗忘曲线。可提取性是由稳定性和间隔得出的:
R[n]:=exp-k*t/S[n-1]
其中:
如果有项目很难或者项目难度不一的话,遗忘曲线就不是完全指数性质的,这种整洁的理论方法就变得有点复杂了。此外,SuperMemo 中的遗忘曲线可能会因为用户策略而出现瑕疵。
在 SM-8 算法 中,我们希望可提取性信息可以利用评分计算出。实际上实现不了。评分和可提取性之间的相关性很小,这主要是因为,复杂项目的评分更差,而且往往被遗忘得更快(至少在开始时)。
保留率与遗忘指数的关系
遗忘的指数性质意味着,测量的遗忘指数和知识保留之间的关系可以用以下公式准确表达:
Retention = -FI/ln(1-FI)
其中:
例如,默认设定中,执行良好的间隔重复下,遗忘指数设为 0.1(即10%)时,保留率应该是 0.949(即 94.9%)。94.9% 这个数据说明,一开始指数衰减和线性函数极为相似。对于线性遗忘,保留率是 95.000%(即 100% 减去遗忘指数的一半)。
劣质材料的遗忘曲线
1994 年,我的学习集基本上都有很好的表述,因此我很幸运。而 SuperMemo 的用户往往不是这样的。对于表述质量差的项目 来说,遗忘曲线是扁平化的,而不是纯粹的指数型(如几个指数型曲线的叠加)。SuperMemo 永远无法预测某个项目在哪个时刻遗忘。遗忘是随机过程,只有其平均值才能计算。有一个流传甚广的 SuperMemo 谬论是,SuperMemo 可以预测遗忘的确切时刻:这不是真的,也不可能。SuperMemo 所做的是寻找一些间隔,在这些间隔内,给定项目难度,遗忘概率很可能为特定的值(例如 10%)。那些扁平化的遗忘曲线引发了一个悖论。忽略复杂项目后,即使长期中断复习,也可能记住很多材料。即使是纯粹的负指数遗忘曲线,区间估计的 10 倍偏差也会导致 R2=exp10*ln(R1) 差异的保留率差异。这相当于从 98% 下降到 81%。对于典型的劣质项目的扁平化遗忘曲线,这个下降可能只有 98%->95%。这就说明将复杂的材料保持在较低的优先级是好的学习策略。
幂律出现在指数遗忘曲线的叠加中
为了说明同质样本对于研究遗忘曲线的重要性,让我们看看将困难的知识与容易的知识混合后,遗忘曲线形状如何变化。下列图表说明,为什么利用异质样本可能得出遗忘性质的错误结论。本演示中的异质样本甚至用幂函数来近似是最优的!幂函数来自于指数型遗忘曲线的平均化,这一事实早先已经有其他记载(Anderson&Tweney 1997;Ritter&Schooler, 2002)。

图:遗忘曲线的叠加可能导致遗忘的指数性质被掩盖。考虑由两种类型记忆组合成的样本: 50% 的记忆稳定性为 S=1 (细黄线),50% 的记忆稳定性为 S=40 (细紫线)。叠加的遗忘曲线自然会表现出可提取性。这样一个复合样本的遗忘曲线在图中以黑点描出。蓝色粗线表示指数近似值(R2=0.895),红色粗线表示同一曲线的幂近似值(R2=0.974)。在这种情况下,幂函数最契合数据,尽管样本子集的遗忘是负指数式的。
SuperMemo 17 还包括一条最适合用幂函数近似的遗忘曲线。这是记忆项目后的第一条遗忘曲线。在记忆的时候,我们不知道项目的复杂性这一概念。这就是为什么材料是异质性的,而遗忘曲线是幂函数近似的。
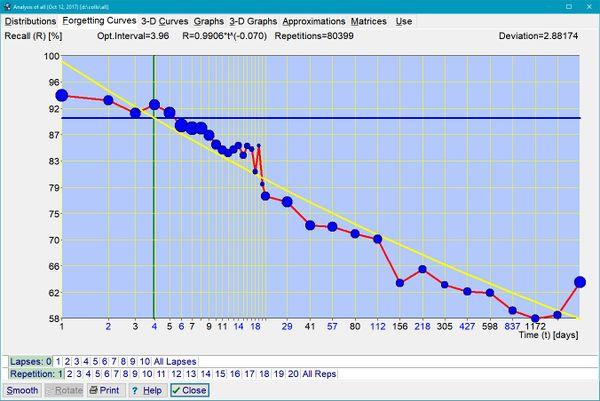
图:第一条遗忘曲线,数据来自新学知识,用 SuperMemo 收集。由于学习过程中新引入的学习材料是异质的,因此使用了幂函数近似。项目未按照记忆复杂性[11]区分,结果图线为衰减常数不同的指数型遗忘的叠加。在半对数图上,幂函数回归曲线是对数的(黄色),而且看起来几乎是直线。曲线显示,在所提出的案例中,回忆率在四年内仅仅下降到 58%,可以归功于所记忆的知识在现实生活中经历了多次使用。在可提取性为 90% 的情况下,复习的第一个最优间隔是 3.96 天。遗忘曲线可以用公式 R=0.9906*power(interval,-0.07) 来描述,其中 0.9906 是一天后的回忆率,而 -0.07 是衰减常数。在这种情况下,由该公式可得出 4 天后回忆率为 90% 。本图线使用了 80,399 次重复来绘制。如果材料中困难知识较高比例(尤其是表述不清的知识[12]),或者是学生初次接触,助记能力较差,回忆率会较大幅度地下降。间隔 15-20 处曲线较不规则,这是因为重复样本数量不够(在对数表上后来的间隔类别包含了更大的间隔范围)
总目录:0 目录《间隔重复的历史》
上一章:08 1991:启用遗忘曲线
Thoughts Memo 汉化组译制
原文:History of spaced repetition (print) - supermemo.guru
参考
1. 艾宾浩斯遗忘曲线的错误 ./156672476.html2. 1990:记忆的通用公式 ./429504395.html
3. 1985:SuperMemo 的诞生 ./95111167.html
4. SuperMemo 1.0: 日志 (1987) ./97887756.html
5. 1991:启用遗忘曲线 ./441532847.html
6. 一致性与连贯性(Consistency vs Coherence) ./264327134.html
7. 1988:记忆的两个组成成分 ./99505568.html
8. 约斯特定律 ./401155017.html
9. 干扰 ./269974053.html
10. 睡眠中的记忆优化 ./266856783.html
11. 记忆复杂性 ./304800091.html
12. 20 条知识表述规则(20 周年版) ./269997143.html